Observability for IBM watsonx with Opik
watsonx is a next generation enterprise studio for AI builders to train, validate, tune and deploy AI models.
Account Setup
Comet provides a hosted version of the Opik platform, simply create an account and grab your API Key.
You can also run the Opik platform locally, see the installation guide for more information.
Getting Started
Installation
To start tracking your watsonx LLM calls, you can use our LiteLLM integration. You’ll need to have both the opik and litellm packages installed. You can install them using pip:
Configuring Opik
Configure the Opik Python SDK for your deployment type. See the Python SDK Configuration guide for detailed instructions on:
- CLI configuration:
opik configure - Code configuration:
opik.configure() - Self-hosted vs Cloud vs Enterprise setup
- Configuration files and environment variables
If you’re unable to use our LiteLLM integration with watsonx, please open an issue
Configuring watsonx
In order to configure watsonx, you will need to have:
- The endpoint URL: Documentation for this parameter can be found here
- Watsonx API Key: Documentation for this parameter can be found here
- Watsonx Token: Documentation for this parameter can be found here
- (Optional) Watsonx Project ID: Can be found in the Manage section of your project.
Once you have these, you can set them as environment variables:
Logging LLM calls
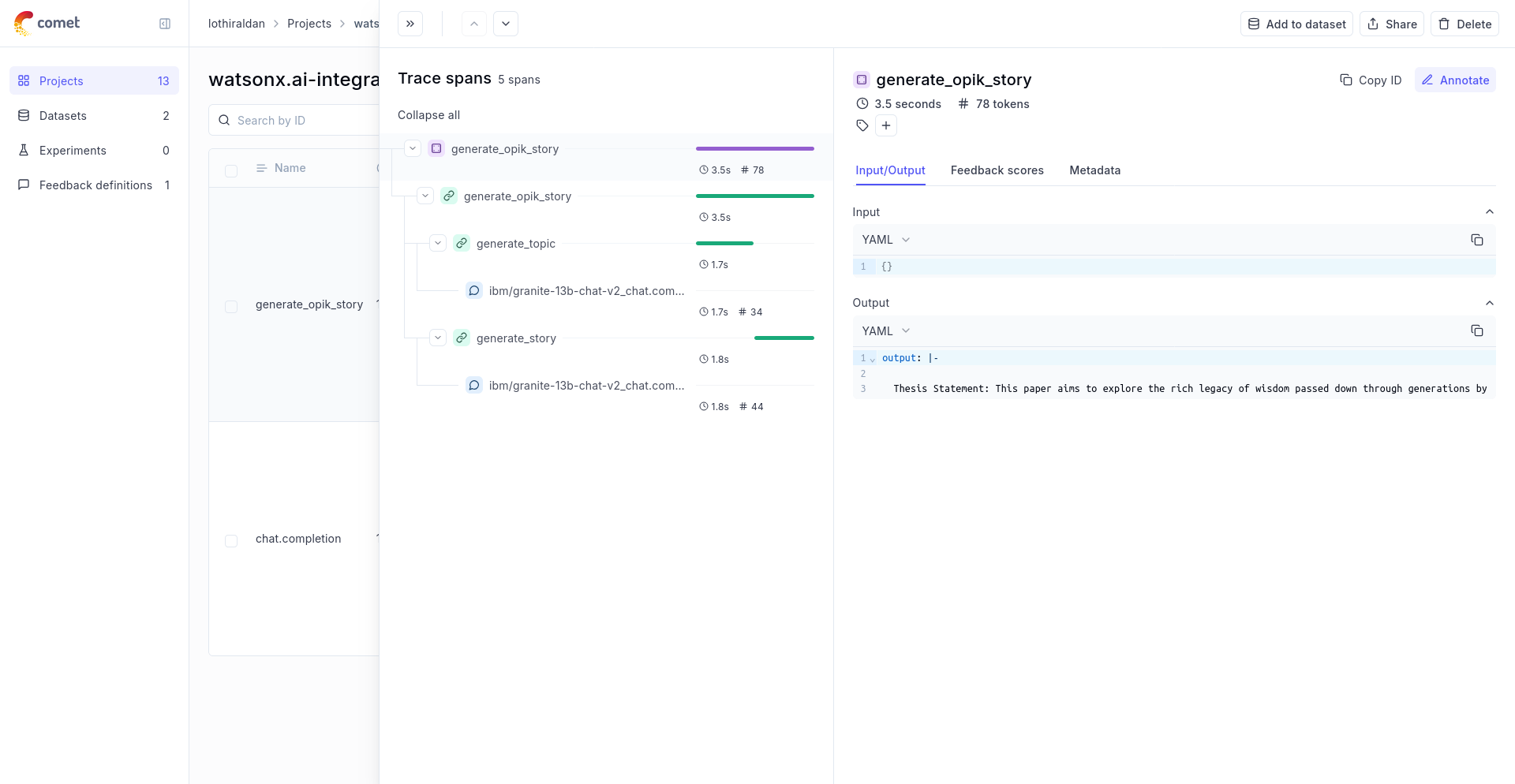
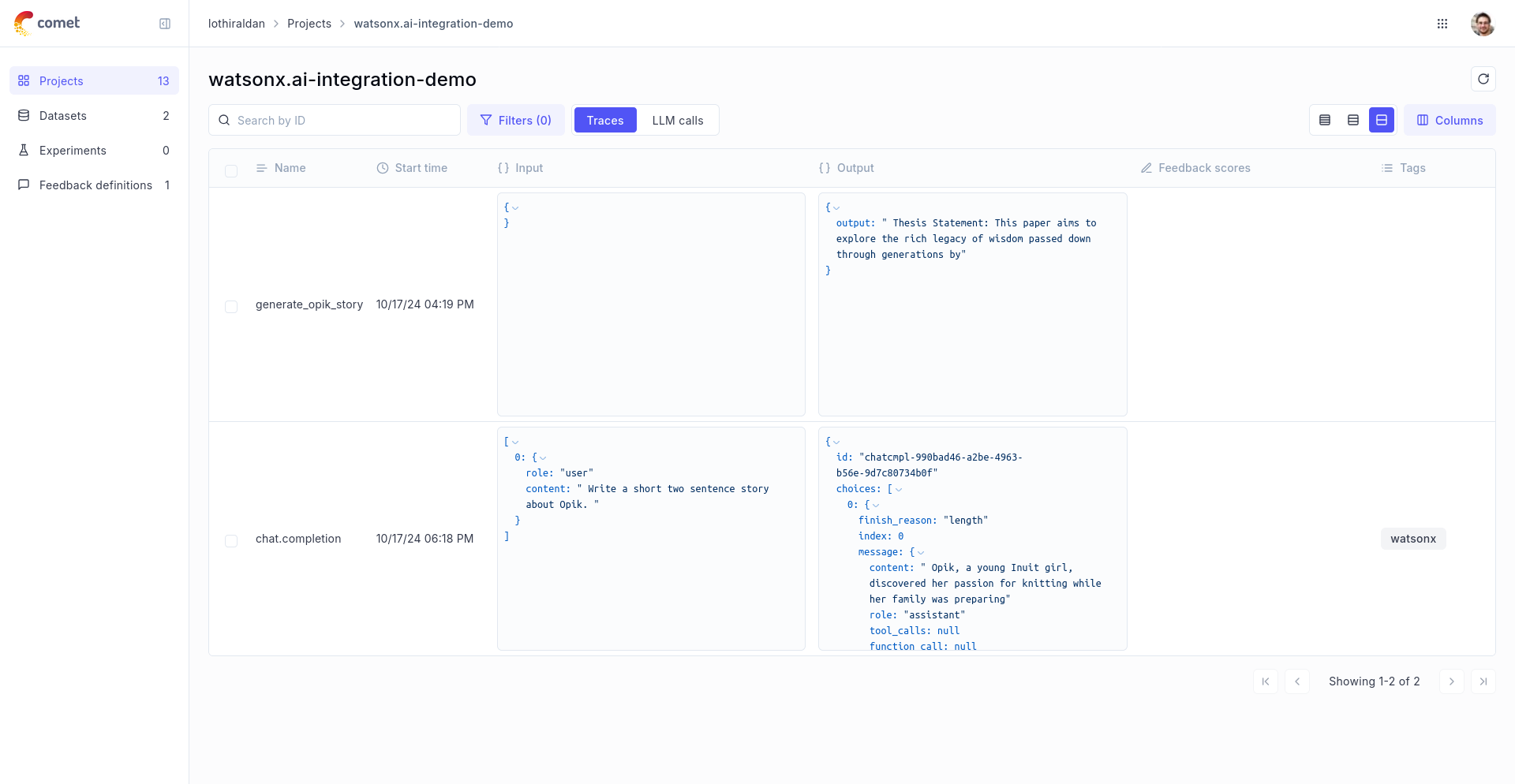
In order to log the LLM calls to Opik, you will need to create the OpikLogger callback. Once the OpikLogger callback is created and added to LiteLLM, you can make calls to LiteLLM as you normally would:
Advanced Usage
Using with the @track decorator
If you have multiple steps in your LLM pipeline, you can use the @track decorator to log the traces for each step. If WatsonX is called within one of these steps, the LLM call will be associated with that corresponding step: