Concepts
If you want to jump straight to running evaluations, you can head to the Evaluate prompts or Evaluate your LLM application guides.
When working with LLM applications, the bottleneck to iterating faster is often the evaluation process. While it is possible to manually review your LLM application’s output, this process is slow and not scalable. Instead of manually reviewing your LLM application’s output, Opik allows you to automate the evaluation of your LLM application.
In order to understand how to run evaluations in Opik, it is important to first become familiar with the concepts of:
- Dataset: A dataset is a collection of samples that your LLM application will be evaluated on. Datasets only store the input and expected outputs for each sample, the output from your LLM application will be computed and scored during the evaluation process.
- Experiment: An experiment is a single evaluation of your LLM application. During an experiment, we process each dataset item, compute the output based on your LLM application and then score the output.
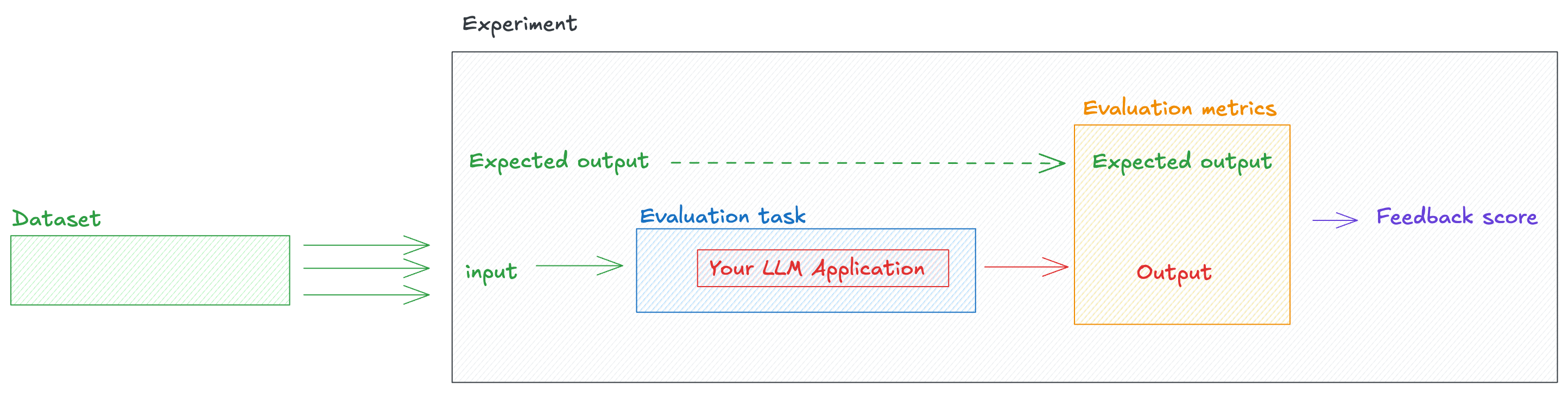
In this section, we will walk through all the concepts associated with Opik’s evaluation platform.
Datasets
The first step in automating the evaluation of your LLM application is to create a dataset which is a collection of samples that your LLM application will be evaluated on. Each dataset is made up of Dataset Items which store the input, expected output and other metadata for a single sample.
Given the importance of datasets in the evaluation process, teams often spend a significant amount of time curating and preparing their datasets. There are three main ways to create a dataset:
-
Manually curating examples: As a first step, you can manually curate a set of examples based on your knowledge of the application you are building. You can also leverage subject matter experts to help in the creation of the dataset.
-
Using synthetic data: If you don’t have enough data to create a diverse set of examples, you can turn to synthetic data generation tools to help you create a dataset. The LangChain cookbook has a great example of how to use synthetic data generation tools to create a dataset.
-
Leveraging production data: If your application is in production, you can leverage the data that is being generated to augment your dataset. While this is often not the first step in creating a dataset, it can be a great way to enrich your dataset with real world data.
If you are using Opik for production monitoring, you can easily add traces to your dataset by selecting them in the UI and selecting
Add to datasetin theActionsdropdown.
You can learn more about how to manage your datasets in Opik in the Manage Datasets section.
Experiments
Experiments are the core building block of the Opik evaluation platform. Each time you run a new evaluation, a new experiment is created. Each experiment is made up of two main components:
- Experiment Configuration: The configuration object associated with each experiment allows you to track some metadata, often you would use this field to store the prompt template used for a given experiment for example.
- Experiment Items: Experiment items store the input, expected output, actual output and feedback scores for each dataset sample that was processed during an experiment.
In addition, for each experiment you will be able to see the average scores for each metric.
You can update an experiment’s name and configuration at any time from the Opik UI or through the SDKs. Learn more in the Update Existing Experiment guide.
Experiment Configuration
One of the main advantages of having an automated evaluation platform is the ability to iterate quickly. The main drawback is that it can become difficult to track what has changed between two different iterations of an experiment.
The experiment configuration object allows you to store some metadata associated with a given experiment. This is useful for tracking things like the prompt template used for a given experiment, the model used, the temperature, etc.
You can then compare the configuration of two different experiments from the Opik UI to see what has changed.
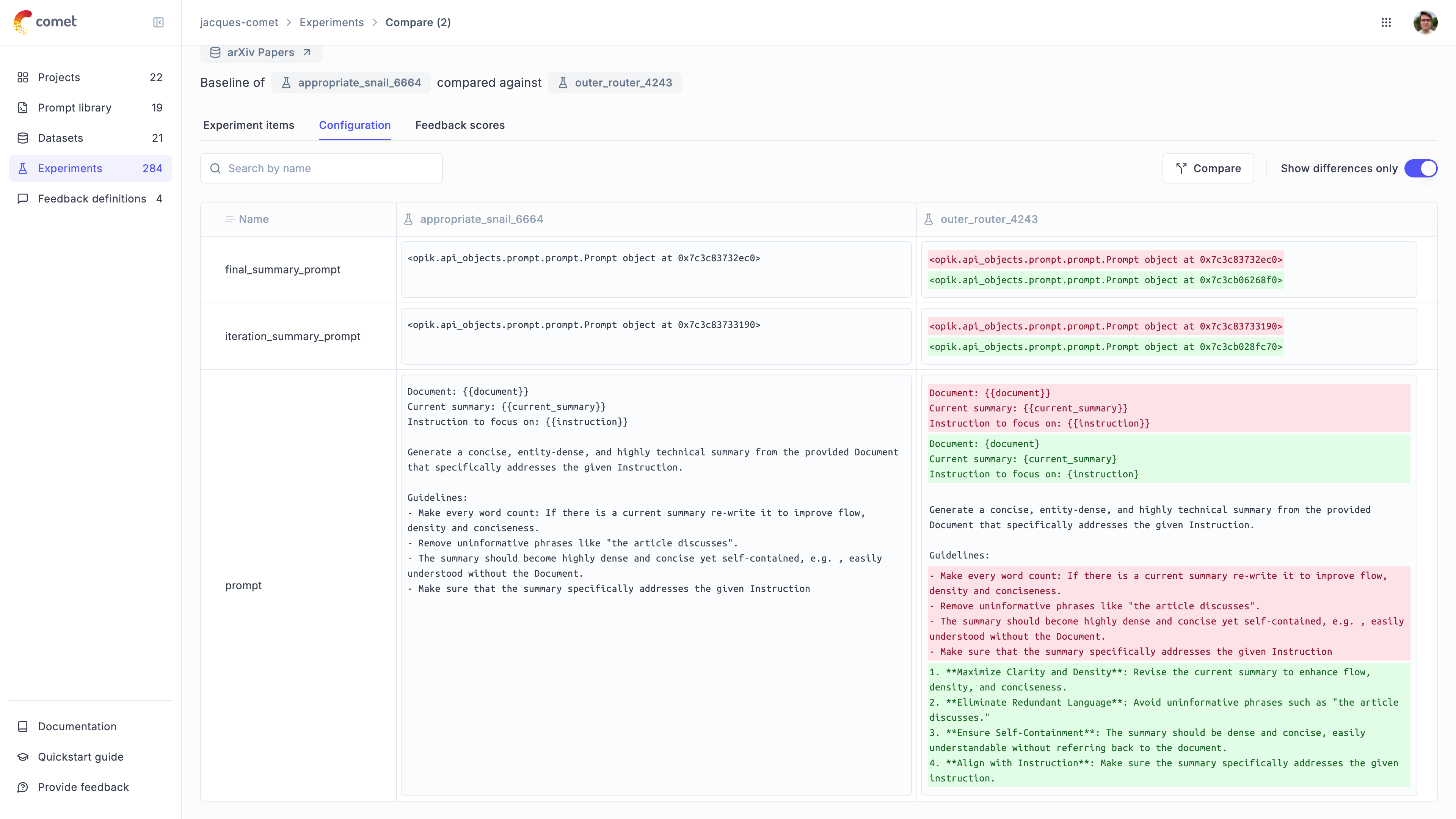
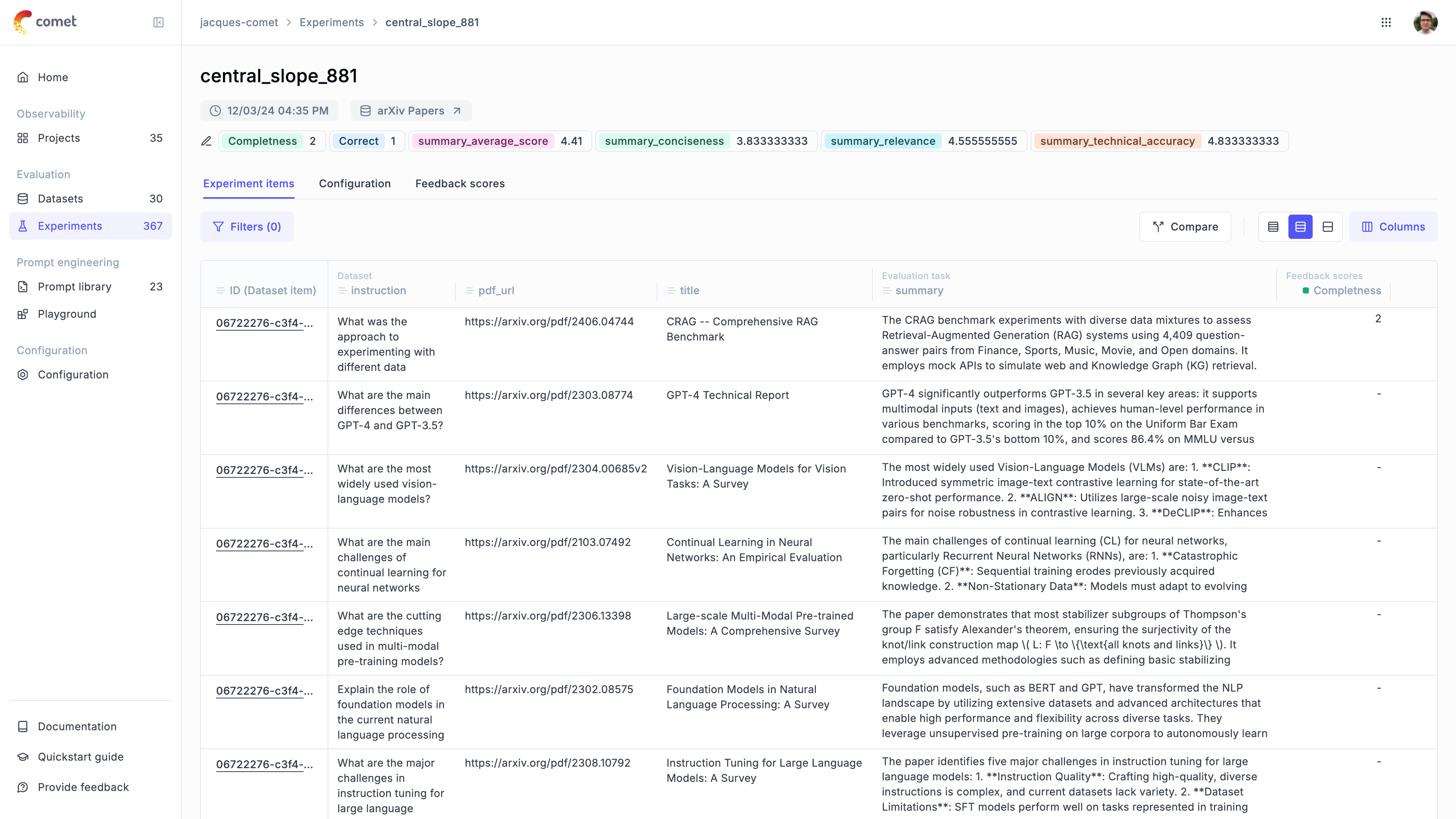
Experiment Items
Experiment items store the input, expected output, actual output and feedback scores for each dataset sample that was processed during an experiment. In addition, a trace is associated with each item to allow you to easily understand why a given item scored the way it did.
Experiment-Level Metrics
In addition to per-item metrics, you can compute experiment-level aggregate metrics that are calculated across all test results. These experiment scores are displayed in the Opik UI alongside feedback scores and can be used for sorting and filtering experiments.
Experiment scores are computed after all test results are collected using custom functions that take a list of test results and return aggregate metrics. Common use cases include computing maximum, minimum, or mean values across all test cases, or calculating custom statistics specific to your evaluation needs.
Learn more about how to compute experiment-level metrics in the Evaluate your LLM application guide.
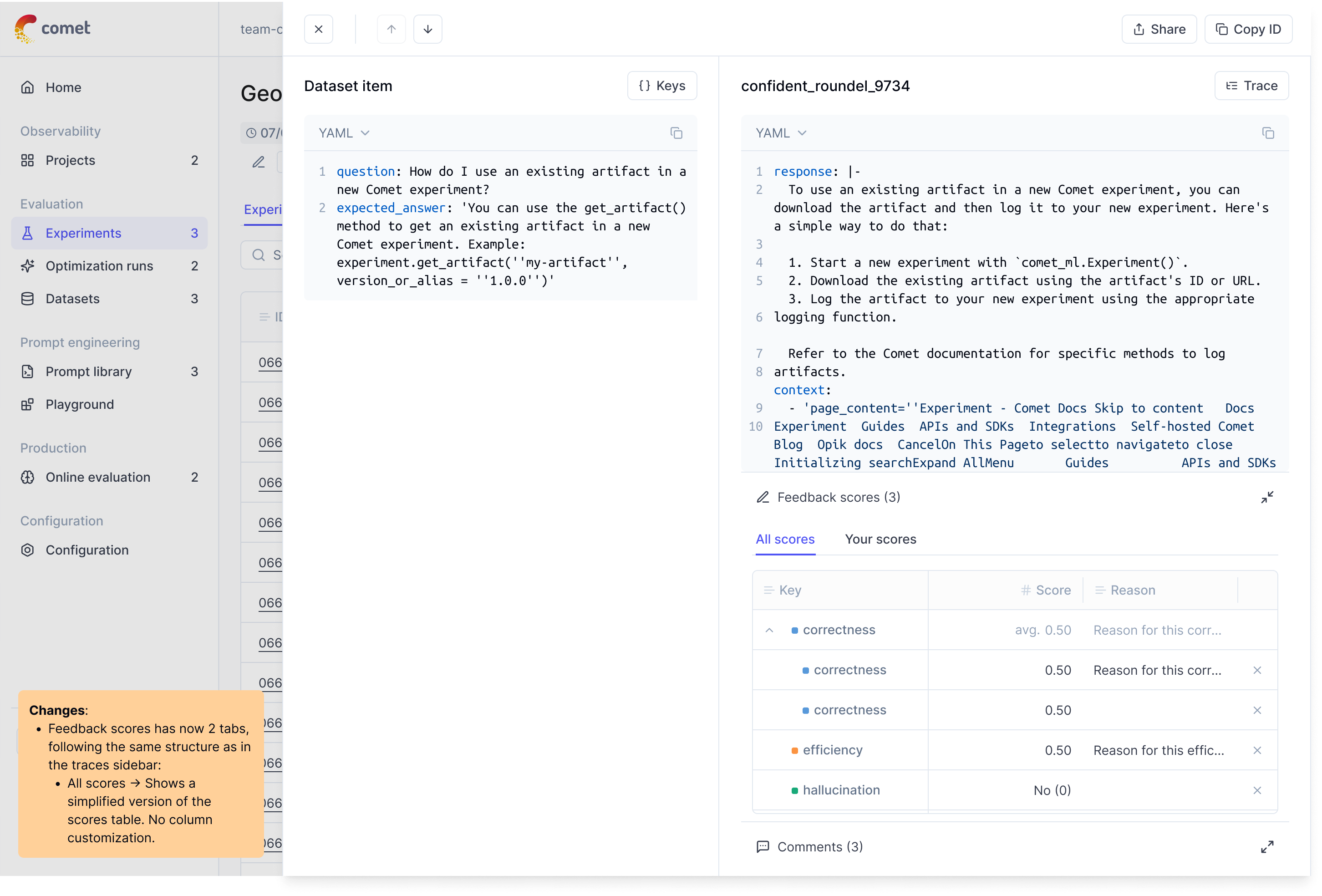
Multi-Value Feedback Scores for Experiment Items
The experiment interface supports multiple evaluators scoring the same experiment items. Each item can receive independent scores from different team members, with all ratings preserved and aggregated in the interface.
Interface Features
- Score overlay: Hover over any score to see individual scores, reasons, and aggregates
- Evaluator tracking: Each score shows who provided it, when, and their reasoning
- Reason display: View individual explanations alongside each score
- Statistical summary: View mean, standard deviation, and score distribution
Evaluation Workflow
- Initial scoring: First evaluator scores experiment items with optional reasoning
- Additional evaluation: Other team members add their scores and explanations to the same items
- Aggregate calculation: Interface automatically computes means and variance metrics
- Analysis tools: Use built-in charts to identify high-disagreement items and compare
- Consensus review: Discuss items with high score variance using individual explanations to align criteria
This approach helps identify experiment items where evaluators disagree significantly, with access to individual reasoning to understand why disagreements occurred and improve evaluation consistency.
Learn more
We have provided some guides to help you get started with Opik’s evaluation platform: