Evaluate single prompts
When developing prompts and performing prompt engineering, it can be challenging to know if a new prompt is better than the previous version.
Opik Experiments allow you to evaluate the prompt on multiple samples, score each LLM output and compare the performance of different prompts.
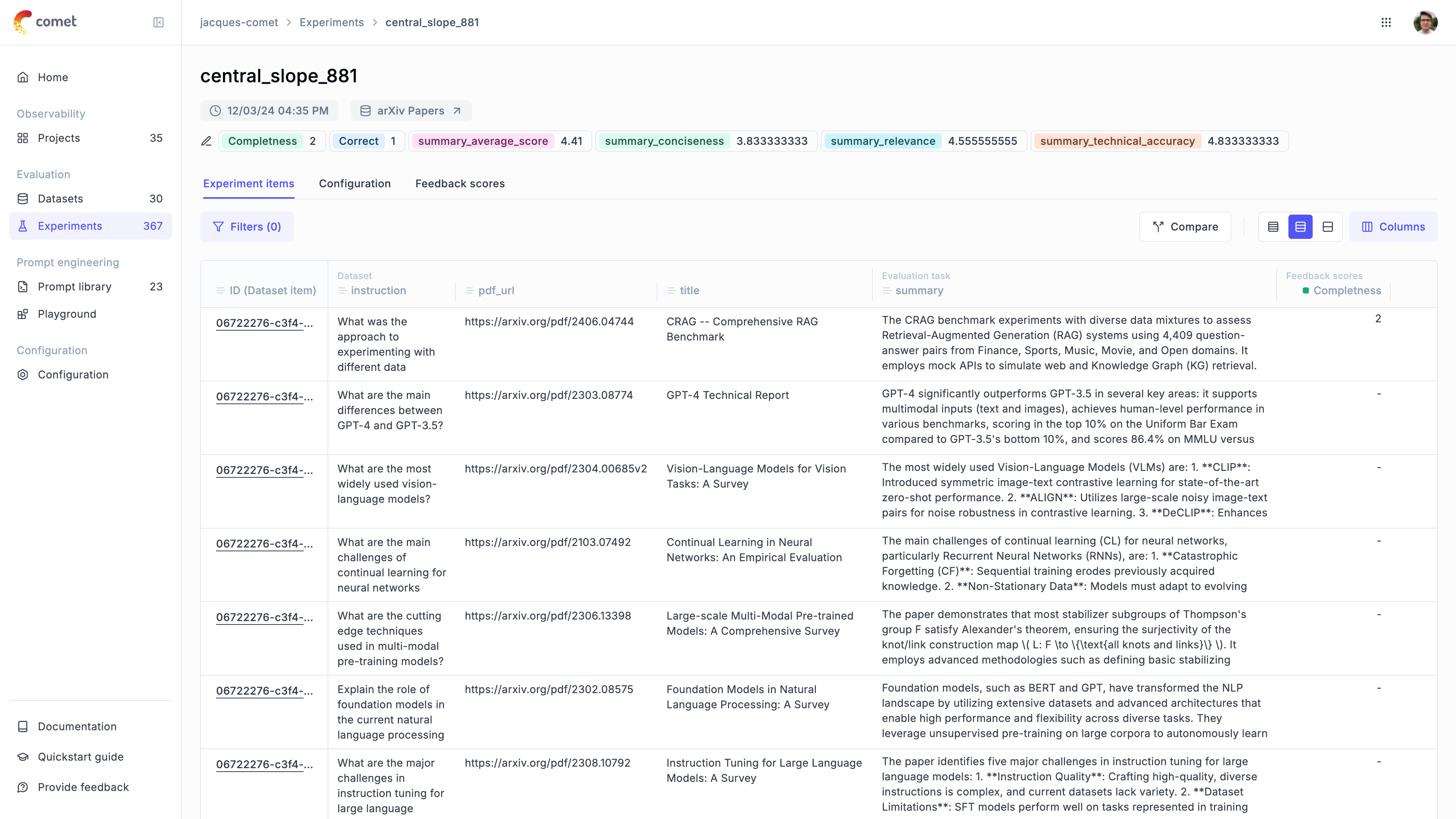
There are two way to evaluate a prompt in Opik:
- Using the prompt playground
- Using the
evaluate_promptfunction in the Python SDK
Using the prompt playground
The Opik playground allows you to quickly test different prompts and see how they perform.
You can compare multiple prompts to each other by clicking the + Add prompt button in the top
right corner of the playground. This will allow you to enter multiple prompts and compare them side
by side.
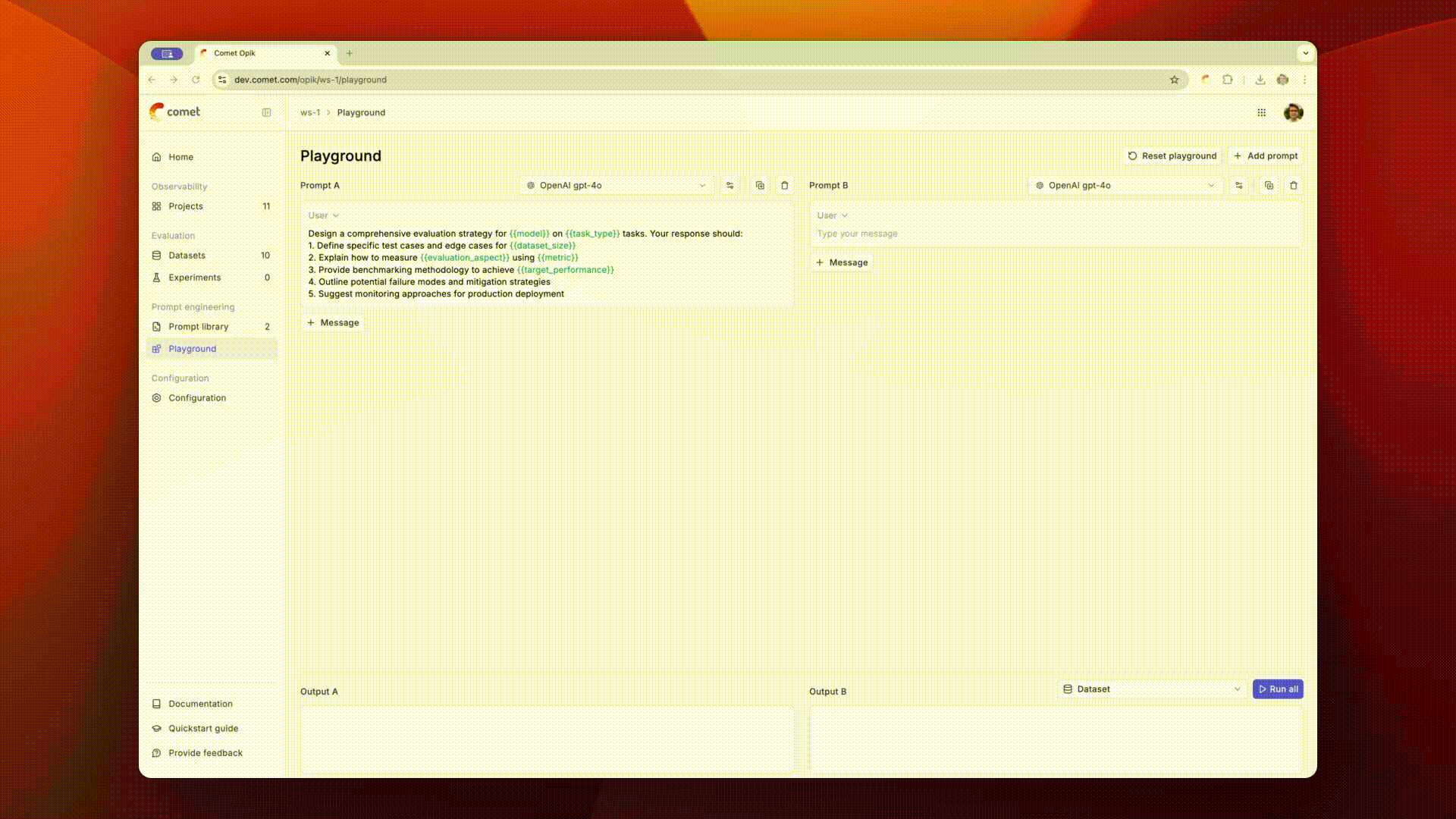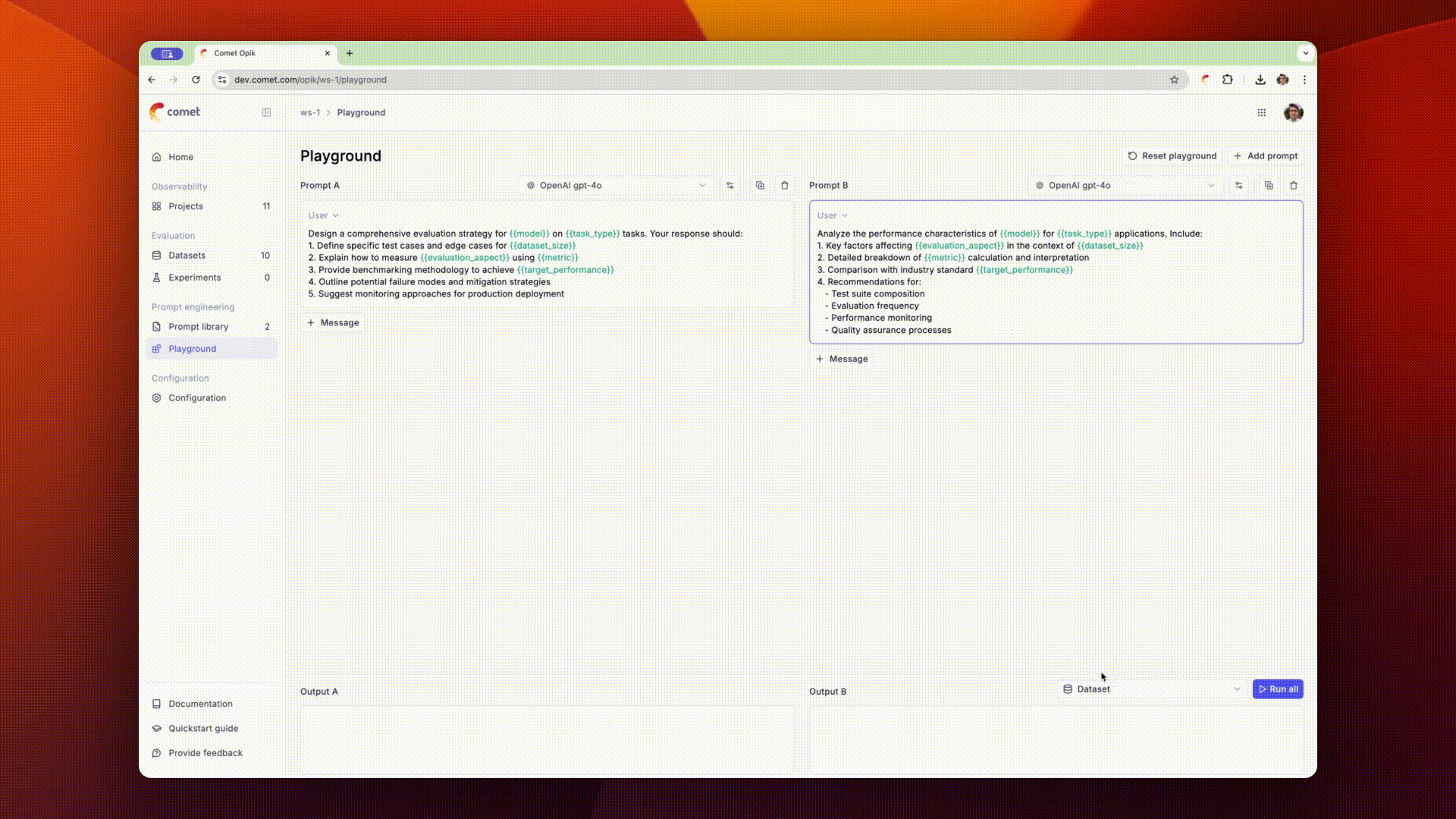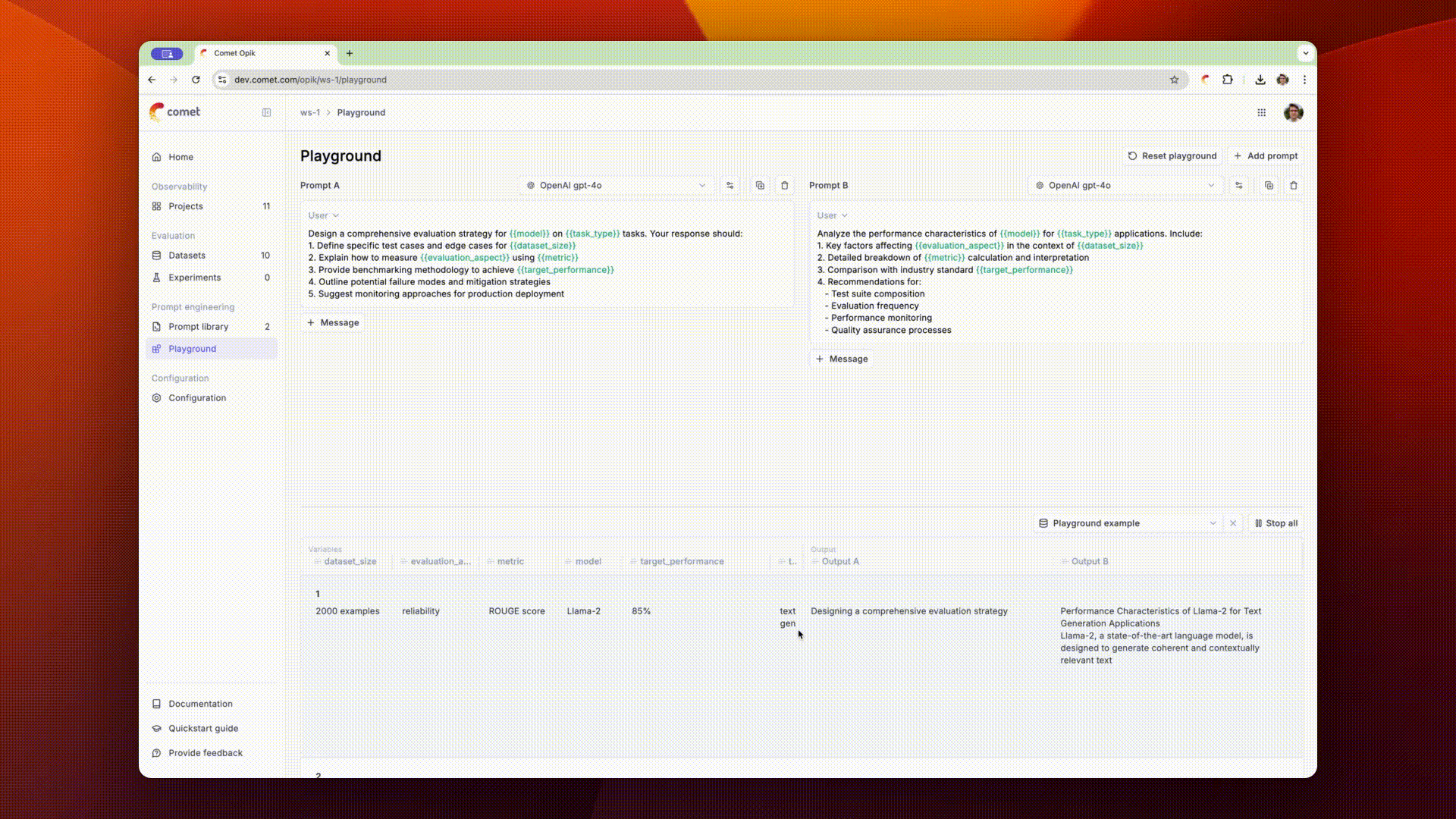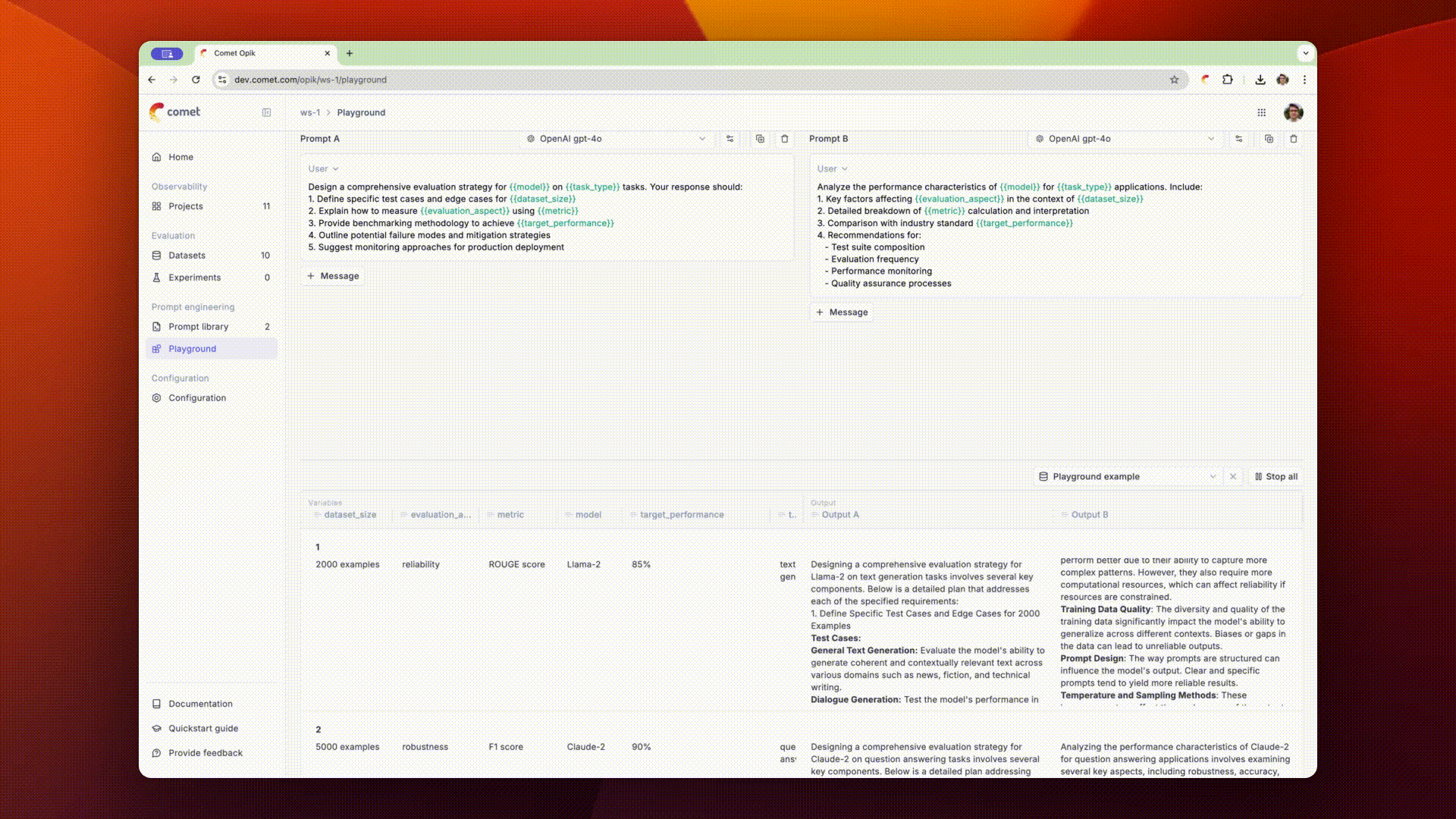
In order to evaluate the prompts on samples, you can add variables to the prompt messages using the
{{variable}} syntax. You can then connect a dataset and run the prompts on each dataset item.
Programmatically evaluating prompts
The Opik SDKs provide a simple way to evaluate prompts using the evaluate prompt methods. This
method allows you to specify a dataset, a prompt and a model. The prompt is then evaluated on each
dataset item and the output can then be reviewed and annotated in the Opik UI.
To run the experiment, you can use the following code:
Once the evaluation is complete, you can view the responses in the Opik UI and score each LLM output.
Automate the scoring process
Manually reviewing each LLM output can be time-consuming and error-prone. The evaluate_prompt
function allows you to specify a list of scoring metrics which allows you to score each LLM output.
Opik has a set of built-in metrics that allow you to detect hallucinations, answer relevance, etc
and if we don’t have the metric you need, you can easily create your own.
You can find a full list of all the Opik supported metrics in the Metrics Overview section or you can define your own metric using Custom Metrics section.
By adding the scoring_metrics parameter to the evaluate_prompt function, you can specify a list
of metrics to use for scoring. We will update the example above to use the Hallucination metric
for scoring:
Customizing the model used
You can customize the model used by create a new model using the LiteLLMChatModel class. This supports passing additional parameters to the model like the temperature or base url to use for the model.
Filtering dataset items
You can evaluate only a subset of your dataset items by using the dataset_filter_string parameter. This is useful when you want to run experiments on specific categories of data:
The filter uses Opik Query Language (OQL) syntax. For more details on filter syntax and supported columns, see Filtering syntax.
Next steps
To evaluate complex LLM applications like RAG applications or agents, you can use the evaluate function.
You can also compute experiment-level aggregate metrics when evaluating prompts using the experiment_scoring_functions parameter.
Learn more about experiment-level metrics.