Online Evaluation rules
Online evaluation metrics allow you to score all your production traces and easily identify any issues with your production LLM application.
When working with LLMs in production, the sheer number of traces means that it isn’t possible to manually review each trace. Opik allows you to define LLM as a Judge metrics that will automatically score the LLM calls logged to the platform.
By defining LLM as a Judge metrics that run on all your production traces, you will be able to automate the monitoring of your LLM calls for hallucinations, answer relevance or any other task specific metric.
Defining scoring rules
Scoring rules can be defined through both the UI and the REST API.
To create a new scoring metric in the UI, first navigate to the project you would like to monitor. Once you have navigated to the rules tab, you will be able to create a new rule.
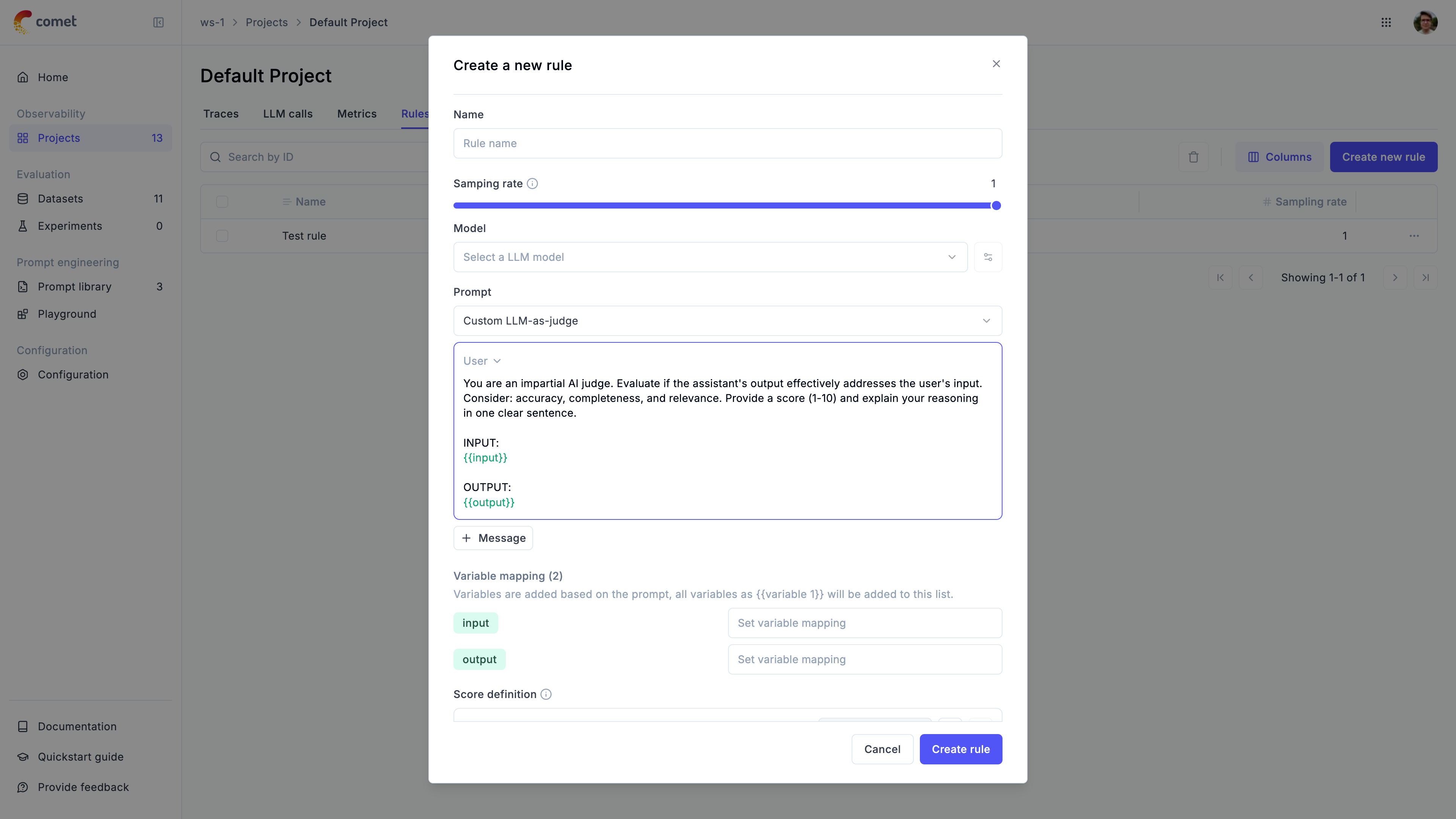
When creating a new rule, you will be presented with the following options:
- Name: The name of the rule
- Sampling rate: The percentage of traces to score. When set to
100%, all traces will be scored. - Model: The model to use to run the LLM as a Judge metric. For evaluating traces with images, make sure to select a model that supports vision capabilities.
- Prompt: The LLM as a Judge prompt to use. Opik provides a set of base prompts (Hallucination, Moderation, Answer Relevance) that you can use or you can define your own. Variables in the prompt should be in
{{variable_name}}format. - Variable mapping: This is the mapping of the variables in the prompt to the values from the trace.
- Score definition: This is the format of the output of the LLM as a Judge metric. By adding more than one score, you can define LLM as a Judge metrics that score an LLM output along different dimensions.
Opik’s built-in LLM as a Judge metrics
Opik comes pre-configured with 3 different LLM as a Judge metrics:
- Hallucination: This metric checks if the LLM output contains any hallucinated information.
- Moderation: This metric checks if the LLM output contains any offensive content.
- Answer Relevance: This metric checks if the LLM output is relevant to the given context.
If you would like us to add more LLM as a Judge metrics to the platform, do raise an issue on GitHub and we will do our best to add them !
Writing your own LLM as a Judge metric
Opik’s built-in LLM as a Judge metrics are very easy to use and are great for getting started. However, as you start working on more complex tasks, you may need to write your own LLM as a Judge metrics.
We typically recommend that you experiment with LLM as a Judge metrics during development using Opik’s evaluation platform. Once you have a metric that works well for your use case, you can then use it in production.
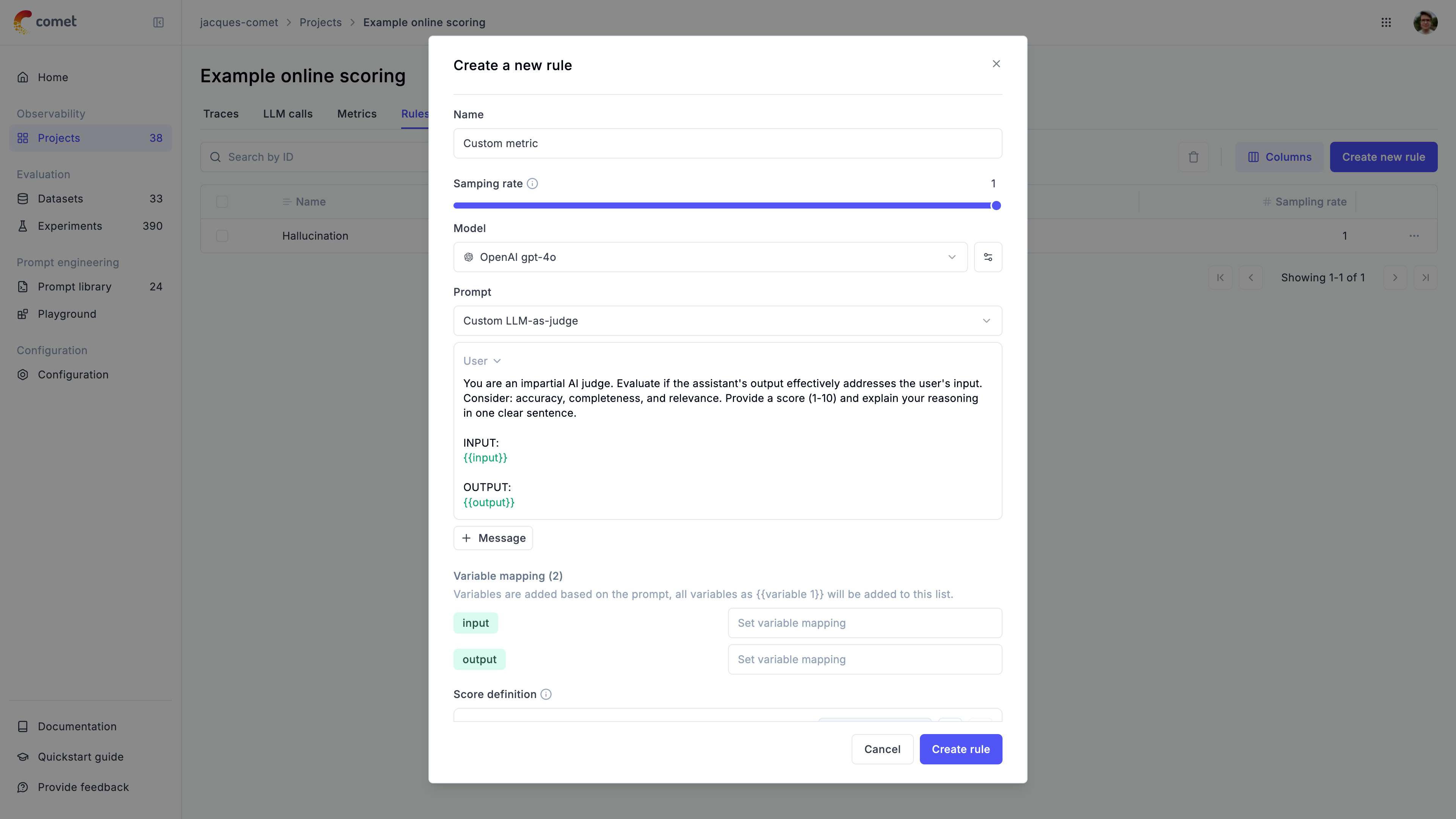
When writing your own LLM as a Judge metric you will need to specify the prompt variables using the mustache syntax, ie.
{{ variable_name }}. You can then map these variables to your trace data using the variable_mapping parameter. When the
rule is executed, Opik will replace the variables with the values from the trace data.
You can control the format of the output using the Scoring definition parameter. This is where you can define the scores you want the LLM as a Judge metric to return. Under the hood, we will use this definition in conjunction with the structured outputs functionality to ensure that the LLM as a Judge metric always returns trace scores.
Evaluating traces with images
LLM as a Judge metrics can evaluate traces that contain images when using vision-capable models. This is useful for:
- Evaluating image generation quality
- Analyzing visual content in multimodal applications
- Validating image-based responses
To reference image data from traces in your evaluation prompts:
- In the prompt editor, click the “Images +” button to add an image variable
- Map the image variable to the trace field containing image data using the Variable Mapping section
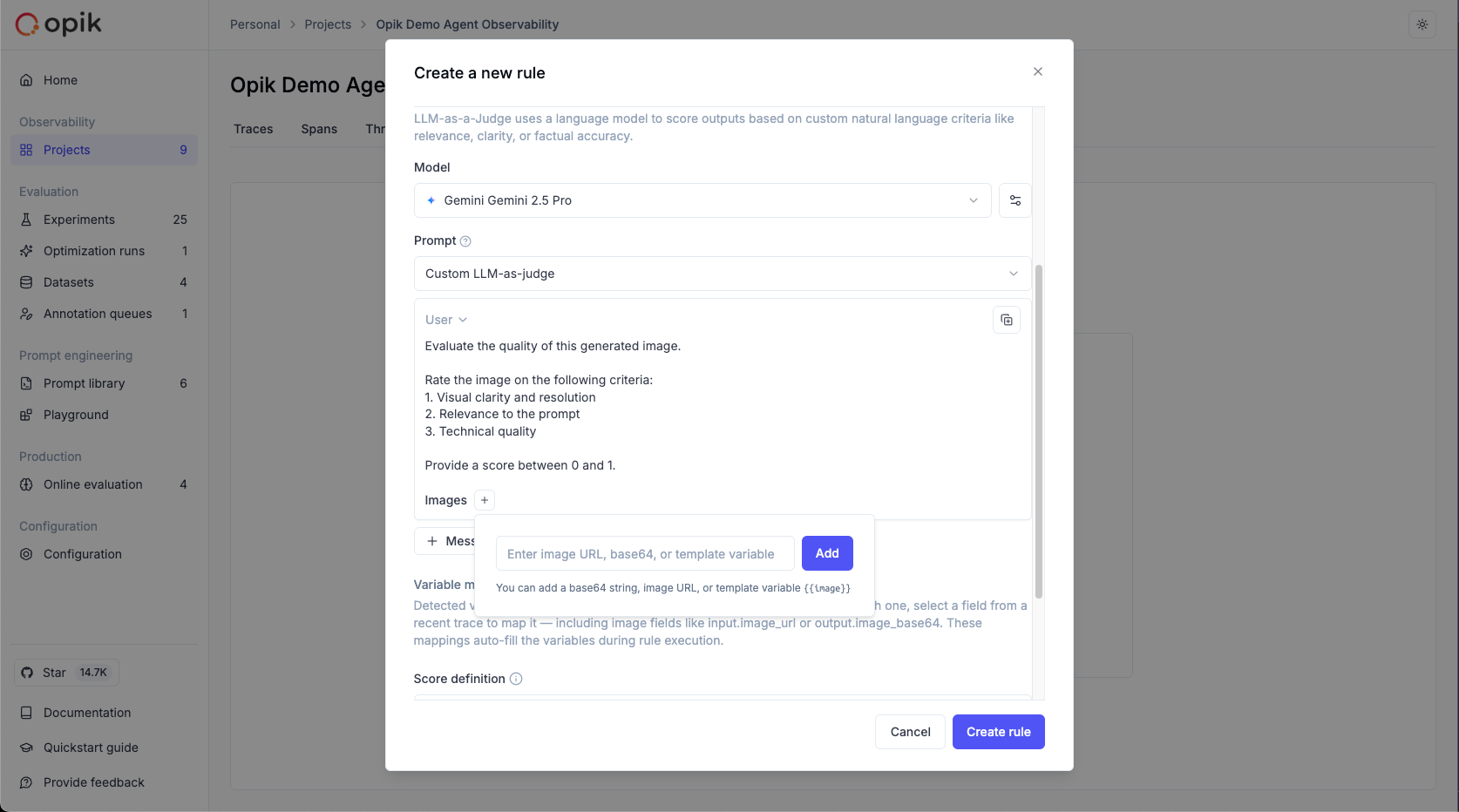
When you add an image using the “Images +” button, Opik automatically adds a new line to the prompt with the image wrapped in <<<image>>><</image>>> tags. This wrapper is not visible in the UI but ensures proper image processing during evaluation.
Example rule configuration:
Prompt:
Variable Mapping:
output_image→output.image_data(path in trace structure)
Model: Vision-capable model required
Supported image formats:
- Image URL
- Base64 encoded image
When mapping image variables, ensure the trace field contains image data in a supported format (image URL or base64 encoded image).
Reviewing online evaluation scores
The scores returned by the online evaluation rules will be stored as feedback scores for each trace. This will allow you to review these scores in the traces sidebar and track their changes over time in the Opik dashboard.
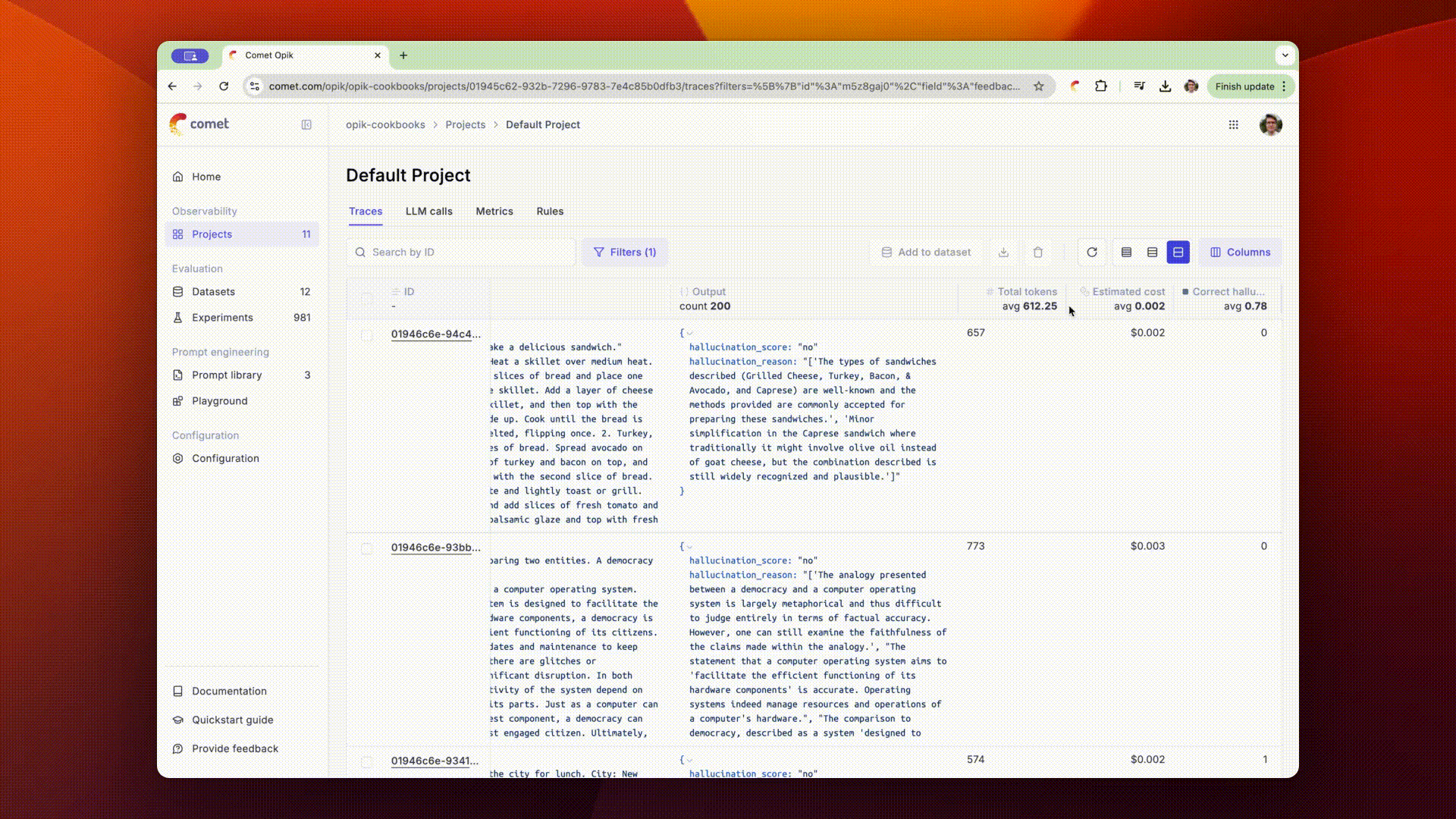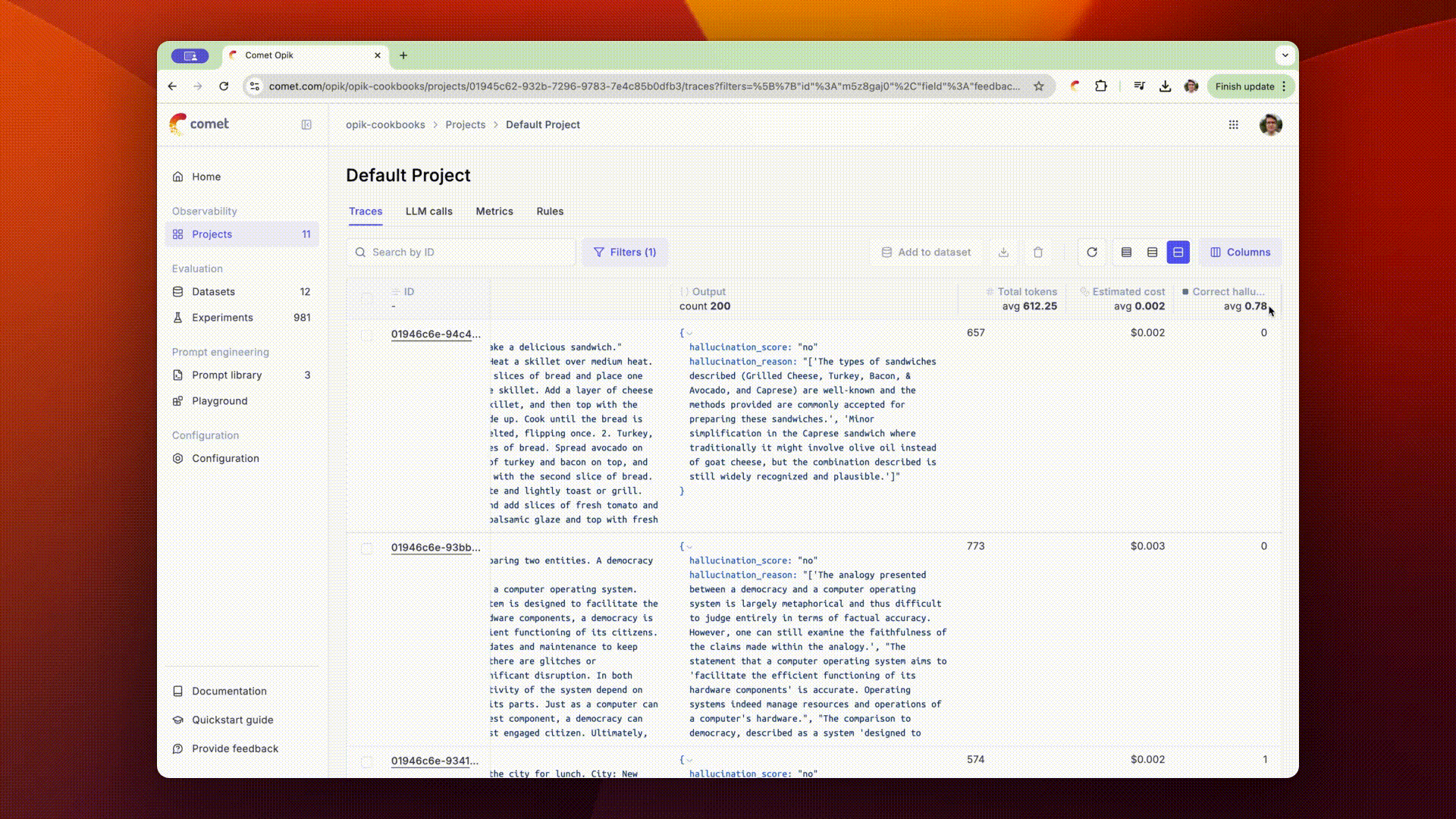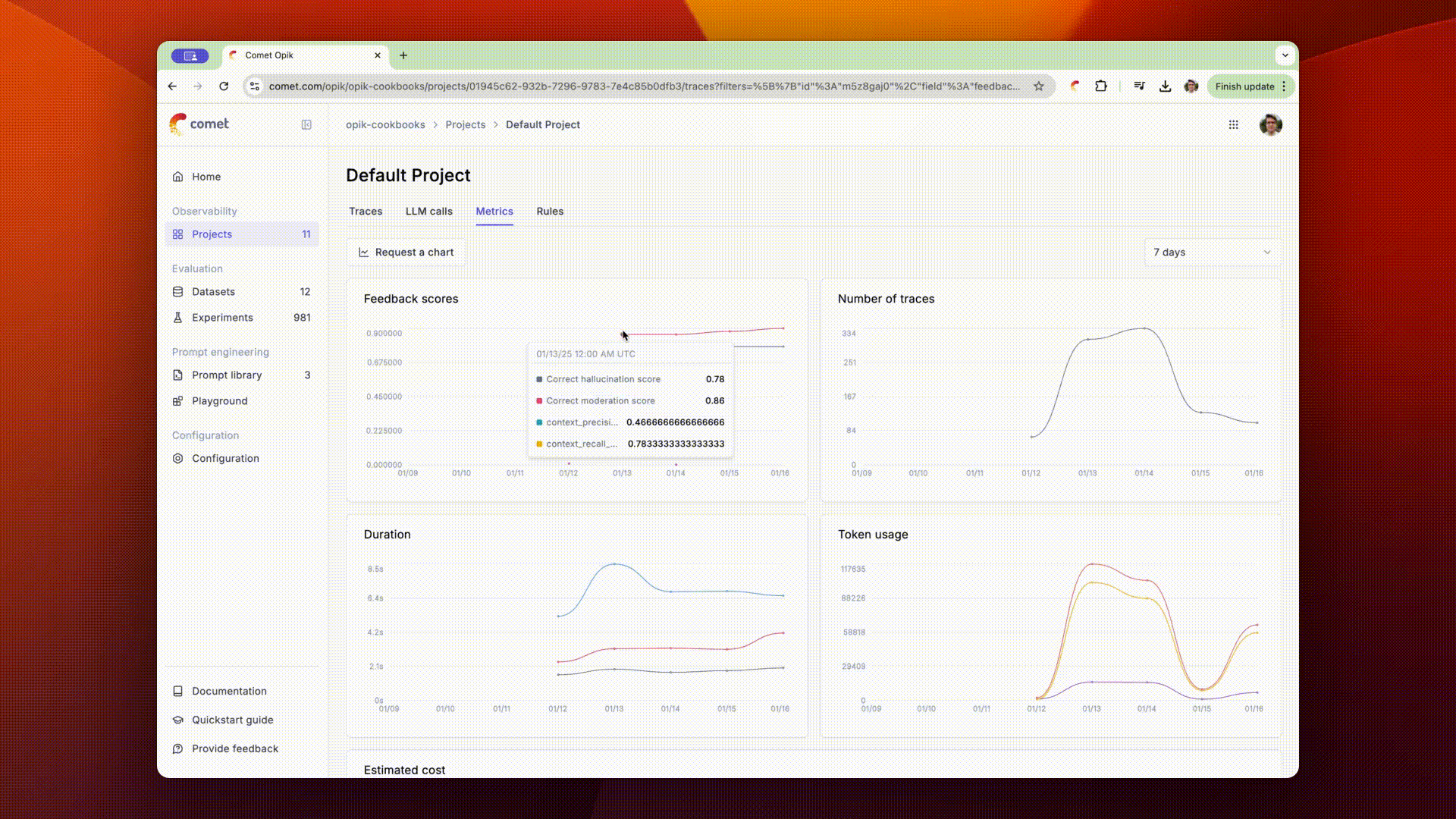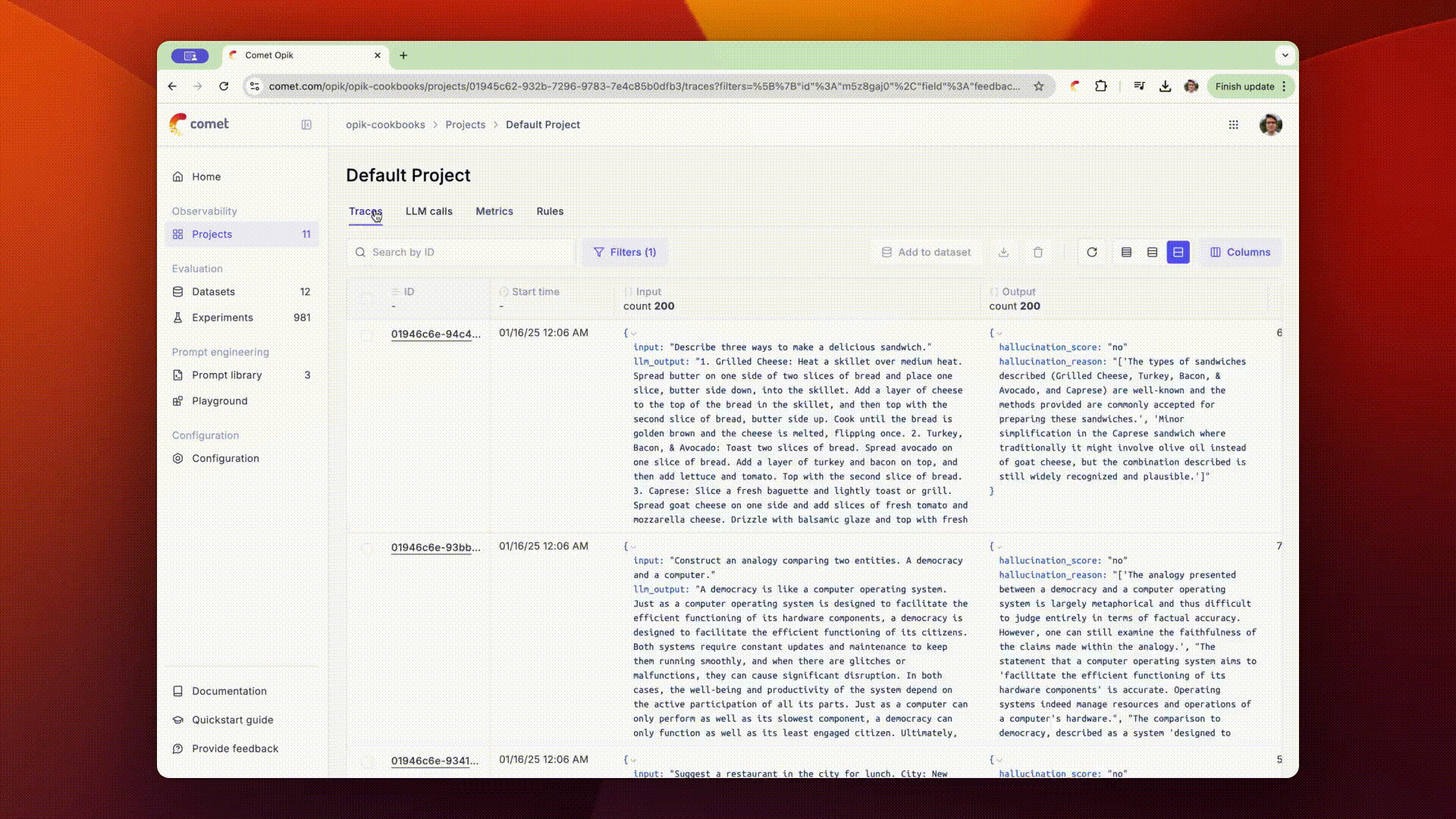
You can also view the average feedback scores for all the traces in your project from the traces table.
Online thread evaluation rules
It is also possible to define LLM as a Judge and Custome Python metrics that run on threads. This is useful to score the entire conversations and not just the individual traces.
We have built-in templates for the LLM as a Judge metrics that you can use to score the entire conversation:
- Conversation Coherence: This metric checks if the conversation is coherent and follows a logical flow, return a decimal score between 0 and 1.
- User Frustration: This metric checks if the user is frustrated with the conversation, return a decimal score between 0 and 1.
- Custom LLM as a Judge metrics: You can use this template to score the entire conversation using your own LLM as a Judge metric. By default, this template uses binary scoring (true/false) following best practices.
For the LLM as a Judge metrics, keep in mind the only variable available is the {{context}} one, which is a dictionary containing the entire conversation:
Similarly, for the Python metrics, you have the Conversation object available to you. This object is a List[Dict] where each dict represents a message in the conversation.
For online scoring rules on threads, Opik waits for a “cooldown period” after the last activity in a thread before running the evaluation. This ensures the scoring is done on the full context of the conversation.
The default cooldown period is 15 minutes but can be configured at the workspace level under “Thread online scoring rule cooldown period”.
For self-hosted installations, set the OPIK_TRACE_THREAD_TIMEOUT_TO_MARK_AS_INACTIVE environment variable.