Quickstart notebook
Quickstart notebook - Summarization
In this notebook, we will look at how you can use Opik to track your LLM calls, chains and agents. We will introduce the concept of tracing and how to automate the evaluation of your LLM workflows.
We will be using a technique called Chain of Density Summarization to summarize Arxiv papers. You can learn more about this technique in the From Sparse to Dense: GPT-4 Summarization with Chain of Density Prompting paper.
Getting started
We will first install the required dependencies and configure both Opik and OpenAI.
Comet provides a hosted version of the Opik platform, simply create an account and grab your API Key.
You can also run the Opik platform locally, see the installation guide for more information.
Implementing Chain of Density Summarization
The idea behind this approach is to first generate a sparse candidate summary and then iteratively refine it with missing information without making it longer. We will start by defining two prompts:
- Iteration summary prompt: This prompt is used to generate and refine a candidate summary.
- Final summary prompt: This prompt is used to generate the final summary from the sparse set of candidate summaries.
We can now define the summarization chain by combining the two prompts. In order to track the LLM calls, we will use Opik’s integration with OpenAI through the track_openai function and we will add the @opik.track decorator to each function so we can track the full chain and not just individual LLM calls:
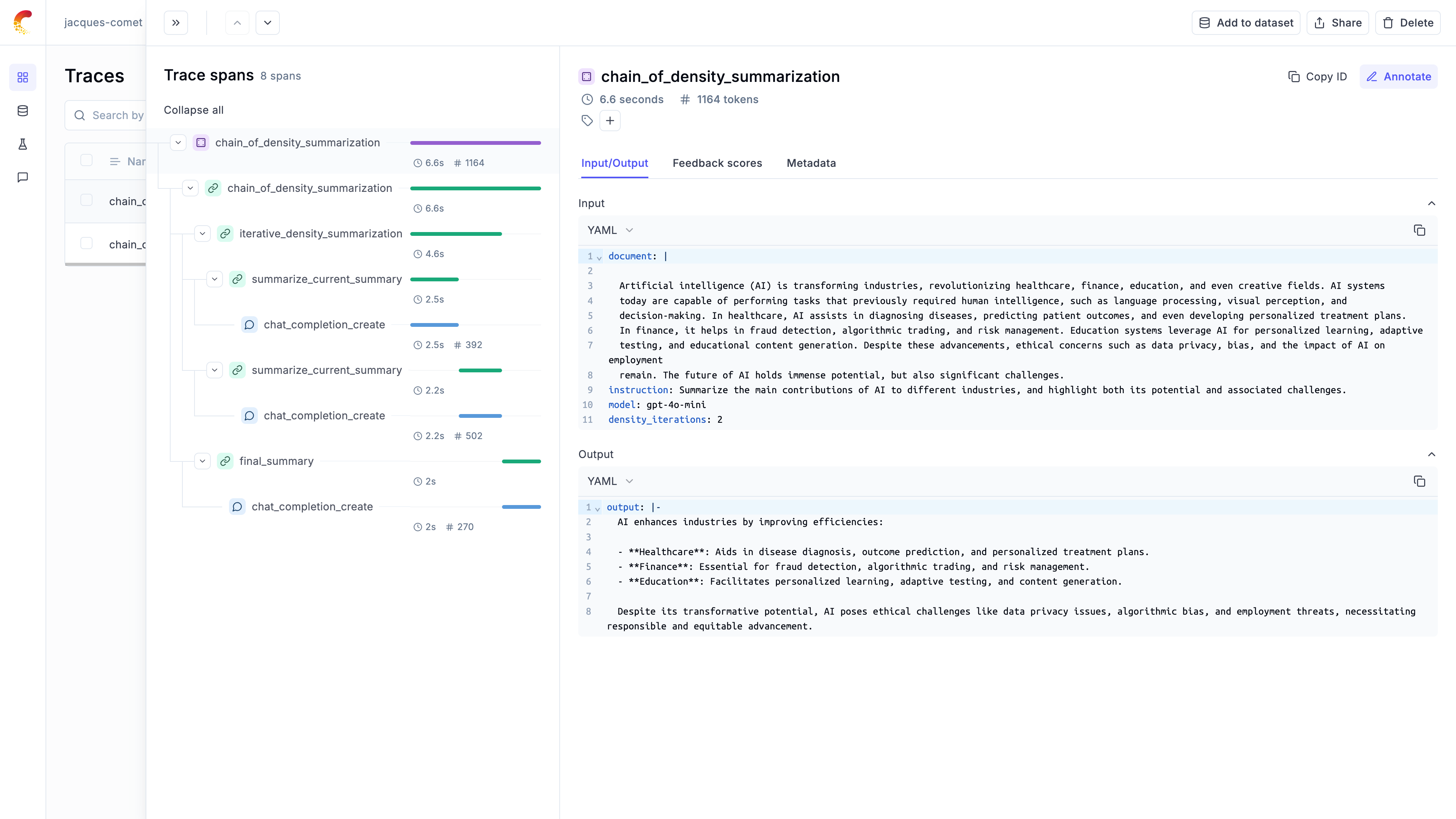
Let’s call the summarization chain with a sample document:
Thanks to the @opik.track decorator and Opik’s integration with OpenAI, we can now track the entire chain and all the LLM calls in the Opik UI:
Automatting the evaluation process
Defining a dataset
Now that we have a working chain, we can automate the evaluation process. We will start by defining a dataset of documents and instructions:
Note: Opik automatically deduplicates dataset items to make it easier to iterate on your dataset.
Defining the evaluation metrics
Opik includes a library of evaluation metrics that you can use to evaluate your chains. For this particular example, we will be using a custom metric that evaluates the relevance, conciseness and technical accuracy of each summary
Create the task we want to evaluate
We can now create the task we want to evaluate. In this case, we will have the dataset item as an input and return a dictionary containing the summary and the instruction so that we can use this in the evaluation metrics:
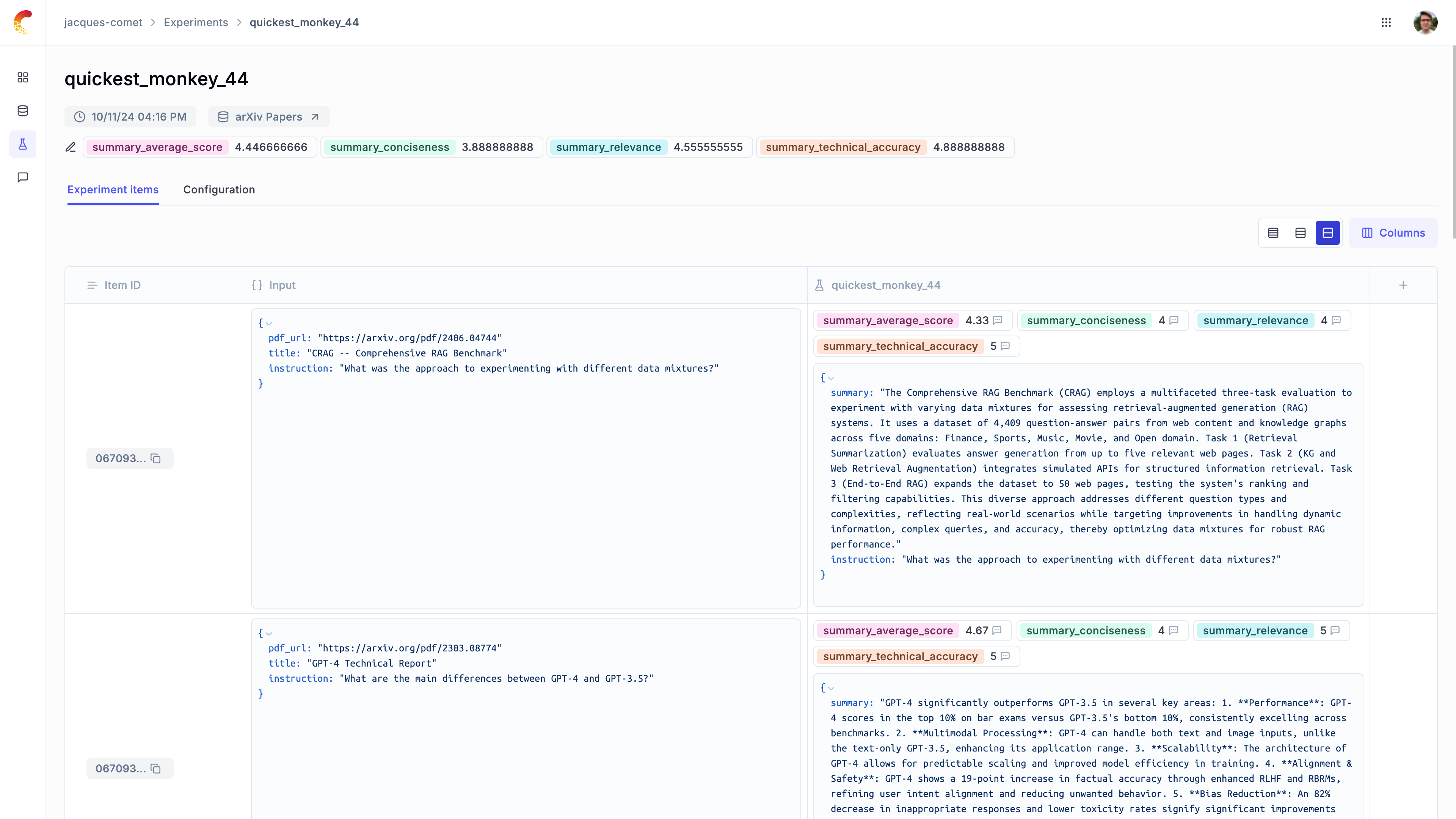
Run the automated evaluation
We can now use the evaluate method to evaluate the summaries in our dataset:
The experiment results are now available in the Opik UI:
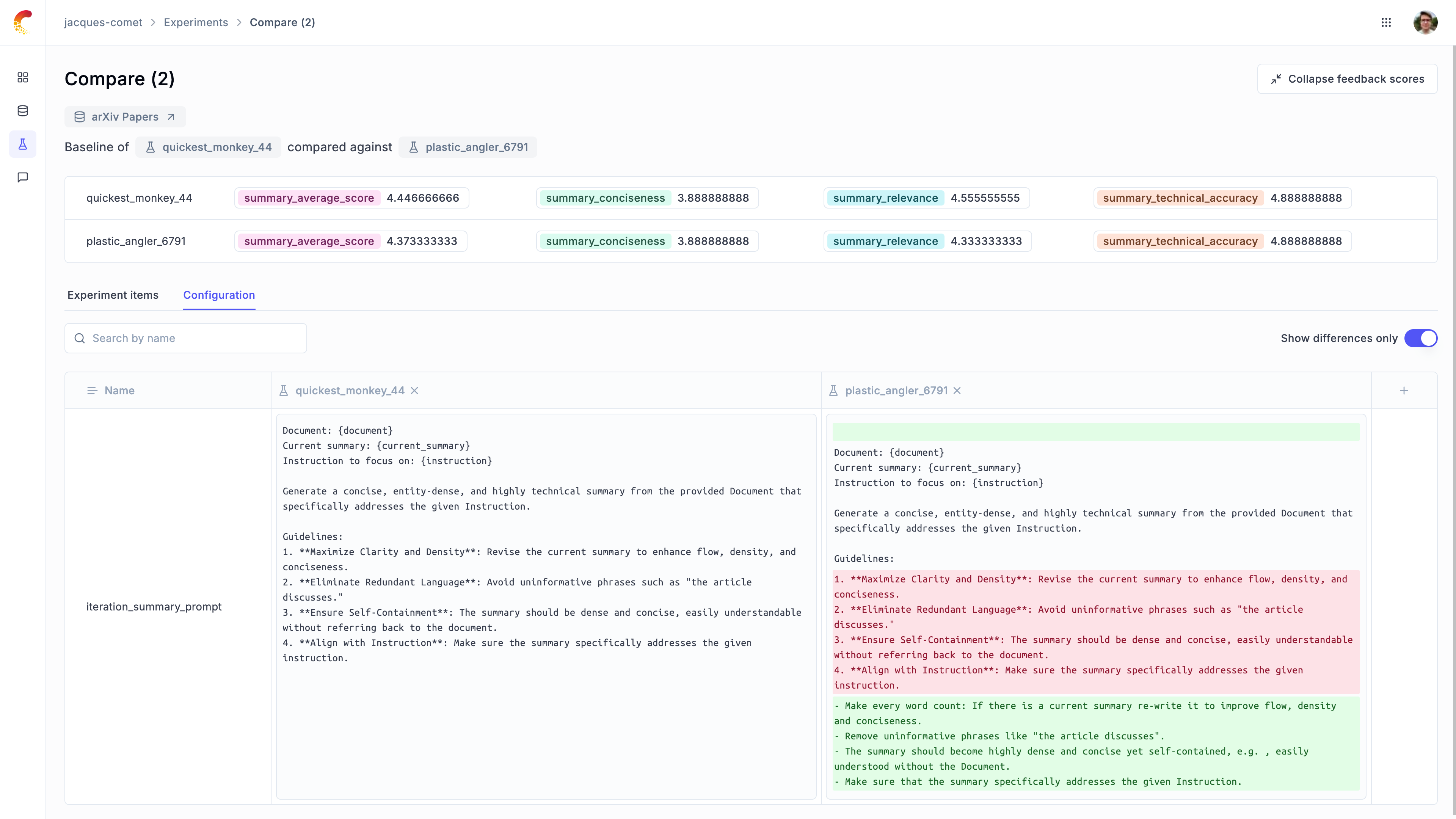
Comparing prompt templates
We will update the iteration summary prompt and evaluate its impact on the evaluation metrics.
You can now compare the results between the two experiments in the Opik UI: