Using Opik with watsonx
Opik integrates with watsonx to provide a simple way to log traces for all watsonx LLM calls. This works for all watsonx models.
Creating an account on Comet.com
Comet provides a hosted version of the Opik platform, simply create an account and grab your API Key.
You can also run the Opik platform locally, see the installation guide for more information.
Preparing our environment
First, we will set up our watsonx API keys. You can learn more about how to find these in the Opik watsonx integration guide.
Configure LiteLLM
Add the LiteLLM OpikTracker to log traces and steps to Opik:
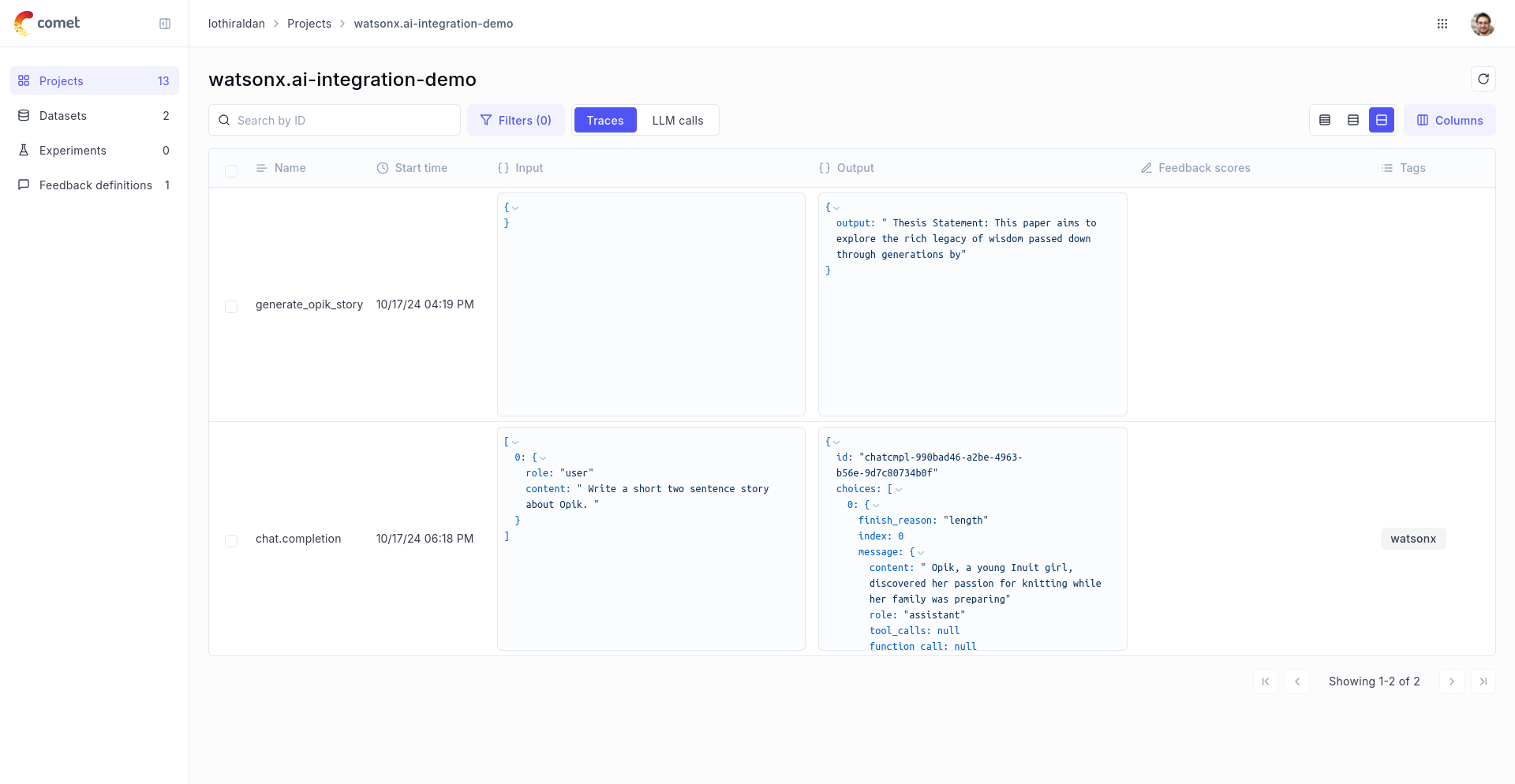
Logging traces
Now each completion will logs a separate trace to LiteLLM:
The prompt and response messages are automatically logged to Opik and can be viewed in the UI.
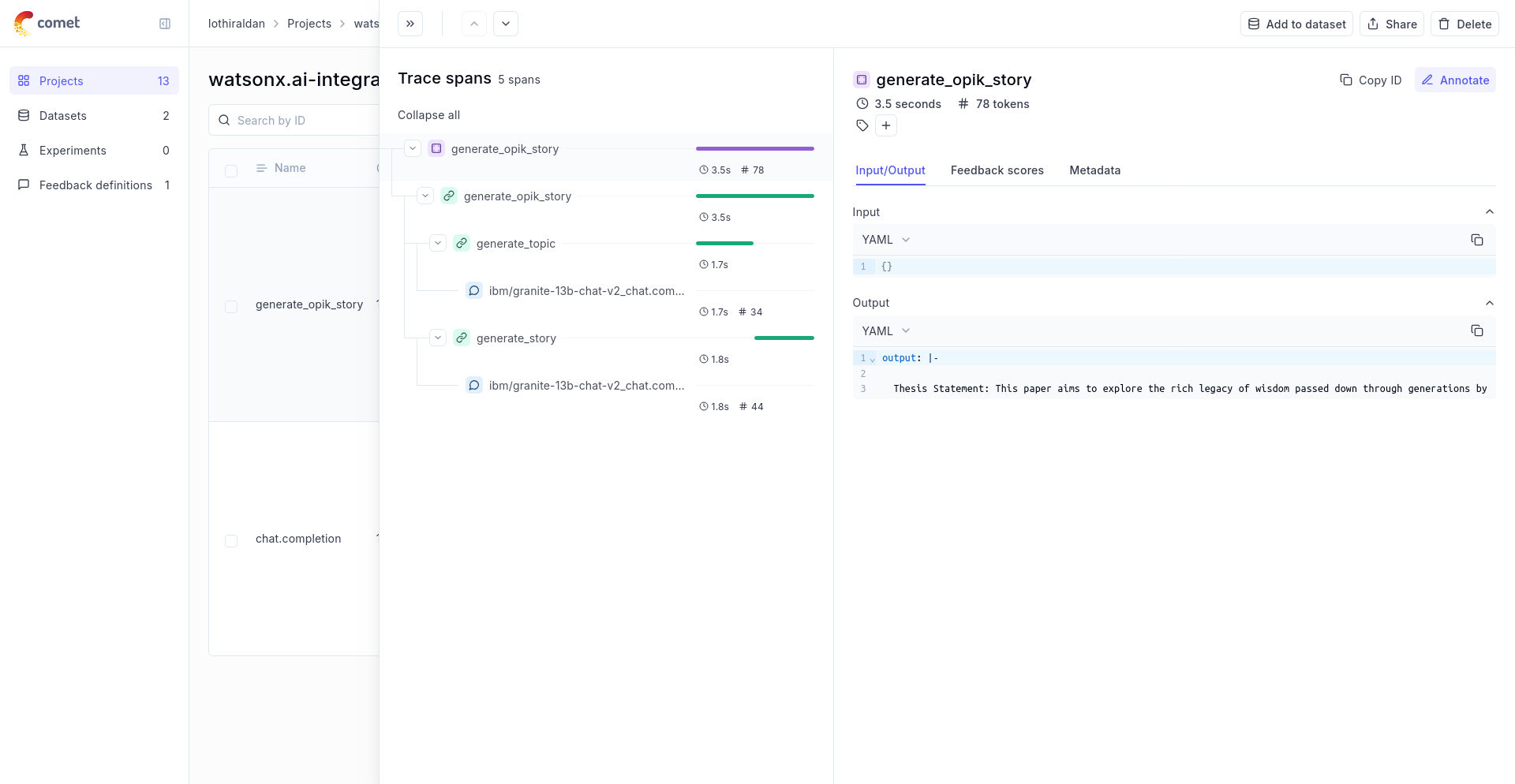
Using it with the track decorator
If you have multiple steps in your LLM pipeline, you can use the track decorator to log the traces for each step. If watsonx is called within one of these steps, the LLM call with be associated with that corresponding step:
The trace can now be viewed in the UI: