Observability for LiteLLM with Opik
LiteLLM allows you to call all LLM APIs using the OpenAI format [Bedrock, Huggingface, VertexAI, TogetherAI, Azure, OpenAI, Groq etc.]. There are two main ways to use LiteLLM:
- Using the LiteLLM Python SDK
- Using the LiteLLM Proxy Server (LLM Gateway)
Account Setup
Comet provides a hosted version of the Opik platform, simply create an account and grab your API Key.
You can also run the Opik platform locally, see the installation guide for more information.
Getting Started
Installation
First, ensure you have both opik and litellm packages installed:
Configuring Opik
Configure the Opik Python SDK for your deployment type. See the Python SDK Configuration guide for detailed instructions on:
- CLI configuration:
opik configure - Code configuration:
opik.configure() - Self-hosted vs Cloud vs Enterprise setup
- Configuration files and environment variables
Configuring LiteLLM
In order to use LiteLLM, you will need to configure your LLM provider API keys. For this example, we’ll use OpenAI. You can find or create your API keys in these pages:
You can set them as environment variables:
Or set them programmatically:
Using Opik with the LiteLLM Python SDK
Logging LLM calls
In order to log the LLM calls to Opik, you will need to create the OpikLogger callback. Once the OpikLogger callback is created and added to LiteLLM, you can make calls to LiteLLM as you normally would:
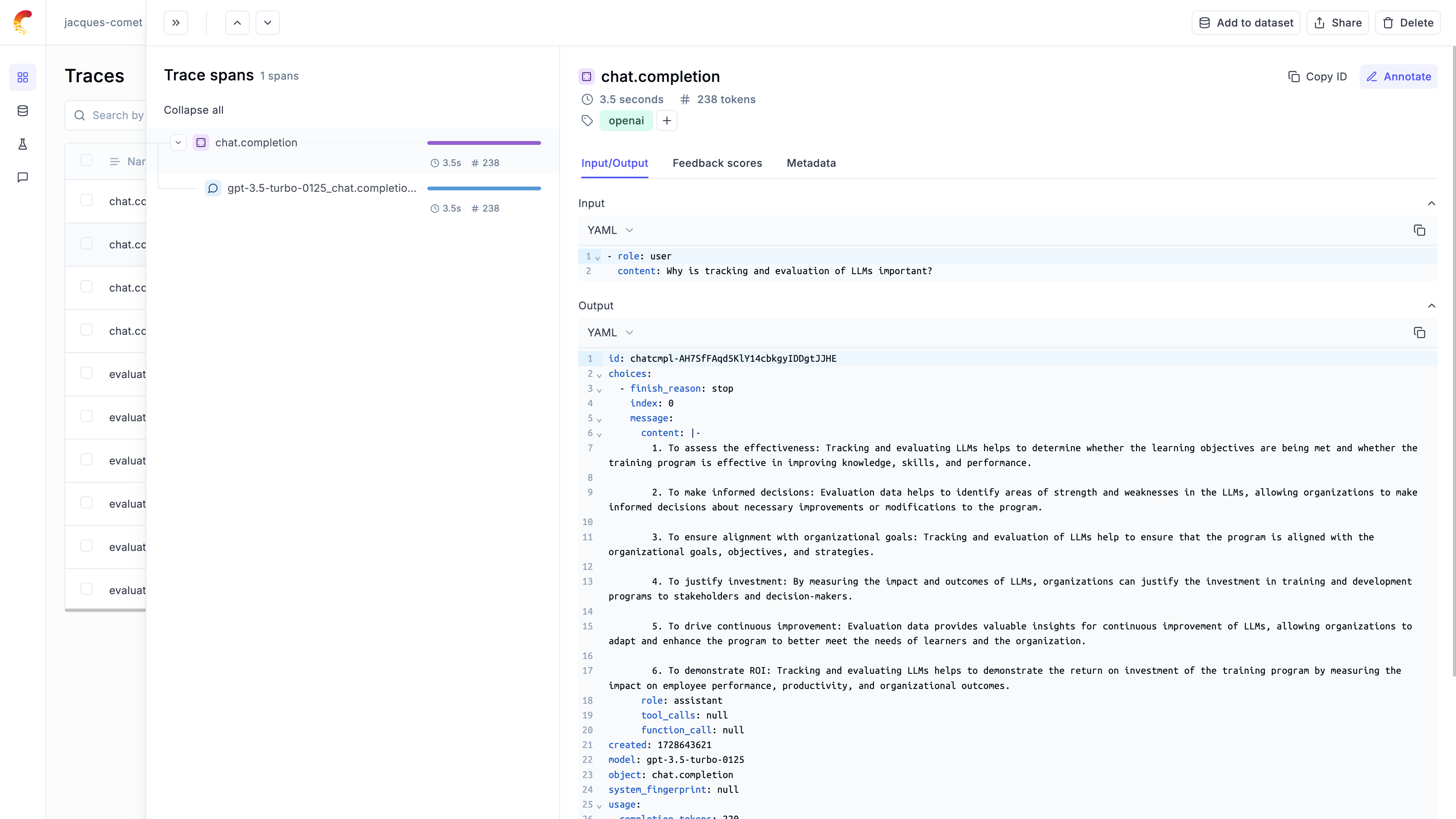
Logging LLM calls within a tracked function
If you are using LiteLLM within a function tracked with the @track decorator, you will need to pass the current_span_data as metadata to the litellm.completion call:
Using Opik with the LiteLLM Proxy Server
Opik Agent Optimizer & LiteLLM: Beyond tracing, the Opik Agent Optimizer SDK also leverages LiteLLM for comprehensive model support within its optimization algorithms. This allows you to use a wide range of LLMs (including local ones) for prompt optimization tasks.
Configuring the LiteLLM Proxy Server
In order to configure the Opik logging, you will need to update the litellm_settings section in the LiteLLM config.yaml config file:
You can now start the LiteLLM Proxy Server and all LLM calls will be logged to Opik:
Using the LiteLLM Proxy Server
Each API call made to the LiteLLM Proxy server will now be logged to Opik: