Introduction
Many of us watch TV shows for leisure within our daily mundane routines via various online streaming platforms (such as Amazon Prime or Netflix), each having its share of show categories. Whenever a new show is launched, its other details (such as episode plot summary) become available online.
Each episode present in the show contains a story with some difference in their nature. To gain an understanding of them in the form of topics/keywords, we will carry out the Topic Modeling concept of Natural Language Processing (NLP) in this article.
The purpose here is to build a machine learning model that analyzes the data for each TV episode and summarizes them into shorter segments while identifying their underlying sentiments.
Data
The data used here comes from the show “Alice in Borderland” currently streaming on Netflix, which includes the following details —
· Name of the Series
· Season No
· Episode Name/No
· Episode Plot Summary
The reference from the above pointers can be taken from the below link —
Text Preparation
Before building the algorithm, it is necessary to prepare the data for processing to perform better analysis to gain valuable insights. Some of the steps that are being followed in this section are as follows:
a) Punctuation Removal —
· All the punctuations such as ‘!”#$%&’()*+,-./:;?@[\]^_{|}~’ contained in the text are removed.
· These are defined within the string library of Python.
def rem_punct(txt):
pfree = "".join([i for i in txt if i not in string.punctuation])
return pfree
read["Episode Plot Summary"] = read["Episode Plot Summary"].apply(lambda x:rem_punct(x))p
b) Lowercasing Text —
· One of the most common tasks in text processing is to convert the characters to lowercase to eliminate useless data or noise.
read["Episode Plot Summary"] = read["Episode Plot Summary"].str.lower()
c) Tokenization —
· Part of the NLP pipeline that converts the text into small tokens (words/sentences).
· Here, word tokenization is performed where each word is subjected to deeper analysis to gather their importance in the text.
read["Episode Plot Summary"] = read["Episode Plot Summary"].str.split()
d) Stopword Removal —
· Stopwords are commonly used words that are removed since they add no value to the analysis.
· The NLTK library used here helps to remove the stopwords from the text.
stp = nltk.corpus.stopwords.words('english')
def rem_stopwords(txt):
st_free = [i for i in txt if i not in stp]
return st_free
read["Episode Plot Summary"] = read["Episode Plot Summary"].apply(lambda x:rem_stopwords(x))
e) Lemmatization —
· This is an algorithmic process followed to convert the word to its root form while also keeping its meaning intact.
word_lemma = WordNetLemmatizer()
def lemma(txt):
l_txt = [word_lemma.lemmatize(w) for w in txt]
return l_txt
read["Episode Plot Summary"] = read["Episode Plot Summary"].apply(lambda x:lemma(x))
Model Preparation
After preparing the data through the series of processing tasks in the previous section, we begin our demonstration for implementing the process for building the Topic Model.
TF-IDF VECTORIZATION
· TF-IDF (Term Frequency — Inverse Document Frequency) is based on the Bag of Words model that provides insights about the relevance of words in a document.
· Term Frequency (TF) measures the frequency of the word occurring in the document.
· Inverse Document Frequency (IDF) measures the importance of words.
In this sub-process, the data is converted into a vectorized format to continue to the next step.
LATENT DIRICHLET ALLOCATION (LDA) PROCESS
LDA is a model where —
· Latent means that the model finds hidden topics in a document.
· Dirichlet indicates that the model assumes the distribution of topics in a document.
The parameters used in the model when carrying out LDA on the vectorized data are as follows —
a) Number of Topics
b) Learning method (the way by which the model assigns the topics to the documents)
c) Number of iterations
d) Random state
#SEASON 1
read_season1 = read[read["Season No"]=="Season 1"]
for i in range(0,len(read_season1['Episode Plot Summary'])):
vect1 = TfidfVectorizer(stop_words = stp, max_features = 1000)
vect_text1 = vect1.fit_transform(read_season1['Episode Plot Summary'][i])
lda_model = LatentDirichletAllocation(n_components = 5, learning_method = 'online', random_state = 42, max_iter = 1)
lda_t = lda_model.fit_transform(vect_text1)
vocab = vect1.get_feature_names()
for k, comp in enumerate(lda_model.components_):
vocab_comp = zip(vocab, comp)
s_words = sorted(vocab_comp, key = lambda x:x[1], reverse=True)[:7]
print("Topic "+str(k)+": ")
for t1 in s_words:
print(t1[0],end=" ")
print("\n")
#SEASON 2
read_season2 = read[read["Season No"]=="Season 2"].reset_index()
for i in range(0,len(read_season2['Episode Plot Summary'])):
vect1 = TfidfVectorizer(stop_words = stp, max_features = 1000)
vect_text1 = vect1.fit_transform(read_season2['Episode Plot Summary'][i])
lda_model = LatentDirichletAllocation(n_components = 5, learning_method = 'online', random_state = 42, max_iter = 1)
lda_t = lda_model.fit_transform(vect_text1)
## for j, topic in enumerate(lda_t[0]):
## print(topic*100)
print(read_season1["Episode No"][i].upper())
vocab = vect1.get_feature_names()
for k, comp in enumerate(lda_model.components_):
vocab_comp = zip(vocab, comp)
s_words = sorted(vocab_comp, key = lambda x:x[1], reverse=True)[:7]
for t1 in s_words:
print(t1[0],end=" ")
print("\n")
With the output generated by following the complete model preparation process in this section, we can obtain the main topics and their importance for each of the episodes in the TV series.
Topic Sentiments
After obtaining the main keywords for the episodes in each season, we come over to analyze and understand the sentiment around them. The technique used here is VADER (Valence Aware Dictionary Sentiment Reasoner), a lexicon and rule-based tool designed for sentiments.
The sentiment scores calculated here are based on the polarity returned as an output using this technique, which lies in the range of [-1, 1] where —
· Positive sentiment lies between 0 and 1
· Negative sentiment lies between -1 and 0
After determining the scores for episodes, we obtained the results in the form of average sentiment for each season, as shown in the below table —
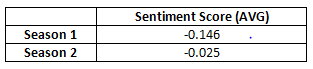
Based on the given results, we observe that in both seasons, we are getting a negative sentiment. This signifies the show was built with a dark theme in mind, and it can fall into any of the following genre categories —
· Violence
· Thriller
· Suspenseful
· Action, etc.
Closing Notes
Reaching the end of the article, we understood the practical implementation of topic modeling in the entertainment field and how the entire summary for the TV Show episodes can be defined into smaller segments.
The NLP procedure carried out here processes the data to get it ready for further machine learning analysis and to identify the genre of the show based on the sentiment scores obtained for each season.
