
Is it necessary for humans to take part in the machine learning cycle?
Contrary to what the movies we watch show us, today’s artificial intelligence (AI) cannot do everything and learn everything on its own. It primarily, and to a large extent, needs the feedback it receives from people.
I would guess that almost 80% of machine learning (ML) applications today consist of supervised learning models. However, applications cover a wide range of uses. For example, autonomous vehicles are trained with many data points such as ‘pedestrian,’ ‘moving vehicle,’ ‘lane markings’ so they can transport you safely. Your device understands you even when you command your home device to ‘volume up’ or say it in different languages to a machine translation app. ML models must be trained with maybe thousands of hours, millions of data, to reach this kind of performance.
Annotation and active learning are the first step and cornerstones of the human-in-the-loop approach in AI/ML.
Human-in-the-loop (HITL) is a cycle that allows people to develop ML approaches that make life easier. You need to know how to get training data from people and get human feedback on all your data. But when you don’t have the budget or time for that, you must find different ways to determine the correct data.
Transfer learning, one of these methods, ensures that we do not exceed a difficult point by adapting the existing ML models to our new task instead of starting from the beginning. Transfer learning has been popular for a while, so I won’t go without mentioning it towards the end of the article. However, we will start with the issue of labeling, in which humans are included in the cycle.
Before we get into the labeling/annotation issue, let’s look at the principles for humans to be in the ML cycle.

Human-in-Loop Fundamentals for ML
When humans and ML interact to solve one or more of the following processes, what we call a HITL begins to happen:
- Making ML more accurate
- Bringing ML to demanded accuracy faster
- Helping people make better decisions
- Making people more productive
Essentially, the data labeling process is simply an HITL process in which humans are involved in ML performance. Regardless of image, sound, text, or sensor data, a process similar to the figure below is required.
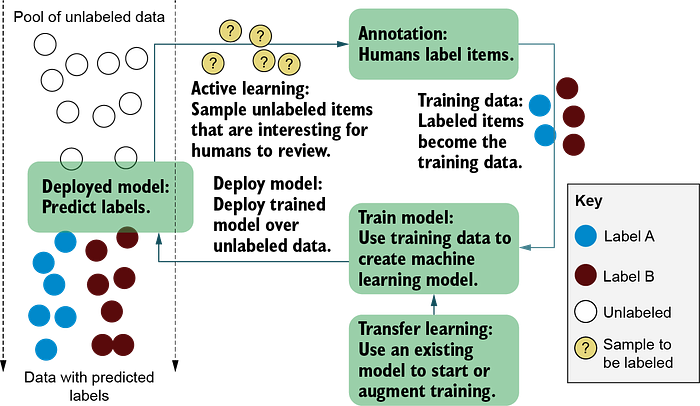
1. Annotation / Labeling
It is the most necessary step to be able to train in ML models. If you ask a data scientist how much time they spend improving the dataset and adapting an ML model, they will answer that it takes more than 50% of the entire ML development process. In other words, it is a challenging process that can be applied with different annotation strategies.
Simple and complex annotation strategies
The annotation process can be straightforward. For example, based on a product’s social media posts, it’s possible to label it “positive,” “negative,” or “neutral” to analyze sensitive trends about the product. For this, you can create and distribute an HTML form within a few hours. A simple HTML form could allow someone to rate each social media post by emotion option. Each rating becomes the label on the social media feed for your training data, and you use it.
On the other hand, the annotation process can be very complicated. If you want to label every object in a video with a simple bounding box, a simple HTML form isn’t enough. You need a graphical interface such as Supervisely App, and it can take months of engineering to create a good user experience.
Filling the gap in data science knowledge
Algorithms and annotations are equally crucial for robust and successful ML applications. These two are nested components. You will usually get better accuracy from your models if you have a combined approach. It is also beneficial to simultaneously optimize your strategy regarding ML algorithms and data.
There are ML courses in almost every computer science department curriculum, but few offer enough information on how to plan training data for ML. You’ll maybe come across a course or two on training data strategy among the hundreds of ML courses. Fortunately, this approach is quietly changing.
We witness that people in academia and the private sector try to walk on the same difficult road differently. In the private sector, as opposed to ML in academic studies, it is more common to improve model performance by adding more training data. Especially when data changes over time (which is very common), just adding some new labeled data can be much more effective than adapting an existing ML model to a new field. However, most academic papers have focused on adapting algorithms to a new domain without adding new training datasets rather than on how to efficiently label accurate and up-to-date training datasets. The reason for this is, of course, the difficulty and limitation of accessing quality datasets.
Increasingly, human resources know how to work with state-of-the-art ML algorithms but have no experience in choosing the proper interfaces to design quality and labeled training datasets. In other words, we are faced with many experts who know algorithms but do not understand data. It is possible to recognize this recently in one of the biggest automobile manufacturers in the world.
They employ many new ML/AI engineers but struggle to make their autonomous vehicle technology functional because they cannot scale their data annotation and labeling strategies. To help scale they should consider rebuilding their process around two components. These two components are equally crucial for a well-performing ML implementation/application:
- Algorithms
- Correctly created (quality/fair) training data
Why is it difficult for humans to label data with quality?
Labeling is a subject of study closely tied to Data Science and ML for researchers. Therefore, it is an essential part of data science. But the most obvious example of the difficulty of this process is that the people providing the labels can make mistakes. Tackling these errors requires surprisingly complex statistics.
Human errors in training data can be more or less critical depending on the use case. If an ML model is only used to identify broad trends in consumer sentiment, it probably doesn’t matter that 1% of the errors are due to erroneous training datasets. But it could be disastrous if an ML algorithm powering an autonomous vehicle couldn’t see 1% of pedestrians due to errors emanating from inaccurate training datasets. Some algorithms may use some noise in the training data, and random noise helps some algorithms to produce more accurate results and be generalizable by preventing overfitting.
But human errors don’t tend to be random noise and thus tend to add irreversible bias to the training data.
In this blog, discussing the importance of data annotation and labeling as science may not excite everyone. Labeling is humankind’s first step to cooperating with machines. I mean, labeling gets humans in the loop of ML from the beginning.
Innovation and academia go hand-in-hand. Listen to our own CEO Gideon Mendels chat with the Stanford MLSys Seminar Series team about the future of MLOps and give the Comet platform a try for free!
2. Active Learning
Increasing speed and decreasing cost
Supervised learning models need more labeled data. It is more successful when it uses more data. Active learning is the process of choosing which data should be labeled. Most research articles on active learning have focused on the number of training data. But speed can be an even more critical factor in many cases.
For example, When working in disaster response, ML models are often used to filter and extract information from emerging disasters. Any delay in disaster response is potentially critical. That’s why getting a usable model becomes more important than the number of labels that need to go into that model.
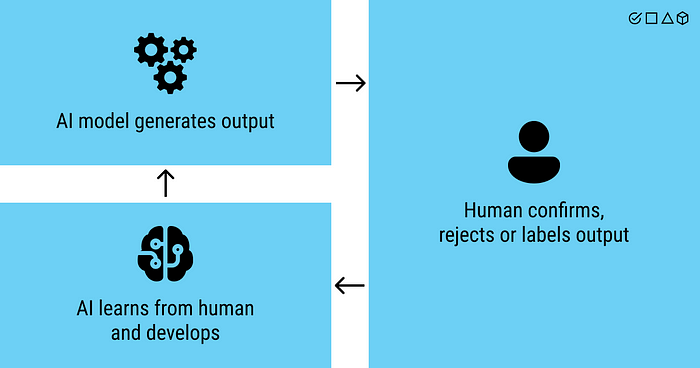
Just as no single algorithm, architecture, or parameter set will make an ML model more accurate in every situation, Nor is there a single strategy for active learning that will be optimal for all use cases and datasets. However, as with ML models, there are some approaches you should try first. Because they are more likely to work. Let’s talk about these strategies now.
The three most commonly used active learning sampling strategies: Uncertainty, Diversity, and Randomness
There are different active learning strategies and many algorithms to implement them. Three basic approaches, most of which work well and should almost always be a starting point, are:
- Uncertainty Sampling
- Diversity Sampling
- Random Sampling
Random Sampling is the simplest but can actually become the most difficult. What if your data is pre-filtered as it changes over time, or if, for some other reason, you know that a random sample set will not represent the problem you are addressing? Regardless of the strategy, some amount of random data always needs to be disclosed and labeled to measure the accuracy of your model and compare your active learning strategies based on randomly selected items.
Uncertainty Sampling (Exploitation) is a strategy for identifying unlabeled elements near the decision boundary in your current ML model. If you have a binary classification task, these will be items with an estimated 50% probability of belonging to both labels. Therefore, the model is “ambiguous” or “complex.” Misclassification of these items is most likely. Thus, it is most likely to result in a different label than the predicted one. It changes the decision boundary after it is added to the training data and the model is retrained.
Diversity Sampling (Exploration) is a strategy used to identify unlabeled items currently unknown by the ML model. This usually means items that contain combinations of rare or invisible attribute values in the training data. Diversity sampling aims to target the ML algorithm for more labels that are outliers or anomalies in the problem domain.
Both Uncertainty Sampling and Diversity Sampling have their own shortcomings. Uncertainty Sampling can only focus on the part of the decision boundary. Diversity Sampling can only focus on outliers that are too far from the border. For this reason, strategies are often used together to find a selection of unlabeled items that will maximize both Uncertainty and Diversity.
In the following illustrations, the positive and negative aspects of different types of active learning have been tried to be expressed.
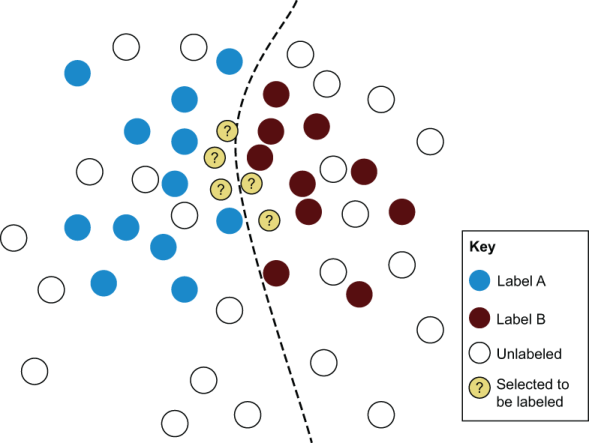

It is important to note that the active learning process is iterative. In each iteration of active learning, a set of elements is defined and receives a new human-generated label, then the model is retrained with new data and the process is repeated.
Random selection of evaluation data
It is easy to say that you should constantly evaluate the selection of randomly held data. However, it may not be that easy in practical terms.
In the recent past, when researchers applied the well-known and extensive selection of data ImageNet datasets to ML models, they used 1,000 labels to identify the category of the image, such as “taper,” “taxicab,” “swimming,” and other primary classes. ImageNet competitions are judged on data retained for testing from this dataset and achieved near human-level precision in the randomly distributed dataset. However, if you take the same models and apply them to a random selection of images posted on a social media platform like Facebook or Instagram, the accuracy immediately decreases by at least ~10%.
The data used from almost all ML applications change over time. If you’ve been working on natural language processing, the topics people talk about will change over time, and the languages themselves will innovate and evolve in reasonably small chunks of time. If you’ve been working on computer vision data, the types of objects you encounter change over time, and sometimes just as significantly, the images themselves change due to advances and changes in camera technology.
If you cannot define a random evaluation dataset, you should try to determine a representative evaluation dataset. If you describe a representative dataset, you agree that a truly random sample is impossible or not meaningful to your dataset. It’s up to you to define what represents your use case, as the data will be determined by how you implement it.
It is recommended for most real-world applications to have a divergent evaluation dataset that will allow you to get the best case for how well your model generalizes. This can be difficult with Active Learning because as soon as you start labeling this data, it is no longer a “different dataset;” it becomes a set you know.
When should we use Active Learning?
You should use Active Learning in situations where you can provide data diversity with labeling and random sampling to only a tiny fraction of your data. It covers most real-world scenarios, as the scale of this data becomes an essential factor in many use cases.
An excellent example of this is the amount of data contained in videos. If you want to put a bounding box around every object in every video frame, that would be very time-consuming. Imagine this is for an autonomous vehicle, and it’s a street video with only about 20 objects you care about:
Let’s say 10 other cars, 5 pedestrians, and 5 traffic signs. At 30 frames per second, that’s (30 frames × 60 seconds × 20 objects). So, you need to create 36,000 boxes for just one minute of data!
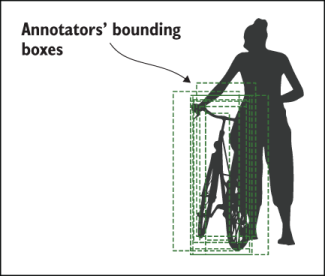
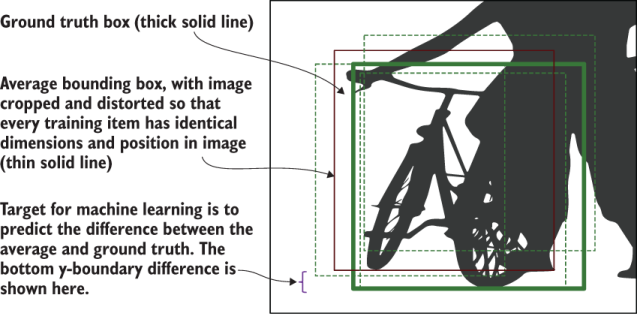
Completing the labels required for just one minute of video can take at least 12 hours for even the fastest labeling person. In the US alone, people drive an average of 1 hour per day, which means that people in the US drive 95,104,400,000 hours per year.
We expect that soon every car will have a video camera in front of it to assist with driving or driving. So in the US alone, it would take approximately 60,000,000 (60 Trillion) hours to label on a year of driving! Even if the rest of the world does nothing more than label data all day to make US drivers safer, there doesn’t seem to be enough people to label videos of US drivers today.
Whatever an autonomous vehicle company’s budget for labeling will be much less than the amount of data to be labeled. So, data scientists at the autonomous vehicle company have to decide about the labeling process: is every frame in a video appropriate? Can we add examples to videos, so we don’t need to label them all? Are there ways to design a labeling interface to speed up the process?
The unsustainability of labeling will apply in most cases: The point is that we will always have more data than the budget and time allocated for labeling.
Closing
Intelligent systems that learn interactively from their end users are rapidly becoming widespread. Until recently, this progress was mainly fueled by advances in ML; however, more and more researchers are aware of the importance of studying the users of these systems. You’ve seen how this approach can result in better user experiences and more effective learning systems. There is no reason not to argue that interactive ML systems should involve users at every stage of the design process.
Human-computer interaction is a well-established field in computer science that has recently become particularly important for ML. It’s a field where cognitive science, social sciences, psychology, user experience design, and many other fields intersect as we build interfaces for people to create educational data.
HITL ML is an iterative process that combines human and machine components. Active learning through labeling is only the first step. In another blog post, we can examine the transfer learning dimension of the subject.
Feel free to follow me on GitHub and Twitter accounts for more content!
I would like to thank Başak Buluz Kömeçoğlu for her feedback on this blog post.
