With the arrival of the Llama-2 model, several articles have been published to describe the nuances of fine-tuning it in a consumer-grade GPU. In many of those tutorials, the authors would have touched upon how critical the dataset’s quality is for fine-tuning. But only some of them would have delved deeper into how we can curate the high-quality, focused dataset for the fine-tuning purpose of specialized LLMs. In this article, I will explain how I leveraged the industry standard Alpaca dataset towards building a quality dataset for fine-tuning food-based LLMs.
Let’s get started…

Alpaca Dataset — Overview
Alpaca is a dataset of 52,000 instructions generated by OpenAI’s text-davinci-003 engine. These 52K instructions span different domains such as text summarization, fashion, maths, food, etc., and they are widely employed to fine-tune LLM models.
You can find more details about the Alpaca dataset here.
The Alpaca dataset has been created with the consideration of having diverse datasets covering various kinds of activities that LLMs could be used for. The image below summarizes how diverse the Alpaca instructions are, and using such a diverse dataset for fine-tuning any specific purpose LLMs may not be helpful.
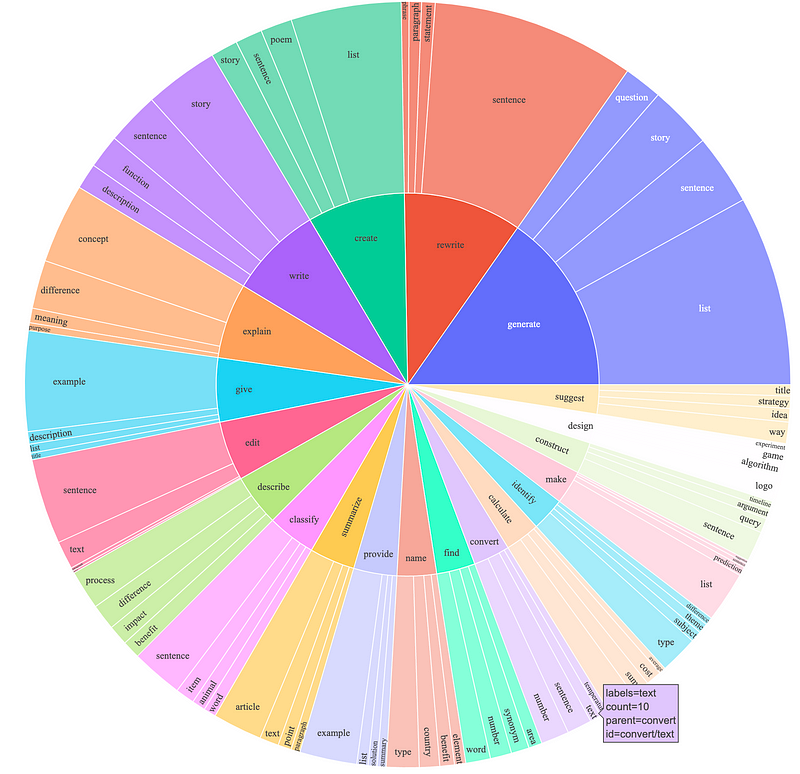
So, to build any specific LLMs, we could extract the questions related to that particular domain from the base set. And I wanted to build an LLM about the ‘food’ domain. Hence, I considered making a text classification model to identify food-related instructions from the base alpaca dataset.
Rather than building a text classification model from scratch, I considered exploring ‘few shot learning’ models, and the results were outstanding. Let’s learn more about ‘few-shot learning’ and ‘contrastive learning.’
Contrastive Learning & Few Shot Learning
Contrastive learning is a branch of machine learning where we fine-tune an already trained model with a few samples of a specific problem with positive and negative samples — such that the fine-tuned model can perform classification tasks more accurately.
I have employed this approach towards extracting food-related datasets from Alpaca’s diverse dataset by leveraging the SetFit model. You can refer to how the ‘SetFit’ model helps with few shot learning in this detailed HuggingFace blog post.
As mentioned in the above blog, SetFit helps train the text classification models with a handful of data. It leverages sentence transformers to embed the text data and fine-tunes the head layer to perform the classification task.
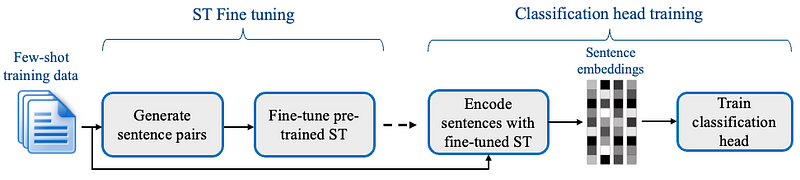
Few-Shot Training — Data Preparation
As explained, we are all set to train the SetFit model with a handful of data. So, I have curated the dataset with exactly 8 counts of +ve and -ve classes.
Here, the objective is to extract the food-related data from the Alpaca dataset. So, the +ve class is food-related data, and the -ve class is all other data. I have prepared 8 counts of data with food information and another 8 counts with diverse topics such as quantum computers, psychology, fashion, etc.
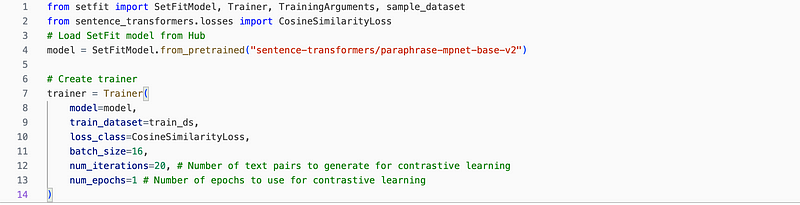
I have used the hyper-parameter config as below, with 20 iterations of training and ‘CosineSimilarityLoss’ as a loss function:
Post-training, the model can identify the food-related data from the rest and predict the Alpaca dataset. I was able to extract 1000+ records related to food, and most of the classifications were spot on.
With the extracted data, I have fine-tuned the LLM, and the results of the LLM model are decent, considering the number of epochs that I have trained.
You can refer to this code from the official ‘databricks’ repository about fine-tuning Llama models with custom datasets in your environment.
Summary
Thus, at the end of the article, we summarize how I leveraged the few-shot learning approach to extract the ‘food’ related instruction dataset from Alpaca and how it helped me build a custom LLM model for my food-related needs.
Please follow my handle for more insightful articles about LLMs and their applications. Happy Reading!
