Explainability refers to the ability to understand and evaluate the decisions and reasoning underlying the predictions from AI models (Castillo, 2021). Artificial Intelligence systems are known for their remarkable performance in image classification, object detection, image segmentation, and more. However, they are often considered “black boxes” because it can be challenging to comprehend how their internal workings generate specific predictions.
Explainability techniques aim to reveal the inner workings of AI systems by offering insights into their predictions. They enable researchers, developers, and end-users to understand the decision-making process better and potentially identify biases, errors, or limitations in a model’s behavior.
This guide will buttress explainability in machine learning and AI systems. It will also explore various explainability techniques and tools facilitating explainability operations.
What is Explainability?
The explainability concept involves providing insights into the decisions and predictions made by artificial intelligence (AI) systems and machine learning models. It borders on the capability to explain “why” and “how” an AI system arrives at a specific output or decision.
In “Explaining explanations in AI,” Brent Mittelstadt highlights that the field of machine learning and AI is now focused on providing simplified models that instruct experts and AI users on how to predict the decisions made by complex systems, as well as understanding the limitations and potential vulnerabilities of those systems.
Through the explainability of AI systems, it becomes easier to build trust, ensure accountability, and enable humans to comprehend and validate the decisions made by these models. For example, explainability is crucial if a healthcare professional uses a deep learning model for medical diagnoses. The ability to explain how the model arrived at a particular diagnosis is paramount for healthcare professionals to understand and trust the recommendations provided by the AI system.
Key Objectives and Benefits of Explainability
Explainability is essential for achieving several objectives and benefits in machine learning and AI systems. By enhancing the interpretability of these systems, explainability aims to achieve the following goals:
- Transparency and Trust: A recurring question over the years is how to establish transparency and trust in the results of AI systems. Explainability aims to make AI systems more transparent by demystifying the “black box” nature, where their internal processes and decision-making mechanisms are often difficult to comprehend. Through several “Explainable Models,” explainability enables users to achieve insights into the inner workings of the models and understand the factors that influence their output.
- Algorithmic Accountability: Explainability ensures accountability in machine learning and AI systems. It allows developers, auditors, and regulators to examine the decision-making processes of the models, identify potential biases or errors, and assess their compliance with ethical guidelines and legal requirements.
- Human-AI Collaboration: Explainability facilitates effective collaboration between humans and AI by providing interpretable insights and fostering a mutually beneficial partnership. For instance, human experts bring domain knowledge and expertise that can complement AI systems. This allows experts to validate AI model decisions against their knowledge and experience. They can evaluate whether the model’s reasoning aligns with their expectations and identify potential errors or biases. Additionally, explainability facilitates the integration of the Human-in-the-Loop (HITL) system, where humans can interact with the AI system, review and interpret its outputs, and provide feedback to refine and improve the model.
- Fairness and Bias Mitigation: Explainability addresses issues related to fairness and bias in machine learning systems by providing insights into the decision-making process and enabling the detection and mitigation of biases. An explainability concept like Bias Detection can identify biased correlations or patterns in the decision-making process of machine learning models. For example, through its AI Fairness 360, IBM performed Bias Detection to identify correlations that might lead to unfair outcomes or disproportionately impact specific groups. This analysis helps to identify features that may introduce bias into the model’s decisions.
- Error Detection and Debugging: Explainability techniques help identify and understand errors or inaccuracies in machine learning models. By revealing the reasoning behind a model’s predictions, explainability allows developers to pinpoint areas of weakness or misinterpretation. This helps debug the models, improve accuracy, and reduce potential risks associated with incorrect decisions.
Distinction Between Interpretability and Explainability
Interpretability and explainability are interchangeable concepts in machine learning and artificial intelligence because they share a similar goal of explaining AI predictions. However, there are slight differences between them. Cynthia Rudin, a computer science professor at Duke University, emphasized the difference between interpretability and explainability. The scholar, in her work, opines that:
Interpretability is about understanding how the model works, whereas explainability involves providing justifications for specific predictions or decisions. However, interpretability is a prerequisite for explainability.
Let’s further consider the subtle differences between these concepts.
- Definition
- Interpretability: In “Interpretable Machine Learning,” Christoph Molnar explains interpretability as the degree to which humans can comprehend a machine learning model’s cause-and-effect relationship between inputs and outputs. It focuses on the ability to understand and interpret the model’s inner workings, including feature importance, decision rules, and the reasoning behind predictions.
- Explainability: Explainability, on the other hand, provides understandable explanations for AI systems’ decisions and predictions. It involves presenting the reasons and justifications for the outputs of the model in a way that is interpretable and transparent to humans.
2. Scope and Granularity
- Interpretability: Interpretability typically relates to the model’s internal mechanisms and representations. It aims to provide insights into how the model processes and transforms the input data, allowing humans to grasp the model’s decision-making process. This includes understanding the learned features, the influence of different variables, and the overall decision logic.
- Explainability: Explainability extends beyond the internal workings of the model and encompasses the ability to present meaningful and understandable explanations to users or stakeholders. It focuses on communicating the reasons behind specific predictions or decisions made by the model, using methods such as bias detection, example-based, and rule-based explanations.
3. Audience and Context
- Interpretability: Interpretability primarily targets researchers, data scientists, or experts interested in understanding the model’s behavior and improving its performance. It provides insights into model refinement, feature engineering, or algorithmic modifications.
- Explainability: Explainability has a broader audience, including end-users, domain experts, or regulators who need to understand and trust the AI system’s outputs. It aims to provide human-readable explanations that are accessible and understandable to non-technical users, allowing them to trust, verify, and make informed decisions based on the model’s predictions.
4. Techniques and Approaches
- Interpretability: Techniques for model interpretability include feature importance analysis, activation visualization, or rule extraction methods. These techniques reveal the internal workings of the model and provide insights into how different features contribute to the model’s predictions.
- Explainability: Explainability techniques include generating textual explanations, visualizing decision processes, or using natural language generation to present intuitive explanations. These techniques create human-understandable justifications and reasoning behind the model’s outputs.
Although interpretability and explainability terms are interchangeable, understanding their subtle differences can clarify the specific goals and methods for making AI systems more understandable. Both concepts are vital for promoting transparency, trust, and accountability in deploying machine learning models.
Explainability Methods and Techniques
Explainability methods and techniques are crucial for understanding machine learning and AI model predictions. These techniques bridge the gap between the complex inner workings of the models and human comprehension. Here, we explore several well-established methods and techniques for explainability:
Feature Importance
Feature importance techniques help identify individual features’ contribution to the model’s decision-making process. One popular method is “Permutation Importance,” which involves randomly shuffling the values of a feature and measuring the impact on the model’s performance. This model inspection technique shows the correlation between the feature and the target. It is helpful for non-linear and opaque estimators. Here’s an example of calculating feature importance using permutation importance with scikit-learn in Python:
from sklearn.inspection import permutation_importance
# Fit your model (e.g., a RandomForestClassifier)
model.fit(X_train, y_train)
# Calculate feature importances
result = permutation_importance(model, X_test, y_test, n_repeats=10, random_state=42)
importances = result.importances_mean
# Print feature importances
for feature, importance in zip(X.columns, importances):
print(f"{feature}: {importance}")
Rule-Based Explanations
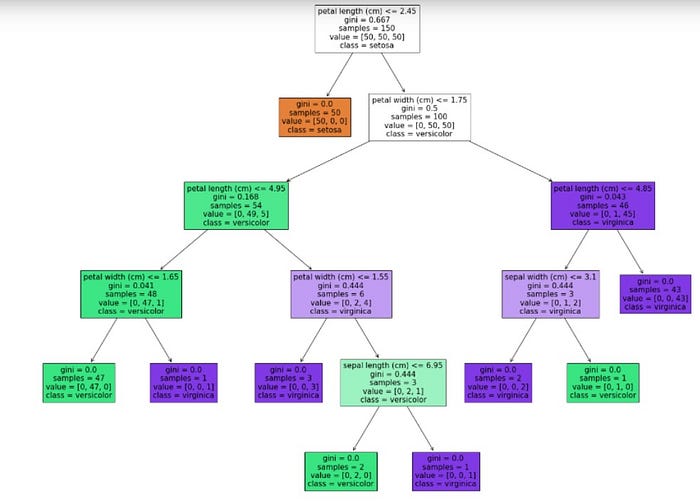
Rule-based explanations are an effective approach to understanding the behavior and decision-making process of machine learning models. These explanations provide human-readable rules that capture the logic behind the model’s predictions. The “Decision Tree” is a popular example of the rule-based model that offers interpretable insights into how the model arrives at its decisions.
Decision trees can be trained and visualized in rule-based explanations to reveal the underlying decision logic. For instance, let’s consider the plot_tree function in scikit-learn using an iris dataset:
fig = plt.figure(figsize=(25,20))
_ = tree.plot_tree(clf,
feature_names=iris.feature_names,
class_names=iris.target_names,
filled=True)
We will get an output that shows the decision-making process from the algorithm like this:
Local Explanations
Local explanation methods aim to explain individual predictions rather than the entire model. “LIME (Local Interpretable Model-Agnostic Explanations)“ is a popular technique for generating local explanations. The main idea behind LIME is to approximate the decision boundary of the black-box model locally around a specific instance. It works by perturbing the instance’s features and observing the resulting changes in the model’s predictions.
Based on these perturbations and observations, LIME constructs a local surrogate model, such as a linear regression model, that approximates the black-box model’s behavior near the instance. Here’s an example of using LIME with a logistic regression model:
from lime import lime_tabular
from sklearn.linear_model import LogisticRegression
# Fit a logistic regression model
model = LogisticRegression()
model.fit(X_train, y_train)
# Initialize LIME explainer
explainer = lime_tabular.LimeTabularExplainer(X_train.values, feature_names=X.columns, class_names=["class 0", "class 1"])
# Explain an individual prediction
exp = explainer.explain_instance(X_test.iloc[0].values, model.predict_proba)
# Print the explanation
exp.show_in_notebook(show_table=True)
Visualization
Visualization techniques play a crucial role in explaining and interpreting the behavior and predictions of machine learning models. They provide visual representations that make it easier for users to understand and interpret the model’s internal processes.
Saliency maps are a popular visualization technique highlighting the important regions or features in an input image that contribute most to the model’s prediction. It enables users to understand the significance of various aspects in the model’s “eyes” by rendering the images as heatmaps or grayscale images.
Here’s an example of generating a saliency map using TensorFlow and Keras:
import tensorflow as tf
import matplotlib.pyplot as plt
# Define the model
model = tf.keras.models.Sequential([...])
# Load an input image
image = tf.io.read_file('image.jpg')
image = tf.image.decode_image(image)
image = tf.image.resize(image, (224, 224))
image = tf.expand_dims(image, axis=0)
image = image / 255.0
# Calculate gradients for saliency map
with tf.GradientTape() as tape:
tape.watch(image)
predictions = model(image)
top_prediction = tf.argmax(predictions[0])
gradients = tape.gradient(predictions[:, top_prediction], image)[0]
# Generate the saliency map
saliency_map = tf.reduce_max(tf.abs(gradients), axis=-1)
# Visualize the saliency map
plt.imshow(saliency_map, cmap='hot')
plt.axis('off')
plt.show()
We will get a similar result to the image below:

These techniques provide valuable insights into model behavior and facilitate better understanding and trust in machine learning and AI systems.
Tools and Frameworks for Explainability
Tools and frameworks are vital in enabling explainability in machine learning models. They provide developers, researchers, and practitioners with a range of functionalities and techniques to analyze, interpret, and explain the decisions and predictions made by AI systems. One such powerful tool is Comet, which offers a comprehensive MLOps platform.
Comet
Comet is a machine learning operations (MLOps) platform that supports experiment tracking, visualization, and collaboration. It provides various features that facilitate explainability and enhance the interpretability of machine learning models. Let’s explore some key capabilities of Comet and how they can contribute to the explainability process.
- Experiment Tracking and Logging: Comet allows you to log various aspects of your experiments, including hyperparameters, metrics, model architectures, and dataset details. By tracking and logging this information, you can maintain a comprehensive record of your experiments, enabling better reproducibility and transparency. For explainability purposes, you can log the explanations generated by different techniques and associate them with the corresponding model runs.
from comet_ml import Experiment
# Initialize a Comet ML experiment
experiment = Experiment(api_key="your-api-key", project_name="your-project-name")
# Log hyperparameters
experiment.log_parameters({"learning_rate": 0.001, "batch_size": 32})
# Log metrics
experiment.log_metric("accuracy", 0.85)
- Visualization and Reporting: Comet provides visualization tools to analyze and interpret the results of your experiments. It offers interactive charts, plots, and graphs to visualize metrics, hyperparameters, and other relevant data. These visualizations help you gain insights into the behavior of your models and identify patterns or trends. In the context of explainability, you can visualize the explanations generated by different techniques and compare their effectiveness.

- Integrated Explainability Techniques: Comet integrates with popular explainability techniques and libraries, allowing you to apply and compare different methods easily. For example, you can leverage techniques such as feature importance analysis, LIME, SHAP (SHapley Additive exPlanations), and more. These techniques help identify the features or factors that contribute most to the model’s predictions and generate explanations at the local or global level.
- Collaboration and Model Sharing: Comet enables collaborative work by allowing multiple team members to view and contribute to the experiments. It provides features like sharing experiments, commenting, and version control, facilitating effective communication and knowledge sharing among team members. This collaborative environment is beneficial when working on explainability tasks, as it allows experts to share insights, discuss findings, and collectively improve the interpretability of the models.
These are just a few of the capabilities of Comet to facilitate explainability experiments. The platform’s rich features, integration with popular libraries, and focus on experiment management and collaboration make it a valuable tool for users.
Captum
Captum is a PyTorch library that focuses on interpretability and explainability. It offers techniques, including integrated gradients, occlusion sensitivity, and feature ablation, to understand model decisions and attribute them to input features. Captum allows users to explain both deep learning and traditional machine learning models.
Alibi
Alibi is an open-source Python library for algorithmic transparency and interpretability. It provides a collection of techniques, including counterfactual explanations, contrastive explanations, and adversarial explanations. Alibi supports various models, including deep neural networks, and allows users to generate explanations for individual predictions.
Rulex Explainable AI
Rulex Explainable AI is an explainability tool that enables users to gain insights and understanding into the decision-making process of AI models. It offers features and capabilities that enhance transparency and interpretability in AI systems.
TensorFlow Extended (TFX)
TFX is a machine learning platform from Google. It provides data validation, preprocessing, model training, and model serving tools. TFX also includes TensorFlow Model Analysis (TFMA), which offers model evaluation and explainability capabilities, such as computing feature attributions and evaluating fairness metrics.
Conclusion
Explainability in machine learning and AI systems is crucial in enhancing transparency and trust. Through its various techniques, we gain valuable insights into the decision-making process of these models. Also, prioritizing explainability promotes responsible and ethical use of AI, fostering transparency and accountability. The journey of exploring explainability empowers us to understand better and harness the potential of machine learning and AI systems in a responsible and trustworthy manner.
References
- Castillo, D. (2021). Explainability in Machine Learning || Seldon
- Blazek, P. J. (2022). Why We Will Never Open Deep Learning’s Black Box || Towards Data Science
- Brent, M., Russell, C. & Watcher, S. (2018). Explaining Explanations in AI || SSRN
- Onose, E. (2023). Explainability and Auditability in ML: Definitions, Techniques, and Tools || Neptune.ai Blog
- Mahmood, A. (2022). Tackling Bias in Machine Learning || IBM blog
- Rudin, C. (2019). Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead || Natural Machine Learning.
- O’Sullivan, C. (2020). Interpretable vs Explainable Machine Learning || Towards Data Science
- Permutation Feature Importance || Scikit-Learn
- What is a Decision Tree? || Masters in Data Science
- Ribeiro, M., Singh, S. & Geustrin, C. (2016). Local Interpretable Model-Agnostic Explanations (LIME): An Introduction || O’Reilly
