An inside look at Etsy’s approach to A/B testing, examining an adversarial attack called DeepSloth, exploring the MLOps landscape, and more.
Welcome to issue #4 of The Comet Newsletter!
This week, we take a closer look at an adversarial attack called DeepSloth that targets Adaptive Deep Neural Nets. Additionally, we explore Etsy’s approach to developing more effective A/B testing with control variates.
Additionally, you might enjoy a tutorial for building a Few-Shot Predictions Transformer with Hugging Face, as well as a deep dive into the current state of the MLOps landscape.
Like what you’re reading? Subscribe here.
And be sure to follow us on Twitter and LinkedIn — drop us a note if you have something we should cover in an upcoming issue!
Happy Reading,
Austin
Head of Community, Comet
INDUSTRY | WHAT WE’RE READING | PROJECTS | OPINION
Machine learning security needs new perspectives and incentives
At this year’s International Conference on Learning Representations (ICLR) researchers from the University of Maryland presented a new type of adversarial attack intended to slow down deep learning models deployed on edge devices.
Tudor Dumitras’ (@tudor_dumitras) group presented an attack called DeepSloth that targets Multi-Exit Strategy Neural Networks, specifically Shallow-Deep Networks, an architecture developed by their group in 2019. These types of architectures save compute resources by providing multiple exit points for model predictions. This means that computation does not need to flow through every layer of the network.
For classification tasks, the technique adds a classifier after certain intermediate layers of the network. The model will bypass the calculations of the remaining layers when it becomes confident about the prediction from the earlier layers. The researchers describe this as avoiding “Network Overthinking”.
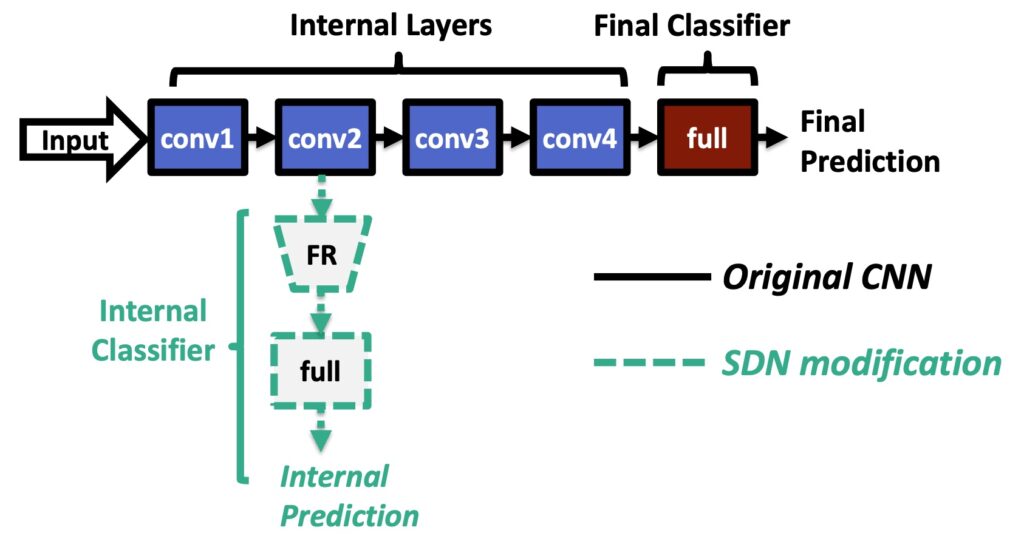
These types of models can be deployed in scenarios where the model is split between an edge device (mobile, IoT device) and a cloud inference server. The earlier layers of the network are present on the edge device, while the deeper layers reside in the cloud. In cases where the edge side of the model does not reach a conclusive result, it defers further computations to the cloud.
The DeepSloth attack creates a specific type of input that forces the network to “overthink”, and send all its requests to the cloud server.
According to Dumitras, “In a scenario typical for IoT deployments, where the model is partitioned between edge devices and the cloud, DeepSloth amplifies the latency by 1.5–5X, negating the benefits of model partitioning.”
Additionally, Yigitcan Kaya (@YigitcanKaya1), one of the PhD students responsible for developing DeepSloth, says that one of the biggest problems in Machine Learning security research is that it’s treated as an academic problem. Instead, Kaya argues, the authors should be encouraged to find ways to break their own solutions like their group did with Shallow-Deep Neural Networks.
“If an industry practitioner finds these papers and implements these solutions, they are not warned about what can go wrong,” noted Kaya. “Although groups like ours try to expose potential problems, we are less visible to a practitioner who wants to use an early-exit model. Even including a paragraph about the potential risks involved in a solution goes a long way.”
Read Ben Dickson’s full article here.
INDUSTRY | WHAT WE’RE READING | PROJECTS | OPINION
Etsy Engineering: Increasing experimentation accuracy and speed by using control variates
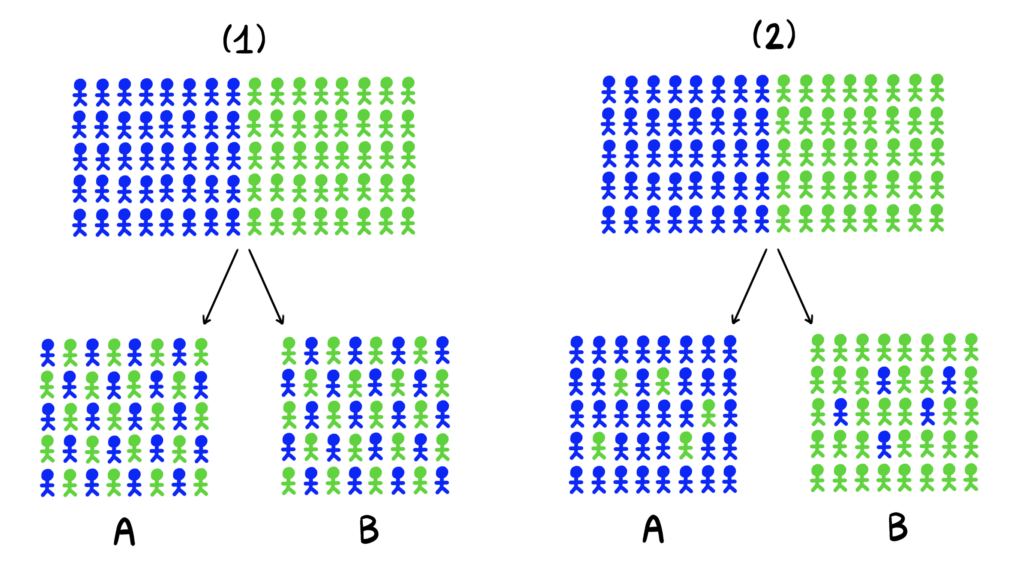
In this post, members from Etsy’s Online Experimentation Science team—a group of engineers and statisticians responsible for building more advanced and scalable statistical tools for online experiments—describe details about bringing the statistical method known as CUPED to Etsy.
CUPED is an acronym for Controlled Experiments Using Pre-Experiment Data. The method is focused on estimating treatment effects in A/B tests more accurately. The challenge lies in quantifying how much of the observed difference is due to real effects, and how much of it is due to noise caused by comparing two subpopulations made of non-identical users.
One way to render these latter fluctuations negligible is to increase the number of users in each group; however this is not always a viable approach, as it can lead to longer experimentation times, and sometimes it just isn’t possible to get a larger sample.
Traditionally, A/B testing looks for differences in outcomes between sample means:
YA – YB
The key idea behind CUPED is not only to play with sample sizes, but also to explain parts of these fluctuations away with the help of other measurable discrepancies between the groups.
The CUPED estimator can be written as:
YA – YB – (XA – XB) β
which corrects the traditional estimator with an additional denoising term. Intuitively, this denoising term aims to account for how much of the difference in Y is not due to any effect of the treatment, but rather due to differences in other observable attributes (X) of the groups. In the equation above, X can be a well-thought-out vector of user attributes (so-called covariates and symbolized by X), and a vector β of coefficients to be specified.
X is a vector of pre-experiment variables (collected prior to each user’s entry into the experiment) that ensures the correction term added by CUPED does not introduce any bias.
According to the authors, “The more information on Y we can obtain from X, the more variance reduction we can achieve with CUPED. In the context of A/B testing, smaller variances imply smaller sample size requirements, hence shorter experiments”
Read the team’s full article here.
INDUSTRY | WHAT WE’RE READING | PROJECTS | OPINION
Few-shot learning in practice: GPT-Neo and the Hugging Face Accelerated Inference API
Transformers continue to be the dominant architecture of 2021. Apart from demolishing benchmarks on previous NLP tasks, large Transformer models now find applications in Few-Shot Learning problems.
Typically, the quality of machine learning applications is limited based on the amount of available training data. In this guide, Philipp Schmid (@_philschmid) from Hugging Face demonstrates how providing a few examples at inference time with a large language model can overcome this barrier for fine tuning a pretrained model for a specified task.
Schmid uses the GPT-Neo, an open source attempt at recreating GPT3, and Hugging Face’s Accelerated Inference API to build a Few-Shot Prediction model that does not require fine tuning on the domain task.
Read Schmid’s full article here.
INDUSTRY | WHAT WE’RE READING | PROJECTS | OPINION
Navigating the MLOps Tooling Landscape: A 3-part Series
The past 3 years have seen a huge rise in companies focusing on the MLOps space. The sheer number of options available these days for tooling around production Machine Learning can lead to a lot of decision fatigue.
In this series of posts, LJ Miranda (@ljvmiranda921) outlines a decision framework for selecting the appropriate tools for your Machine Learning projects. His series addresses some key questions such as, “Who is benefiting from adopting this tool?”, “What is the exact need that your team is trying to solve with this tool?” and “What are the adoption strategies that you can apply when considering a new tool?”
His work builds on insights gathered from Thoughtworks’ Technology Radar. Different organizations approach Machine Learning in very different ways, and it is rare that a single tool can solve all the needs of every organization. Evaluation frameworks help drive better adoption practices by forcing organizations to actively question the core issues they are having around ML productionization.
Read Miranda’s full exploration in 3 parts:
