How to Fine-Tune LLMs on Custom Datasets at Scale using Qwak and Comet
Welcome to Lesson 7 of 11 in our free course series, LLM Twin: Building Your Production-Ready AI Replica. You’ll learn how to use LLMs, vector DVs, and LLMOps best practices to design, train, and deploy a production ready “LLM twin” of yourself. This AI character will write like you, incorporating your style, personality, and voice into an LLM. For a full overview of course objectives and prerequisites, start with Lesson 1.
This lesson will focus on engineering and deploying the fine-tuning pipeline for our LLM Twin model.
Before doing that, let’s walk through a short recap, to understand how we’ve got to this fine-tuning stage:
→ In Lesson 2 — we’ve described the process of data ingestion where we’re scrapping articles from Medium, posts from LinkedIn, and Code snippets from GitHub and storing them in our Mongo Database.
→ In Lesson 3, we’ve showcased how to listen to MongoDB Oplog via the CDC pattern, and adapt RabbitMQ to stream captured events, this is our ingestion pipeline.
→ In Lesson 6 — we’ve showcased how to use filtered data samples from our QDrant[12]. Using Knowledge Distillation, we have the GPT3.5 Turbo to structure and generate the fine-tuning dataset that is versioned with CometML.
In Lesson 7, we will build the fine-tuning pipeline using the versioned datasets we’ve logged on CometML, compose the workflow, and deploy the pipeline on Qwak [2] to train our model.
Further, apart from covering the model selection, PEFT and QLoRA configs, LLM special tokens, and the overall model training process, we’ll review the bits and pieces of how Qwak works and showcase the CometML experiment tracking and model versioning logic.
Completing this lesson, you’ll gain a solid understanding of the following:
- what is Qwak AI and how does it help solve MLOps challenges
- how to fine-tune a Mistral7b-Instruct on our custom llm-twin dataset
- what is PEFT (parameter-efficient-fine-tuning)
- what purpose do QLoRA Adapters and BitsAndBytes configs serve
- how to fetch versioned datasets from CometML
- how to log training metrics and model to CometML
- understanding model-specific special tokens
- the detailed walkthrough of how the Qwak build system works
Without further ado, let’s dive into the topics and cover them individually.
🔗 Check out the code on GitHub [1] and support us with a ⭐️
Table of Contents
- What is LLM Finetuning
a. PEFT — parameter-efficient-fine-tuning
b. Lora — Low Rank Adaptation
c. BitsAndBytes - Qwak AI Platform
a. How it targets MLOps
b. Cost System
c. Prerequisites
d. The Build Lifecycle - Mistral7b-Instruct LLM Model
a. ModelCard
b. Hugging Face Setup
c. Tokenizer Special Tokens - The Finetuning Pipeline
a. System Design
b. Implementation
c. Deployment on Qwak - Experiment Tracking with Comet
- Ending Notes and Conclusion
What is LLM Fine-tuning?
Fine tuning represents the process of taking pre-trained models and further training them on smaller, specific datasets to refine their capabilities and improve performance in a particular task or domain. Fine-tuning [5] is about turning general-purpose models and turning them into specialized models.
Foundation models know a lot about a lot, but for production, we need models that know a lot about a little.
In our LLM Twin use case, we’re aiming to fine-tune our model from a general knowledge corpora towards a targeted context that reflects your writing persona.
PEFT — parameter-efficient-fine-tuning
A technique designed to adapt large pre-trained models to new tasks with minimal computational overhead and memory usage. It involves reusing the pre-trained model’s parameters and fine-tuning them on a smaller dataset, saving computational resources and time compared to training the entire model from scratch.
🔗 Find more about PEFT [6].
QLoRA — Quantized Low-Rank Adaptation
A specific PEFT technique that enhances the efficiency of fine-tuning LMs by introducing low-rank matrices into the model’s architecture, capturing task-specific information without altering the core model weights.
It involves freezing the pre-trained model weights and injecting trainable rank decomposition matrices into each layer of the transformer architecture, greatly diminishing the number of trainable parameters for downstream tasks.
🔗 Find more about QLoRA [7].
BitsAndBytes
Is a library designed to optimize the memory usage and computational efficiency of large models by employing low-precision arithmetic. Underneath, it uses custom CUDA kernel implementations that allow for lower precision operations within Transformer-based models.
While PEFT and LoRA focus on reducing the number of trainable parameters, BitsAndBytes configs help reduce the precision of these parameters, leading to even greater resource savings.
🔗 Find more about BitsAndBytes [8].
Qwak AI Platform
An ML engineering platform that simplifies the process of building, deploying, and monitoring machine learning models, bridging the gap between data scientists and engineers. For more details, see Qwak [2].

Key points within the ML Lifecycle that Qwak [2] solves:
- Deploying and iterating on your models faster
- Testing, serializing, and packaging your models using a flexible build mechanism
- Deploying models as REST endpoints or streaming applications
- Gradually deploying and A/B testing your models in production
- Build and Deployment versioning
- Selective GPU Instance Pooling and Scheduling
Qwak Cost System
Qwak provides both CPU and GPU-powered instances based on the QPU quota. The QPU [4] stands for qwak-processing-unit and it helps users manage their platform quota. A QPU [4] is the equivalent of 4 CPUs with 16 GB RAM, which costs $1.2/hour.
The freemium version allows for 100 QPU/month which is enough to cover the LLM Twin course requirements for fine-tuning.

Prerequisites
To access the platform, head over to Qwak [2] and create an account using the Start Free from the up-left side. Next, you’ll need the API_KEY to be able to work with the CLI tool.
Once logged in, on the left bar, head over to Settings then under Personal Settings select Personal API keys, generate a new key, and copy it to the clipboard.

Next, you would have to install the qwak-sdk to interact with the platform.
# PIP
pip install qwak-sdk
# POETRY
poetry add qwak-sdk
Next, let’s configure the Qwak workspace. Run qwak configure and you’ll be prompted with “Please enter your API key:”, paste the key, and done.
Once we have configured the qwak-sdk tool, and have created an account on Qwak, let’s go ahead and inspect how the Qwak build process works and what the Model Blueprint looks like.
The Build Lifecycle
Now, let’s understand how exactly the Qwak build system works and iterate on how to define a model schema, model interface, build steps, and deployment workflow.

Let’s start with the Python Project blueprint.
Here’s the folder structure for a new Qwak build, that will further encapsulate our model and functionality when deploying it on Qwak.
[QwakNewModelBuild]
|--- main/
| |- __init__.py
| |- requirements.txt
| |- model.py
|--- tests/
| |- __init__.py
| |- unit_tests.py
|
|--- test_local_model.py
# intended to test the model with `run_local` on your machine to validate it before pushing to qwak
|--- test_live_model.py
# code to test the model in the process of Running Tests from above.
# Basically involves a `qwak_inferece.RealTimeClient` class that wraps your model and passes a dummy input through it.
Key points from here:
__init__.py: This contains a single method `load_model()` which returns a instance of model.ClassName.requirements.txt: Represents our environment package, which can be replaced with eitherpyproject.tomlorconda.yaml.model.py: The model class implementation, where we’ll implement the QwakModelInterface.
[QwakModel] class implements these methods:
|
|-- build - called on `qwak build .. from cli` at build time.
|-- schema - specifies model inputs and outputs
|-- initialize_model - invoked when model is loaded at serving time.
|-- predict - invoked on each request to the deployment's endpoint.
! Important
The predict method is decorated with qwak.api() which provides qwak_analytics
on model inference requests.
These are under main folder and represent the required schema such that our model can pass the build.
Apart from that, we have the:
tests: folder to group our custom unit tests and integration tests.test_local_model.py: deploys our model locally and tests the model integrity and workflow.test_live_model.py: once the model is remotely deployed on Qwak, we can test it using this script.
🔗 More insights on using Qwak from the team. Qwak Publication [3]
Mistral7b-Instruct LLM Model
As mentioned above, we’ll fine-tune a Mistral7b-Instruct [10] model in our LLM-Twin course use case.
Model Card
Mistral 7B is a 7 billion parameter LM that outperforms Llama 2 13B on all benchmarks and rivals Llama 1 34B in many areas. It features Grouped-query attention for faster inference and Sliding Window Attention for handling longer sequences efficiently. It’s released under the Apache 2.0 license.
Hugging Face Setup
To be able to download the model checkpoint, and further use it for fine-tuning, we need a Hugging Face Access Token. Here’s how to get it:
- Log-in to HuggingFace [9]
- Head over to your profile (top-left) and click on Settings.
- On the left panel, go to
Access Tokensand generate a new Token - Save the Token
We’ll set this token as a env variable in our fine-tuning setup.
Tokenizer Special Tokens
Before diving into the fine-tuning module and functionality, let’s get a refresher on what the special tokens represent and why they differ for LLM models.
If we go to Mistral7b-Instruct [10] model page and select Files and Versions we’ll get prompted to this view:
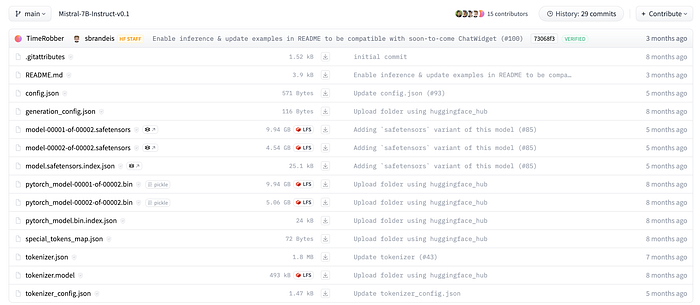
For Mistral7b Instruct, the special_tokens_map.json includes the following tokens "bos_token": "<s>", "eos_token": "</s>", and "unk_token": "<unk>". These tokens define the start and end delimiters for prompts.
For the Instruct model version of Mistral, two new tokens [INST] and [/INST] are used within the prompt scope <s>[INST]....[/INST]</s>. Since the model is instruction-based, these tokens help separate the instructions, improving the model’s ability to understand and respond to them effectively.
The Finetuning Pipeline
Now that we’ve covered the fundamentals of each topic, let’s put them all together and cover the implementation and fine-tuning process.
System Design
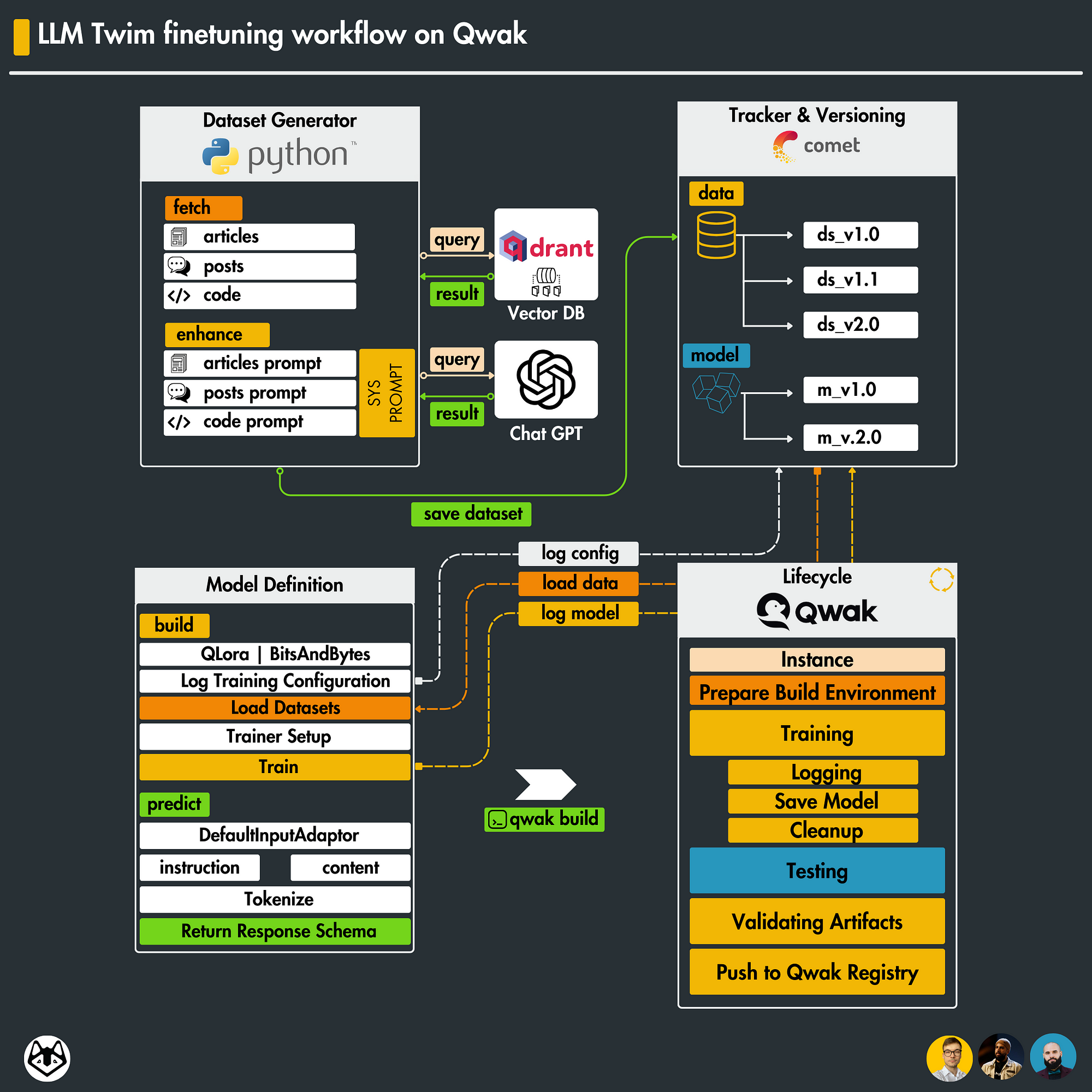
The fine-tuning process bases itself on the following system design.
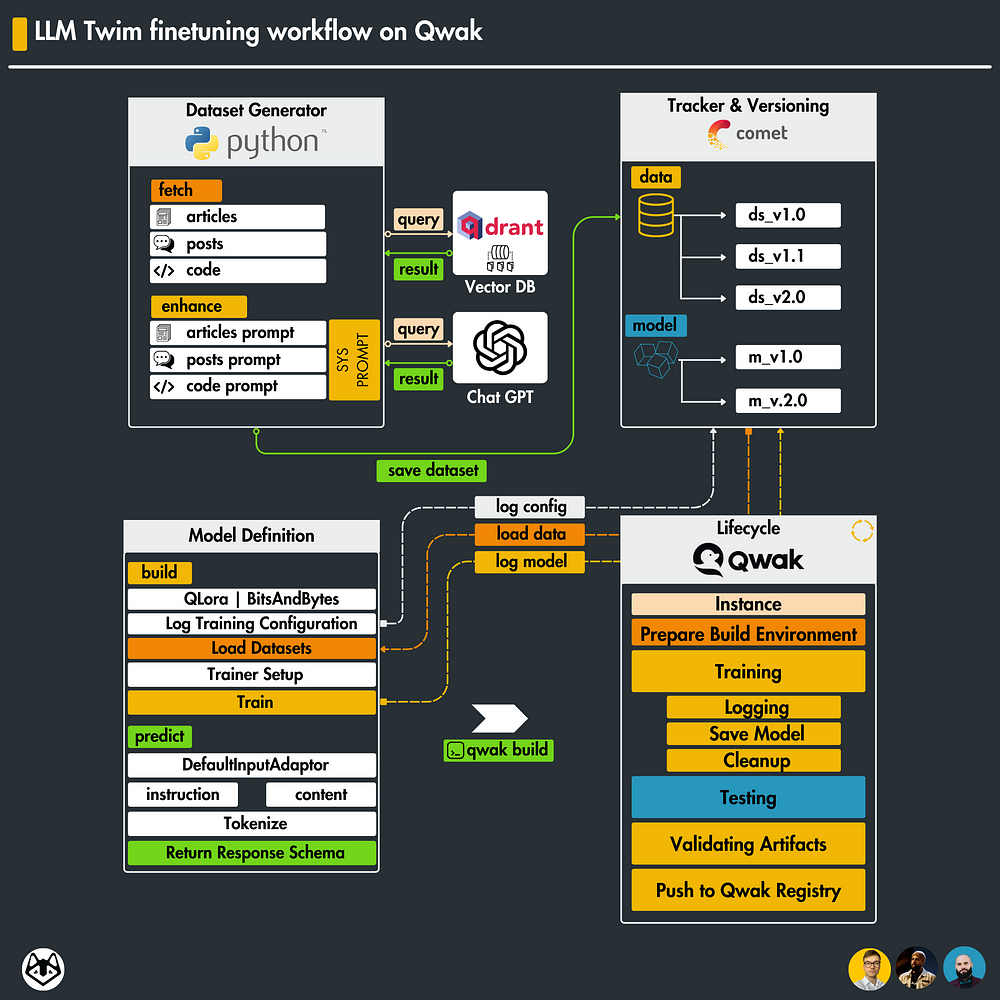
We have our prepared dataset files versioned in CometML [11], from the previous lesson.
We implement the Model Schema and the fine-tuning logic following the Qwak Model Blueprint.
When a build is triggered, we deploy our model, fetch the data, fine-tune the model, and log parameters to CometML.
Implementation
As the starting point, here’s how our fine-tuning module’s folder structure would look like:
|--finetuning/
| |__ __init.py__
| |__ config.yaml
| |__ dataset_client.py
| |__ model.py
| |__ requirements.txt
| |__ settings.py
|
|__ .env
|__ build_config.yaml
|__ Makefile
|__ test_local.py
For the Qwak[2] remote deployment, we would focus only on what’s under the finetuning folder, as the rest of the files are applicable only on development environment.
Let’s start unpacking them, one by one:
- The
config.yamlcontains the training parameters for our model.
training_arguments:
output_dir: "mistral_instruct_generation"
max_steps: 10
per_device_train_batch_size: 1
logging_steps: 10
save_strategy: "epoch"
evaluation_strategy: "steps"
eval_steps: 2
learning_rate: 0.0002
fp16: true
remove_unused_columns: false
lr_scheduler_type: "constant"
2. The dataset_client.py script holds the logic to interact with our project on CometML [11] and download the dataset artifacts.
Here, we’re using two main methods:
get_artifact— to connect to CometML and download the dataset artifacts.split_data— to load the downloaded dataset, and prepare train/val splits.
Our versioned dataset looks like this:
[
{
"instruction": "Design and build a production-ready feature pipeline.."
"content": "SOTA Python Streaming Pipelines for Fine-tuning LLMs and RAG \\u2014 in Real-Time!Use a Python streaming engine to populate a feature store ..."
},
...
{
"instruction": "Generate a publication that offers battle-tested content on building production-grade ML systems leveraging good SWE and MLOps practices...",
"content": DecodingML, The hub for continuous learning on ML system design, ML engineering, MLOps, LLMs and computer vision..."
}
]
🔗 Check the DatasetClient implementation for more details.
3. In model.py we’re wrapping our Mistral7b-Instruct model as a Qwak model, and implementing the required stages discussed above in the Qwak Build Cycle.
As a recap, here’s the QwakModel interface we’re going to implement:
class QwakModel:
"""
Base class for all Qwak based models.
"""
@abstractmethod
def build(self):
raise ValueError("Please implement build method")
@abstractmethod
def predict(self, df):
raise ValueError("Please implement predict method")
def initialize_model(self):
pass
def schema(self) -> ModelSchema:
pass
And here’s the method map of our model class:
class CopywriterMistralModel(QwakModel):
def __init__(
self,
is_saved: bool = False,
model_save_dir: str = "./model",
model_type: str = "mistralai/Mistral-7B-Instruct-v0.1",
comet_artifact_name: str = "cleaned_posts",
config_file: str = "./finetuning/config.yaml",
):
def _prep_environment(self):
def _init_4bit_config(self):
def _initialize_qlora(self, model: PreTrainedModel) -> PeftModel:
def _init_trainig_args(self):
def _remove_model_class_attributes(self):
def load_dataset(self) -> DatasetDict:
def preprocess_data_split(self, raw_datasets: DatasetDict):
def generate_prompt(self, sample: dict) -> dict:
def tokenize(self, prompt: str) -> dict:
def init_model(self):
def build(self):
def initialize_model(self):
def schema(self) -> ModelSchema:
@qwak.api(output_adapter=DefaultOutputAdapter())
def predict(self, df):
Diving into the model.py we start by defining the CopywriterMistralModel class and its constructor:
...
from qwak.model.base import QwakModel
class CopywriterMistralModel(QwakModel):
def __init__(
self,
is_saved: bool = False,
model_save_dir: str = "./model",
model_type: str = "mistralai/Mistral-7B-Instruct-v0.1",
comet_artifact_name: str = "cleaned_posts",
config_file: str = "./finetuning/config.yaml",
):
self._prep_environment()
self.experiment = None
self.model_save_dir = model_save_dir
self.model_type = model_type
self.comet_dataset_artifact = comet_artifact_name
self.training_args_config_file = config_file
if is_saved:
self.experiment = Experiment(
api_key=settings.COMET_API_KEY,
project_name=settings.COMET_PROJECT,
workspace=settings.COMET_WORKSPACE,
)
def _prep_environment(self):
os.environ["TOKENIZERS_PARALLELISM"] = settings.TOKENIZERS_PARALLELISM
th.cuda.empty_cache()
logging.info("Emptied cuda cache. Environment prepared successfully!")
We’re going to use constructor variables throughout the Qwak lifecycle methods.
Next, we have a series of methods to prepare the BitsAndBytes, QLora, and Training arguments.
In _init_4bit_config we’re instantiating the BitsAndBytes config that’ll allow us to run operations in lower precision during training — saving computing and time.
def _init_4bit_config(self):
self.nf4_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
bnb_4bit_compute_dtype=th.bfloat16,
)
if self.experiment:
self.experiment.log_parameters(self.nf4_config)
logging.info(
"Initialized config for param representation on 4bits successfully!"
)
In _initialize_qlora we’re adding QLoRAAdapter on top of our model to mark which layers we’re going to finetune.
def _initialize_qlora(self, model: PreTrainedModel) -> PeftModel:
self.qlora_config = LoraConfig(
lora_alpha=16, lora_dropout=0.1, r=64, bias="none", task_type="CAUSAL_LM"
)
if self.experiment:
self.experiment.log_parameters(self.qlora_config)
model = prepare_model_for_kbit_training(model)
model = get_peft_model(model, self.qlora_config)
logging.info("Initialized qlora config successfully!")
return model
In _init_training_args() we’re loading the training config and logging it to our CometML experiment.
def _init_trainig_args(self):
with open(self.training_args_config_file, "r") as file:
config = yaml.safe_load(file)
self.training_arguments = TrainingArguments(**config["training_arguments"])
if self.experiment:
self.experiment.log_parameters(self.training_arguments)
logging.info("Initialized training arguments successfully!")
In _remove_model_class_attributes we’re deleting the defined model, trainer and comet experiment to skip the serialization when building the Qwak artifact.
Next, we define the methods that’ll interact with the DatasetClient class and prepare our data for fine-tuning.
- The
generate_prompt()method wraps a data sample with Mistral7b Instruct special tokens:
def generate_prompt(self, sample: dict) -> dict:
full_prompt = f"""<s>[INST]{sample['instruction']}
[/INST] {sample['content']}</s>"""
result = self.tokenize(full_prompt)
return result
2. The load_dataset() handles our data preparation (download, split, and pre-process). In the end, we’ll have our fine-tuning samples as valid prompts with instruction/content fields ready for training.
def load_dataset(self) -> DatasetDict:
dataset_handler = DatasetClient()
train_data_file, validation_data_file = dataset_handler.download_dataset(
self.comet_dataset_artifact
)
data_files = {"train": train_data_file, "validation": validation_data_file}
raw_datasets = load_dataset("json", data_files=data_files)
train_dataset, val_dataset = self.preprocess_data_split(raw_datasets)
return DatasetDict({"train": train_dataset, "validation": val_dataset})
def preprocess_data_split(self, raw_datasets: DatasetDict):
train_data = raw_datasets["train"]
val_data = raw_datasets["validation"]
generated_train_dataset = train_data.map(self.generate_prompt)
generated_train_dataset = generated_train_dataset.remove_columns(
["instruction", "content"]
)
generated_val_dataset = val_data.map(self.generate_prompt)
generated_val_dataset = generated_val_dataset.remove_columns(
["instruction", "content"]
)
return generated_train_dataset, generated_val_dataset
In tokenize() we’re passing our prompt through the tokenizer.
In init_model(self) we’re connecting to HF and downloading the Mistral7B-Instruct checkpoint, setting the model and the tokenizer as class instance attributes.
Next up is the build method which encapsulates the overall fine-tuning process functionality.
def build(self):
self._init_4bit_config()
self.init_model()
if self.experiment:
self.experiment.log_parameters(self.nf4_config)
self.model = self._initialize_qlora(self.model)
self._init_trainig_args()
tokenized_datasets = self.load_dataset()
self.device = th.device("cuda" if th.cuda.is_available() else "cpu")
self.model = self.model.to(self.device)
self.trainer = Trainer(
model=self.model,
args=self.training_arguments,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
tokenizer=self.tokenizer,
)
logging.info("Initialized model trainer")
self.trainer.train()
logging.info("Finished model finetuning!")
self.trainer.save_model(self.model_save_dir)
logging.info(f"Finished saving model to {self.model_save_dir}")
self.experiment.end()
self._remove_model_class_attributes()
logging.info("Finished removing model class attributes!")
Here, we’re doing the following:
- Prepare the BitsAndBytes config, log it to CometML [11], and initialize the model.
- Apply the QLoRAAdapter and prepare training arguments from our defined
config.yaml. - Instantiate the Transformer’s
Trainerclass that wraps the model training loop functionality. - Train the model using
self.trainer.train().
Now that we’ve covered the implementation details, let’s see how to trigger the process and deploy this on Qwak [2].
Deployment on Qwak
Before the actual deployment, let’s make sure we have created a new project and model in Qwak and have populated the required env variables set in place.
Create a new Qwak model and project, names which we’ll use when configuring the build_config.yaml .
qwak models create "ModelName" --project "ProjectName"
Next, let’s populate the environment variables.
HUGGINGFACE_ACCESS_TOKEN: str = ""
COMET_API_KEY: str = ""
COMET_WORKSPACE: str = ""
COMET_PROJECT: str = ""
In order to get the CometML-related variables, head over to CometML [11] and log in. The next step is to create a New Project using the button on the top left corner. You’ll be prompted to this view:

Once you’ve created a project, populate the COMET_PROJECT env variable.
To get the COMET_WORKSPACE , copy the name on the right of the Comet’s logo, in my case is joywalker .

To generate a new API_KEY , in your Comet dashboard, go to your profile, select API Key, click on Manage API Keys, and generate a new key.
We’re all set!
Let’s now check how the build_config.yaml streamlines our Qwak deployment with a single command.
build_env:
docker:
assumed_iam_role_arn: null
base_image: public.ecr.aws/qwak-us-east-1/qwak-base:0.0.13-gpu
cache: true
env_vars:
- HUGGINGFACE_ACCESS_TOKEN="your-hf-token"
- COMET_API_KEY="your-comet-key"
- COMET_WORKSPACE="comet-workspace"
- COMET_PROJECT="comet-project"
no_cache: false
params: []
push: true
python_env:
dependency_file_path: finetuning/requirements.txt
git_credentials: null
git_credentials_secret: null
poetry: null
virtualenv: null
remote:
is_remote: true
resources:
cpus: null
gpu_amount: null
gpu_type: null
instance: gpu.a10.2xl
memory: null
build_properties:
branch: finetuning
build_id: null
model_id: "your-model-name"
model_uri:
dependency_required_folders: []
git_branch: master
git_credentials: null
git_credentials_secret: null
git_secret_ssh: null
main_dir: finetuning
uri: .
tags: []
deploy: false
deployment_instance: null
post_build: null
pre_build: null
purchase_option: null
step:
tests: true
validate_build_artifact: true
validate_build_artifact_timeout: 120
verbose: 0
Let’s unpack this Qwak deployment configuration file:
- We’re starting from a
qwak-sdkbuild the image with GPU - Under the
python_envtag we’re specifying how to install container requirements. - Under the
remote:resourcestag we’re specifying the instance type we want the deployment to be scheduled on. - Under the
build_propertieswe’re specifying the root path of where our QwakModel definition is (e.g in the finetuning folder) usingmodel_uri:main_dir. - We don’t run any pre-build or post-build functionality.
- Under the
steptag we’re selecting to runtestsand to validate the Qwak artifacts once theBuildstage is done.
The
validate_build_artifactwill run once build is complete. It wraps the deployment container and checks it’s health, ensuring it can be deployed correctly.
Now, to trigger the build on Qwak [2], we would use the pre-defined command in our Makefile qwak models build -f build_config.yaml
Below, you can find a snapshot of the Running Build function stage on Qwak.

Experiment Tracking with Comet
Once we’ve successfully deployed the fine-tuning module, let’s inspect the Experiments we’ve tracked on CometML [11].

Upon selecting an experiment, we’re prompted to a detailed view with the parameters, code, metrics, and other metadata fields and artifacts we’ve logged.
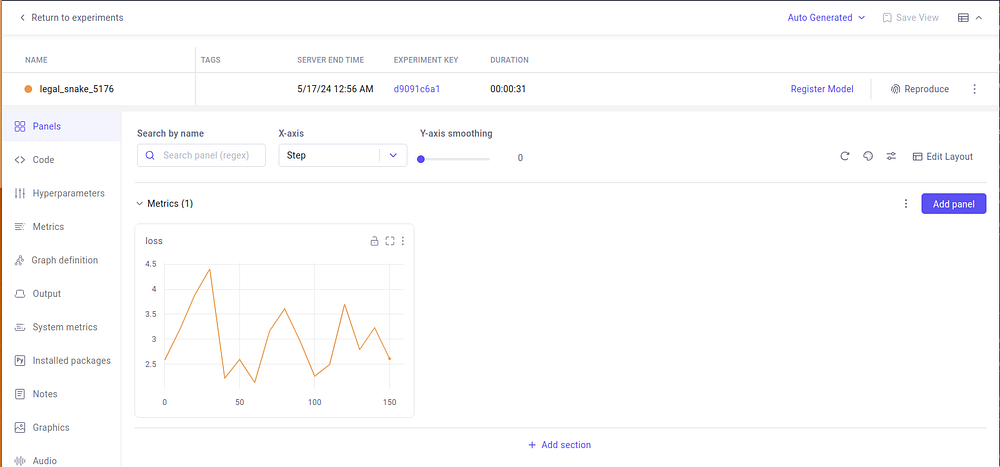
Here, we can inspect:
- The model definition summary of layers and modules using
Graph definition - Hyperparameters and Metrics logged.
- System metrics (GPU, CPU usage upon active experiment run)
- Code changes
- And many more…
The key components are the Charts and Panels that will help us monitor the fine-tuning process. In this case, the training loss is logged automatically by Comet as it can inter-communicate with the executed Pytorch code.
ℹ️ To enable comet package to log everything automatically by default, make sure you import
comet_mlbefore importingtorchin your script.
Comparing Experiments
Let’s see how we can compare multiple experiments to identify the key set of parameters and insights from the fine-tuning process.
Check desired experiments and select Compare.

This will overlap the experiments and provide a common view, that makes it easier to spot key insights from the training process.

Next, let’s add another panel and populate it with other metrics. We’ll select validation_loss . To do that, click on Add Panel select the Line Chart type and under the Y-Axis select eval_loss and then Done.

One more very useful feature that Comet offers is — Code Diff, where you get a git-like interface to compare code changes between the experiments.
Here’s how it looks:

With all the features it offers, the extensibility of the UI dashboard as well as the dev experience, CometML [11] takes a top spot in the MLOps Lifecycle Modelling Stage.
Ending Notes and Conclusion
Here we’re wrapping up Lesson 7 of the LLM Twin free course.
In this lesson, we’ve covered the end-to-end fine-tuning process for a Mistral7b-Instruct model, while using MLOps recommended practices of versioning, containerization, reproducibility, and experiment tracking.
We’ve also covered in detail not one, but two powerful MLOps platforms, CometML [11] to track our Experiments and help us monitor the parameters, datasets, code changes, and metrics as well as Qwak [2] to encapsulate and easily deploy our fine-tuning workflow with just a few clicks.
Completing Lesson7, you’ve gained a good understanding of the fine-tuning, and data preparation for a Mistral7b-Instruct model as well as in-detail topics like special-tokens, reducing model size, Peft, BitsAndBytes, and LoRA.
Alongside, you’ve learned to use CometML to track/compare training experiments and Qwak to encapsulate and deploy training/inference for LLM workloads to the cloud with just a few lines of code and a smooth dev experience.
In Lesson 8, we’ll cover the evaluation topic. We’ll discuss common evaluation techniques, and traditional metrics, and dive into production-stage recommendations on the topic. See you there!
🔗 Check out the code on GitHub [1] and support us with a ⭐️
Related Articles


