Model Monitoring: The Missing Piece to Your MLOps Puzzle
Here we share a comprehensive guide to model monitoring in production.
Table of Contents
Introduction: Will this guide be helpful to me?
This guide will be helpful to you if you are:
The MLOps Lifecycle
MLOps is a set of management techniques for the deep learning or production ML lifecycle, formed from machine learning or ML and operations or Ops. These include ML and DevOps methods, as well as data engineering procedures meant to effectively and reliably install and maintain ML models in production. MLOps promotes communication and cooperation between operations experts and data scientists to accomplish successful machine learning model lifecycle management.
The MLOps lifecycle consists of:
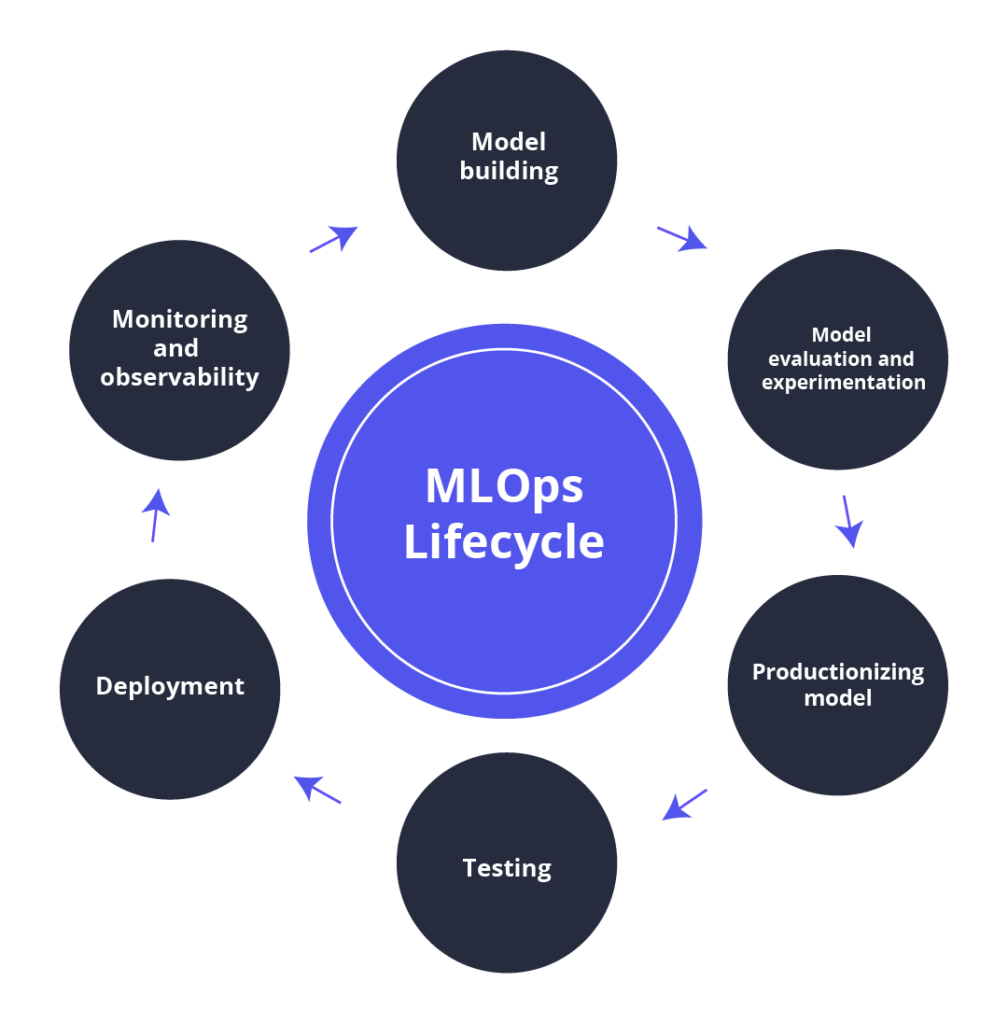
Don’t Stop at Deployment. Here’s Why.
The cycle does not end once the model has been trained, tested, and deployed. We must guarantee that the deployed model works in the long run and keep an eye out for any issues.
After the deployment phase, you should ensure the continuous delivery and data feedback loop.
Challenges in Monitoring the ML Lifecycle
ML workflow is divided into several stages, which we’ll review in detail below.
But why should you keep track of your models?
To address this question, consider some of the production challenges your model may face:
1. Data Distribution Changes
Key questions: Why are the values of my features suddenly changing?
2. Model Ownership
Key questions: Who owns the production model? The DevOps team? Data scientists? Engineers?
3. Training-Serving Skew
Key questions: Why, despite our intensive testing and validation efforts throughout development, is the model producing poor outcomes in production?
4. Model or Concept Drift
Key questions: Why was my model doing well in production before abruptly deteriorating over time?
5. Black Box Models
Key questions: How can I evaluate and communicate my model’s predictions to important stakeholders per the business objective?
6. Concerted Adversaries
Key questions: How can I secure my model’s safety? Is my model under attack?
7. Model Readiness
Key questions: How will I compare findings from a newer version(s) of my model to those from the current version(s)?
8. Pipeline Health Issues
Key questions: Why is my training pipeline failing to execute? Why does it take so long to complete a retraining job?
9. Data Quality Issues
Key questions: Why is my training pipeline failing to execute? Why does it take so long to complete a retraining job?
10. Underperforming System
Key questions: Why is my predictive service latency so high? Why am I receiving such a wide range of latencies for my different models?
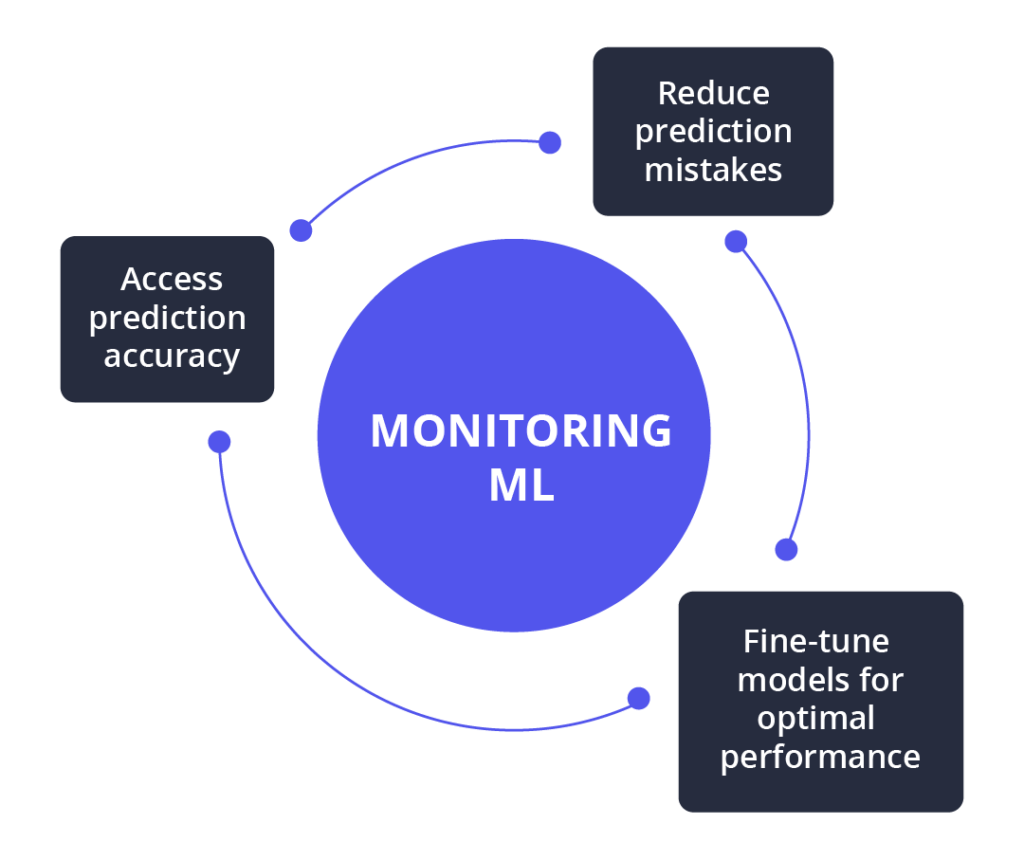
Why You Need Model Monitoring in ML
There are several reasons to monitor machine learning models. It allows you to assess prediction accuracy, reduce prediction mistakes, and fine-tune models for optimal performance.
Eliminate Poor Generalization
A machine learning model is often trained on a restricted portion of the total in-domain data due to a lack of labeled data or other computational restrictions. Even though the approach is designed to eliminate bias, the practice results in poor generalization. As a result, the sample of output data will be wrong or inefficient. This problem can be resolved by using monitoring models. It enables you to build models that are balanced and precise without overfitting or underfitting the data.
Eliminate the Issue of Changing Parameters Over Time
The variables and parameters at a certain period are used to optimize a model. By the time the model is deployed, the same parameters will be irrelevant. A sentiment model constructed 5 years ago, for example, may incorrectly categorize the emotion of particular words or phrases. As a result, the forecast will be inaccurate. Model monitoring helps you to resolve the issue by analyzing how a model performs on real-world data over time.
Ensure the Stability of Prediction
The machine learning model’s input isn’t independent. As a result, modifications in any aspect of the system, including hyper-parameters and sampling methods, might result in unexpected results. Model monitoring guarantees that predictions are very stable by measuring several stability measures such as the Population Stability Index (PSI) and Characteristic Stability Index (CSI).
Model Monitoring vs. Observability: What’s the Difference
One commonly asked question is, “I already monitor my data.” “Why do I require observability as well?”That’s an excellent question. Monitoring and observability have long been used interchangeably, although they are not the same thing.
Data observability enables monitoring, which most technical practitioners are familiar with: we want to be the first to know when anything fails and to solve it as soon as possible. Data quality monitoring functions similarly, notifying teams when a data asset appears to be different from what the specified measurements or parameters indicate.
Data monitoring, for example, might provide an alert if a number fell outside of an expected range, data was not updated as planned, or 100 million rows suddenly became 1 million. However, before you can monitor a data ecosystem, you must have insight into all of the properties we’ve just discussed — this is where data observability comes in.
Data observability also facilitates active learning by giving granular, in-context data insights. Teams can investigate data assets, analyze schema modifications, and pinpoint the source of new or unforeseen problems. Monitoring, on the other hand, generates alerts based on pre-defined concerns and represents data in aggregates and averages.
Best Practices in Monitoring ML Models in Production
You should keep the following points in mind to ensure the success of your machine learning model in real life:
1. Data Distribution Shifts
Over time, model performance might decline due to data drift. Monitoring the inputs to your model can allow you to detect these drifts swiftly. When a data drift happens, it is best practice to then re-train the model on the data it wasn’t performing well on to improve generalization.
2. Performance Shifts
Model monitoring allows you to track changes in performance. As a consequence, you can assess the model’s performance. It also teaches you how to efficiently debug if something goes wrong.
3. Data Integrity
The dependability of data throughout its lifespan is referred to as data integrity. You must check that the information is correct. There are other approaches, including error checking and validation.
It Doesn’t Stop Here: Going Beyond Monitoring
Continuously improving your models does not end with ML monitoring; delve deeper to genuinely understand your models with ML Observability, which includes ML monitoring, validation, and troubleshooting to improve model performance and boost AI ROI. ML Observability enables your teams to automatically discover model flaws, diagnose difficult-to-find errors, and enhance your models’ performance in production.
Frequently Asked Questions (FAQs)
The best tools for ML model monitoring are Anodot, Fiddler, and Google Cloud AI Platform.
Documentation is important in ML model monitoring as it guarantees that the model has enough computational resources to handle inference workloads.
You can monitor what might go wrong with your machine learning model in production at two different levels:
The most optimal model metric to utilize is determined mostly by the type of model and the distribution of the data it is predicting.
While dedicated and expert annotators can help in the model monitoring stage, you don’t need to have them.
The rising expenses of audits and compliance reviews are putting pressure on organizations to develop a cost-effective and long-term method of confirming control performance. The monitoring stage in MLOps automates internal controls testing across the enterprise’s major financial and operational operations.