Machine Learning Operations
Comet’s Handbook on the MLOps Pipeline
Table of Contents
- What Makes a Good MLOps Pipeline?
- Things That Slow Down Your MLOps Flow
- How Can You Improve Your ML Operations?
- Levels of MLOps Maturity
- How to Automate Your MLOps Pipeline?
- FAQs
Organizations of all sizes are reaping big from feeding their operational data into powerful machine learning models to increase efficiency and boost revenue. However, creating and maintaining an MLOps pipeline can be time-consuming, error-prone, and capital-intensive. Above all, it pulls your team away from performing high-value work. Machine learning operations (MLOps) main goal is to change that.
MLOps aims to automate the process of creation and maintenance of AI/ML models that ranges from data and feature engineering to model development to model deployment and monitoring. This helps achieve reproducibility, scale, and governance required to effectively execute machine learning initiatives.
In this guide, we will cover everything you need to know about the MLOps pipeline to help you work efficiently and effectively. We will also look at the tools and platforms to help you optimize your ML workflow for optimal results.
What Makes a Good MLOps Pipeline?
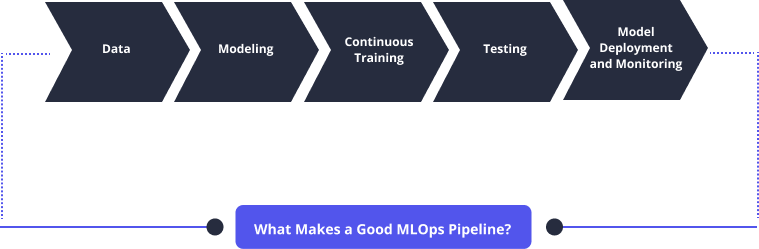
MLOps pipelines are crucial steps triggered to automatically design, deploy, and manage model workflows. By doing so, they help free up valuable time and resources that may be channeled to other critical areas of the business. A good MLOps pipeline should feature several things including:
Data: MLOps is more experimental in nature. It takes in highly complex data inputs, which need to be transformed so that ML models can produce meaningful predictions.
Modeling: ML experimentation process is necessary to develop good systems. In this step, data scientists focus on generating a lot of ideas and validating them. Tracking data changes and parameters of every experiment is essential for the success of this step.
Continuous Training: ML models need to be consistently trained as new data becomes available. This helps prevent model drift and speed up time to production. Training becomes critically important when the number of experiment runs becomes large, making the manual management of these runs and resources unmanageable.
Testing: This process is done to verify the trained model. It involves model training, model validation, and so on in addition to conventional code tests, including unit testing (where small, testable parts of an app are tested independently and integration testing.
Model Deployment and Monitoring: Before you start development, it’s important to know the type of deployment you’re going to use. Components such as business use-case, availability of resources, and organizational scaling need to be considered when deploying a model.
Note that MLOps strategy follows continuous integration and delivery principle similar to DevOps. The only difference is that for the machine learning pipeline, the data is modified along with the models. MLOps can also help deploy a multi-step pipeline that can automatically retain and deploy a model.
After deploying the model, it’s important to monitor its performance to see if it works as expected. This helps prevent concept shift- where if the ML model is left to run on its own, eventually it falls out of step with its inputs, leading to bad and inaccurate responses. Monitoring also helps us discover any changes in data or the relationship between inputs and the target variables.
Things That Slow Down Your MLOps Flow
For most businesses, the development of ML models and their deployment in production is a new endeavor. A small number of models is manageable. However, with the increased prevalence of decision-making that often happens without human intervention, these models may become more critical.
Scaling machine learning projects is essential. It allows both your organization and larger populations to use your models. Today, many data teams build and develop scalable applications that work for millions of people worldwide. MLOps simplifies scalability through ML apps’ containerization, orchestration, and distribution. However, working on large-scale ML projects can take time because of several factors.
Here are things that may slow down your MLOps pipeline:
1. Data Discrepancies
Critical data need to be sourced from multiple sources which may lead to a lot of mismatches in data values and formats. For example, current data can be sourced directly from a pre-existing product, while old data can be taken from the client. Similarly, discrepancies in mappings especially when data is not evaluated properly, can disrupt the whole process.
2. Changing Business Objectives Within the Model
Not only does data change constantly, but business needs to change too. During this stage, there are many dependencies to ensure the AI governance and that the data maintain performance standards within the model. In this case, the stakeholders should be informed about the ML model to make sure that its performance aligns with the expectation and meets the original goal. It’s hard to keep up with the constant model training and evolving business needs which may slow down the MLOps flow.
3. Challenge In the Integration of workflows
ML data pipelines should be flexible enough to handle evolving data needs over time. Advanced ML pipelines to support quick integration are sometimes not implemented. This includes capabilities such as automated retraining of the model, monitoring during production for drift, enabling centralized feature engineering and data cleaning, and more.
How Can You Improve Your ML Operations?
A few years ago, maintaining an ML operation system may have been considered a difficult task. But today, ML is no longer siloed from the rest of the organization and needs to evolve along with your solution. This means operationalizing and actively maintaining your ML pipelines.
Here are a few tips you can focus on to improve your ML operations.
1. Identify Your MLOps Level of Maturity
Maturity models in MLOps focus on obtaining an efficient model in production that is continuously improved, integrated, and developed in the lifecycle to provide the expected results as required in the environment. Maturity models can be used as an evaluation metric for establishing the progressive requirements needed to assess the maturity of the MLOps model in production and its ability to adapt to the production environment. It also helps to identify gaps in an existing business’s attempt to implement an MLOps environment.
MLOps maturity models can also be used to estimate the current scope of work and identify possible criteria to achieve success, thus enabling you to make the right decision. This allows you to grow your MLOps capability steadily instead of being overwhelmed with the requirements of a fully mature environment.
2. Integrate Unified Systems
MLOps aims to integrate and unify the entire machine learning lifecycle that includes the software development stage and integration with mode generation such as continuous Integration and continuous delivery, orchestration, deployment, governance, diagnostics, as well as analysis of organization metrics. The outcome is an independent approach to machine learning lifecycle management including an ML engineering process that deploys DevOps methods for a machine learning environment, which unifies MLOps. ML operation systems create adaptable, dynamic, scalable ML production pipelines that flex to accommodate KPI-driven models.
3. Reduce Friction
MLOps reduce technical friction and problems between ML development and operation team to operationalize models. It opens up bottlenecks, especially those that often occur when complicated niche ML models are siloed in development. This allows the team to get the model from an idea into production in the shortest time to market with less risk.
Levels of MLOps Maturity
Successful MLOps adoption needs a thorough assessment of the organization’s progress in its MLOps maturity. Once a reliable assessment of maturity level is done, the organization can understand the right strategies they can use to move up the maturity level.
Here are the key maturity levels involved in MLOps.
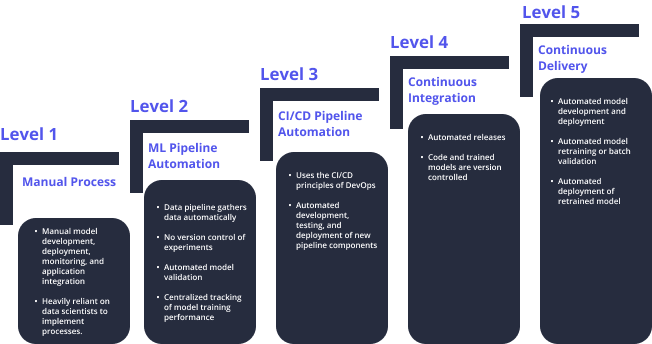
1. Manual Process
In this process, every step in each pipeline including model creation (data preparation and validation), model training and testing, as well as application integrations are done manually. This process is heavily reliant on data scientists to implement all the processes. The process is executed using Rapid Application Development (RAD) tools. Deployment and monitoring are also done manually.
2. ML Pipeline Automation
At this level, the execution of ML is automated with continuous training of the model taking place which makes the environment fully managed and traceable. The data pipeline gathers and prepares data automatically with no version control of experiments. When new data is available, the process of model retraining is initiated. ML pipeline automation also includes data and model validation stages as well as centralized tracking of model training performance.
3. CI/CD Pipeline Automation
Two key DevOps ideas, continuous integration (CI) and continuous delivery (CD) may also be used for MLOps. Organizations can use CI/CD to automate the development, testing, and deployment of the new pipeline components to the designated environment. Automated CI/CD also allows data scientists to quickly and reliably update the pipelines in production and also explore new ideas in model architecture, feature engineering, and hyperparameters.
4. Continuous Integration
During the continuous integration process in the pipeline, the ML pipeline and its components are built, tested, validated, and packaged for delivery every time a new code or data changes are attempted on the source code repository (in most cases Git-based). It’s done in such a manner that everything is versioned and reproducible, to ensure it’s easy to share the code across projects and teams.
During this process, you may encounter tests such as unit testing for feature engineering methods, integration testing, data and model tests, as well as confirmation tests to find out if each component produces the required result.
5. Continuous Delivery
The continuous delivery method automates the pipeline deployment process of machine learning models which in turn conduct continuous training (CT) of ML models for effective prediction. During this process, the already deployed machine learning pipeline is triggered automatically for model retraining or batch validation based on triggers from the live ML pipeline environment.
Factors such as degradation of model performance or concept drift (changes in data distributions for features used for prediction) can trigger model retraining. The ML model that is already tested and trained is then deployed automatically as part of the model’s continuous delivery process.
How to Automate Your MLOps Pipeline?
Effective developing, deploying, and continuously improving ML models requires automation of the MLOps pipeline. The most critical MLOps best practices that organizations must adopt to achieve this include pipeline to create advanced machine learning systems collaboratively, versioning to make sure there is the reproducibility of models, testing to ensure the production models meet the required standards, and automation to save time and provide efficient systems.
To successfully implement MLOps in your pipeline, different tools are needed. Comet is a meta ML platform that allows you to track, monitor, optimize, and deploy ML models. It allows you to see and compare all your experiences in a single place. Organizations, teams, individuals, and anyone else can easily visualize experiments and facilitate work and run experiments.
Not sure where to start with the implementation of your MLOps pipeline? Reach out to our team today to help you get started!
Frequently Asked Questions (FAQs)
What is the difference between an MLOps pipeline and lifecycle?
MLOps pipelines involve sequential steps that are activated to create, deploy, and manage ML model workflows automatically. MLOps lifecycle, on the other hand, involves the entire machine learning process including development and integration with model generation such as CI and CD, deployment, planning, governance, monitoring, and analysis of organizational metrics.
What makes an MLOps pipeline inefficient?
Key factors that may make an MLOps pipeline to be inefficient are data discrepancies especially silos, changes in business objectives, and problems with the integration of workflows.
When should ML teams revamp or level up their pipeline?
When they want to eliminate discrepancies in information structure and shorten the time it takes to get started on a new project. The team should also revamp their pipeline scale their models and focus on new ones or even shift from a one-time model phase and go for the real-time automated one.
Why should teams invest in improving their MLOps pipeline?
MLOps pipeline simplifies the delivery of ML models by combining processes of creation, development, testing, and delivery into one process. This allows the teams to release new machine learning capabilities quickly and efficiently.
Are there different types of MLOps pipelines?
The entire MLOps pipeline involves three key phases of designing the machine learning app (requirement engineering), development and experimentation (data engineering, model testing, and validation), and ML operations (model deployment, CI/CD pipelines, monitoring).