Machine Learning Operations
Machine Learning Lifecycle: What Every Data Scientist Should Know
There’s no one formula for developing machine learning models, but most ML projects follow a set of standard—and cyclical—steps.
In this article, we’ll explain what the machine learning lifecycle is, describe how it works, and explain how best to develop ML models from ideation to production.
Table of Contents
- What Is the Machine Learning Lifecycle?
- Why Is the Machine Learning Lifecycle Important?
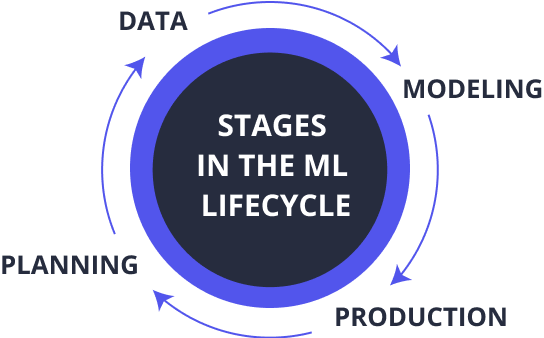
- Stages in the ML Lifecycle
- What Happens After Production
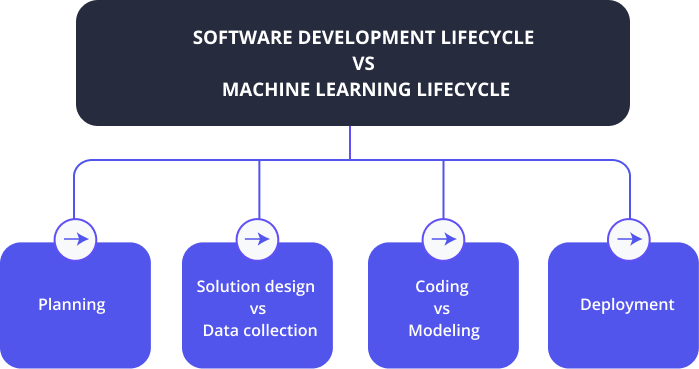
- Machine Learning Lifecycle vs Software Development Lifecycle
- Data Privacy Concerns During Data Collection
- Challenges Teams Face in an ML Lifecycle
- Best Practices for ML Lifecycle Management: MLOps
- Top Programming Languages for Machine Learning
- FAQs