Why software engineering processes and tools don’t work for machine learning
“AI is the new electricity.” At least, that’s what Andrew Ng suggested at this year’s Amazon re:MARS conference. In his keynote address, Ng discussed the rapid growth of artificial intelligence (AI) — its steady march into industry after industry; the unrelenting presence of AI breakthroughs, technologies, or fears in the headlines each day; the tremendous amount of investment, both from established enterprises seeking to modernize (see: Sony, a couple of weeks ago) as well as from venture investors parachuting into the market riding a wave of AI-focused founders.
“AI is the next big transformation,” Ng insists, and we’re watching the transformation unfold.
While AI may be the new electricity (and as a Data Scientist at Comet, I don’t need much convincing), significant challenges remain for the field to realize this potential. In this blog post, I’m going to talk about why data scientists and teams can’t rely on the tools and processes that software engineering teams have been using for the last 20 years for machine learning (ML).
The reliance on the tools and processes of software engineering makes sense – data science and software engineering are both disciplines whose principal tool is code. Yet what is being done in data science teams is radically different from what is being done in software engineering teams. An inspection of the core differences between the two disciplines is a helpful exercise in clarifying how we should think about structuring our tools and processes for doing AI.
At Comet, we believe the adoption of tools and processes designed specifically for AI will help practitioners unlock and enable the type of revolutionary transformation Ng is speaking about.
Different Disciplines, Different Processes
Software engineering is a discipline whose aim is, considered broadly, the design and implementation of programs that a computer can execute to perform a defined function. Assuming the input to a software program is within the expected (or constrained) range of inputs, its behavior is knowable. In a talk at ICML in 2015, Leon Bottou formulated this well: in software engineering an algorithm or program can be proven correct, in the sense that given particular assumptions about the input, certain properties will be true when the algorithm or program terminates.
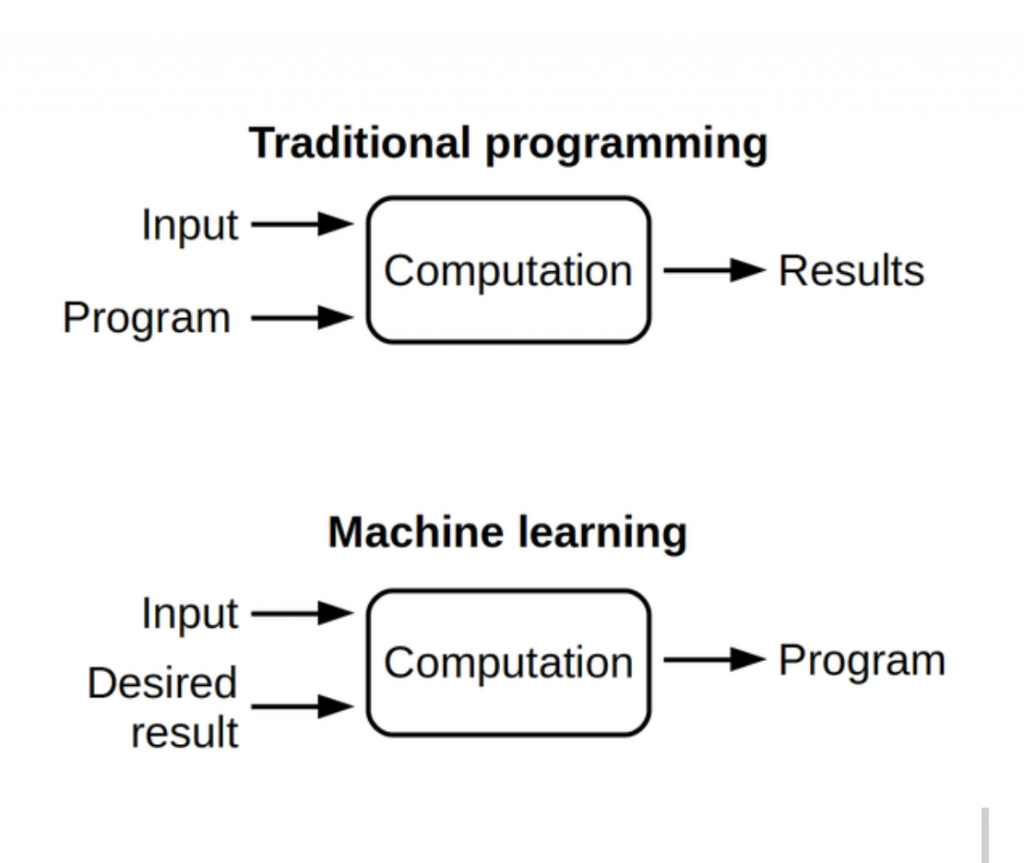
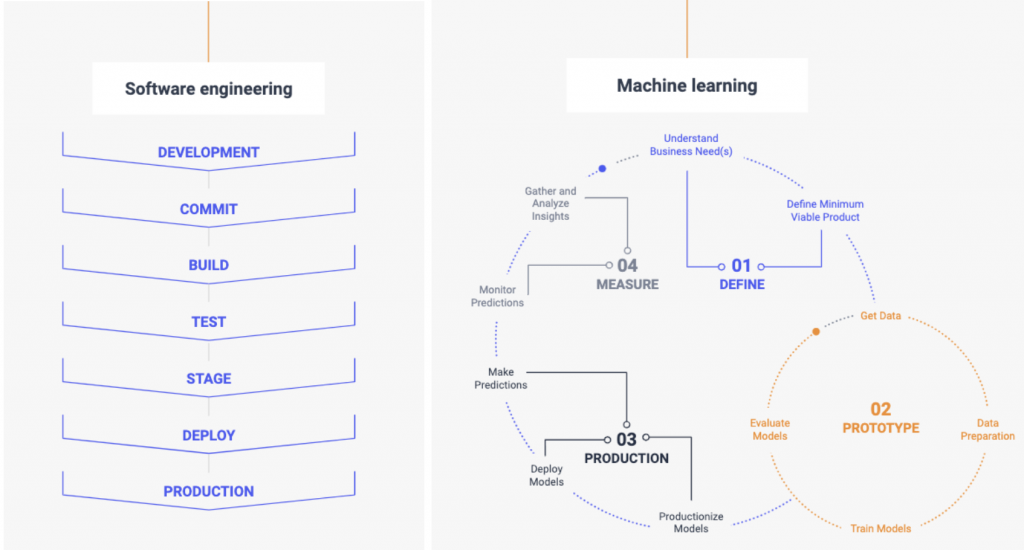
We see a lot of data science teams using workflow processes that are identical or broadly similar to these software methodologies. Unfortunately, they don’t work very well. The reason? The provable correctness of software engineering does not extend to AI and machine learning. In (supervised) machine learning, the only guarantee we have about a model we’ve built is that if the training set is an iid (independent and identically distributed) sample from some distribution, then performance on another iid sample from the same distribution will be close to the performance on the training set. Because uncertainty is an intrinsic property of machine learning, sub-tasking can lead to unforeseeable downstream effects.
Why is uncertainty intrinsic to machine learning?
Part of the answer lies in the fact that the problems that are both (a) interesting to us and (b) amenable to machine learning solutions (self-driving cars, object recognition, labeling images, and generative language models, to name a few) do not have a clear reproducible mathematical or programmatic specification. In place of specifications, machine learning systems feed in lots of data in order to detect patterns and generate predictions. Put another way, the purpose of machine learning is to create a statistical proxy that can serve as a specification for one of these tasks. We hope our collected data is a representative subsample of the real-world distribution, but in practice we cannot know exactly how well this condition is met. Finally, the algorithms and model architectures we use are complex, sufficiently complex that we cannot always break them apart into sub-models to understand precisely what is happening.
From this description, obstacles to the knowability of machine learning systems should be somewhat obvious. Inherent to the types of problems amenable to machine learning is a lack of a clear mathematical specification. The statistical proxy we use in the absence of a specification is accumulating lots of environmental data we hope is iid and representative. And the models we use to extract patterns from this collected data are sufficiently complex that we cannot reliably break them apart and understand precisely how they work. My colleague at Comet, Dhruv Nair, has written a three-part series on uncertainty in machine learning (here’s a link to Part I) if you’d like to dig deeper into this topic.
Consider, then, the implications for something like the Agile methodology used on a machine learning project. We cannot possibly hope to break machine learning tasks into sub-tasks, tackled as part of some larger sprint and then pieced together like legos into a whole product, platform, or feature, because we cannot reliably predict how the sub-models, or the model itself, will function.

Ng discussed this topic at re:MARS as well. He revealed how his team adopted a workflow system designed specifically for ML: 1 day sprints, structured as follows:
- Build models and write code each day
- Set up training and run experiments overnight
- Analyze results in the morning and…
- Repeat
Ng’s 1 day sprints methodology reflects something crucial to understanding and designing teams that practice machine learning: it is an inherently experimental science. Because the systems being built lack a clear specification, because data collection is an imperfect science, and because machine learning models are incredibly complex, experimentation is necessary. Rather than structuring team processes around a multi-week sprint, it is usually more fruitful to test out many different architectures, feature engineering choices, and optimization methods rapidly until a rough image of what is working and what isn’t starts to emerge. 1 day sprints allow teams to move quickly, test many hypotheses in a short amount of time, and begin building intuition and knowledge around a modeling task.
Tools for ML: Experiment Management
Let’s say you adopt Andrew Ng’s 1 day sprints methodology or something similar (and you should). You’re setting new hyperparameters, tweaking your feature selections, and running experiments each night. What tool are you using to keep track of these decisions for each model training? How are you comparing experiments to see how different configurations are working? How are you sharing experiments with co-workers? Can your manager or co-worker reliably reproduce an experiment you ran yesterday?
In addition to processes, the tools you use to do machine learning matter as well. At Comet, our mission is to help companies extract business value from machine learning by providing a tool that does this for you. Most of the data science teams we speak to are stuck using a combination of git, emails, and (believe it or not) spreadsheets to record all of the artifacts around each experiment.
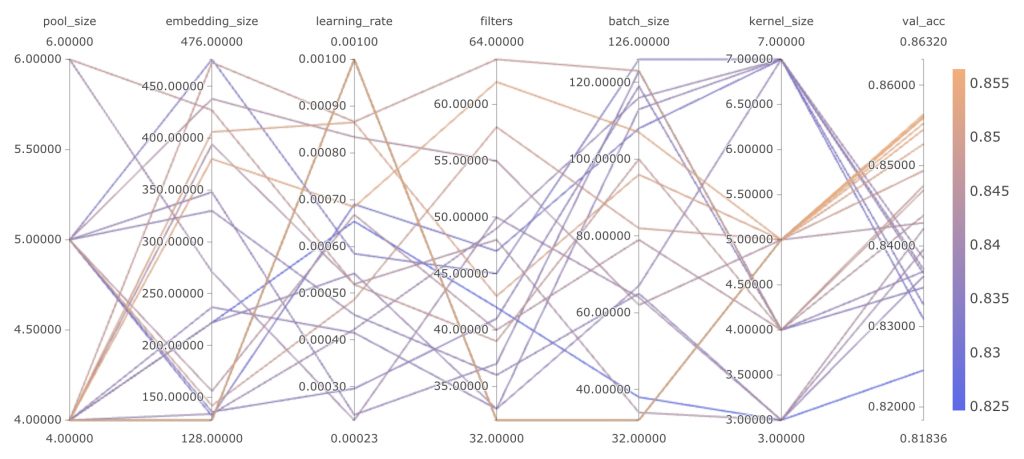
Consider a modeling task where you’re keeping track of 20 hyperparameters, 10 metrics, dozens of architectures and feature engineering techniques, all while iterating quickly and running dozens of models a day. It can become incredibly tedious to manually track all of these artifacts. Building a good ML model can oftentimes resemble tuning a radio with 50 knobs. If you don’t keep track of all of the configurations you’ve tried, the combinatorial complexity of finding the signal in your modeling space can become cumbersome.
We’ve built Comet based on these needs (and what we wanted when we were working on data science and machine learning ourselves, at Google, IBM, and as part of research groups at Columbia University and Yale University). Every time you train a model, there should be something to capture all of the artifacts of your experiment and save them in some central ledger where you can look up, compare, and filter through all of your (or your team’s) work. Comet was built to provide this function to practitioners of machine learning.
Measuring workflow efficiency is a notoriously difficult thing to do, but on average our users report 20-30% time savings by using Comet (note: Comet is free for individuals and researchers – you can sign-up here). This doesn’t take into account unique insights and knowledge that arise from having access to a visual understanding of your hyperparameter space, real-time metric tracking, team-wide collaboration and experiment comparison. Access to this knowledge enables time savings as well as, and perhaps more importantly, the ability to build better models.
Looking Ahead
It is tempting to ignore questions about ML tools and processes altogether. In a field responsible for self-driving cars, voice assistants, facial recognition, and many more groundbreaking technologies, one may be forgiven for leaping into the fray of building these tools themselves and not considering how best to build them.
If you are convinced that the software engineering stack works well enough for doing AI, you will not be proven definitively right or wrong. After all, this is a field defined by uncertainty. But perhaps it is best to consider this in the way a data scientist may consider a modeling task: what is the probability distribution of possible futures? What is more or less likely? That a field as powerful and promising as AI will continue to rely on the tools and processes built for a different discipline, or that new ones will emerge to empower practitioners to the fullest?
If you are curious about these ML tools or have any questions, feel free to reach out to me at niko@comet.ml.
Additional Reading
Blogs on the differences between Machine Learning and Software Engineering:
- Futurice Blog on ML vs Software Engineering
- KD Nuggets Blog on ML vs Software Engineering
- Concur Labs Blog on ML vs Software Engineering
- Microsoft Case Study on Building ML Team Processes
- Leon Bottou Slides from 2015 ICML Talk
Want to stay in the loop? Subscribe to the Comet Newsletter for weekly insights and perspective on the latest ML news, projects, and more.
Related Articles