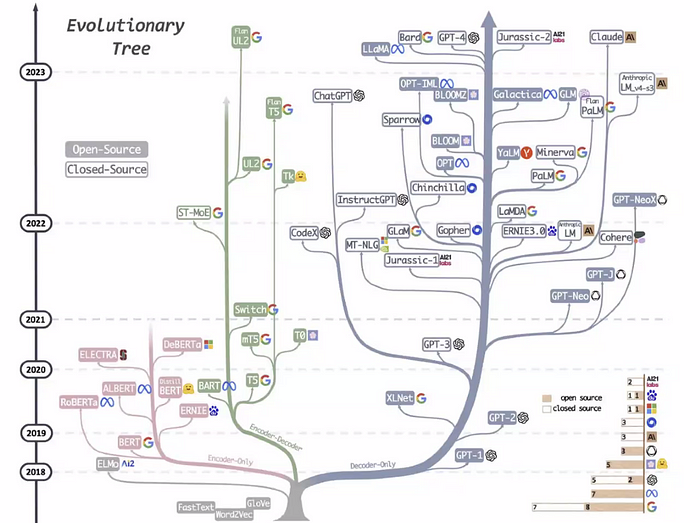
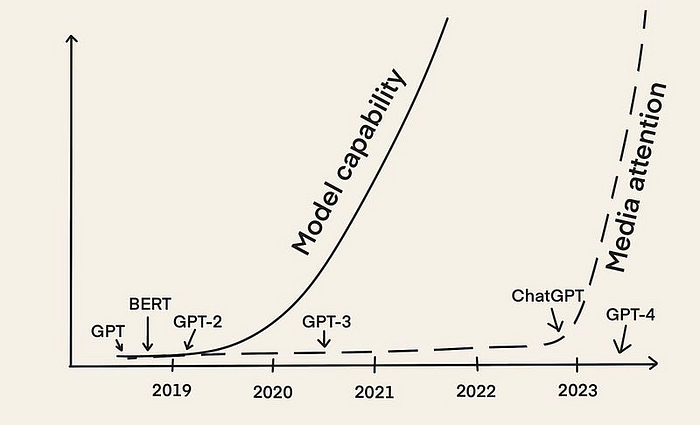
In the ever-evolving landscape of technology, where innovation is the driving force, staying ahead of the curve is paramount. Unsurprisingly, Machine Learning (ML) has seen remarkable progress, revolutionizing industries and how we interact with technology. The emergence of Large Language Models (LLMs) like OpenAI’s GPT, Meta’s Llama, and Google’s BERT has ushered in a new era in this field. These LLMs can generate human-like text, understand context, and perform various Natural Language Processing (NLP) tasks. Consequently, the tech world is abuzz with the evolution of a groundbreaking methodology called “LLMOps.” This revolutionary approach is reshaping how we develop, deploy, and maintain LLMs in production, transforming how we build and maintain AI-powered systems and products, solidifying its place as a pivotal force in AI.
However, harnessing the power of LLMs comes with its challenges. This is where the world of operations steps in, and while MLOps (Machine Learning Operations) has been a guiding light, a new paradigm is emerging — LLMOps (Large Language Model Operations).
The MLOps Foundation
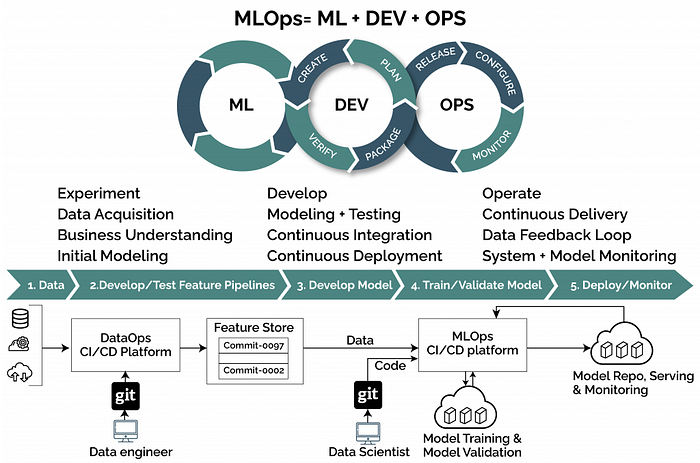
Before we dive into the exciting world of LLMOps, let’s take a moment to understand MLOps. MLOps, often seen as a subset of DevOps (Development Operations), focuses on streamlining the development and deployment of machine learning models. It’s like an orchestra conductor, ensuring that every instrument plays harmoniously.
In MLOps, engineers are dedicated to enhancing the efficiency and impact of ML model deployment. Their mission? To minimize project lifecycle friction and bridge the gap between developers and operations teams. This streamlined approach reduces time-to-value and maximizes the impact of collaborative efforts.
The journey of an ML engineer, from initial development to deployment and integration, typically involves four core tasks:
- Data Collection and Labeling
- Feature Engineering and Model Experimentation
- Model Evaluation and Deployment
- ML Pipeline Monitoring and Response
While MLOps has been a game-changer, standardizing this workflow is still challenging. Different domains, data types, and industries often demand deviations or specialized emphasis within these tasks. But wait, there’s a twist in the tale.
The Rise of LLMOps
LLMOps exists within the same realm as MLOps but introduces a fresh perspective and new dimensions. Imagine it as a remix of your favorite song — familiar yet exhilaratingly different.
As we transition from MLOps to LLMOps, we need to understand the variations at the task level. These differences are crucial for effectively operationalizing LLMs within enterprise settings. Let’s delve into some key distinctions:
Data Collection and Labeling
- MLOps: Focuses on sourcing, wrangling, cleaning, and labeling data.
- LLMOps: Requires larger-scale data collection, emphasizing diversity and representativeness. Automation is critical, with techniques like pre-trained models, active learning, or weak supervision methods.
Feature Engineering and Model Experimentation
- MLOps: Involves improving ML performance through experiments and feature engineering.
- LLMOps: LLMs excel at learning from raw data, making feature engineering less relevant. The focus shifts towards prompt engineering and fine-tuning.
Model Evaluation and Deployment
- MLOps: Computes metrics like accuracy over validation data.
- LLMOps: Demands a broader set of metrics, assessing fairness, robustness, and interpretability. Think of “golden test sets” and tools for managing training data and versions.
ML Pipeline Monitoring and Response
- MLOps: Tracks metrics, investigates predictions, and patches models.
- LLMOps: Involves monitoring performance across various tasks, languages, and domains. Look out for potential biases, ethical concerns, and unintended consequences.
It’s important to note that this landscape is rapidly evolving. LLMOps will continue to refine itself, and this table will undergo significant changes as our knowledge deepens.
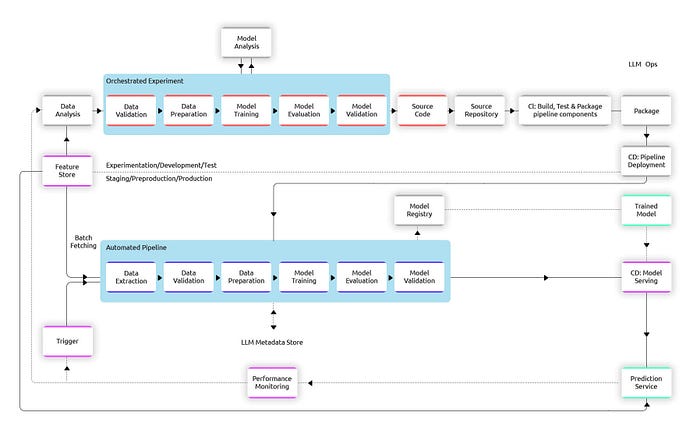
Key Components of LLMOps
Now that we’ve seen the core differences between MLOps and LLMOps, let’s explore the essential components of the LLMOps toolkit:
- Prompt Engineering: Crafting well-designed prompts that guide LLM responses, enhancing overall performance.
- Deploying LLM Agents: Integrating LLMs seamlessly into applications or systems for real-time interactions.
- LLM Observability: Monitor and analyze LLM behavior and performance to ensure they meet desired criteria.
The LLMOps Architecture
Deploying and managing large language models efficiently requires a structured approach. Here’s a step-by-step breakdown:
Data Management
- Collection and Preprocessing: Gather diverse and representative data. Clean and preprocess data to enhance quality.
- Data Labeling and Annotation: Involve human experts for accurate labeling. Explore approaches like Amazon Mechanical Turk for high-quality annotations.
- Storage, Organization, and Versioning: Select appropriate storage solutions and version control to track dataset changes.
Architectural Design and Selection
- Model Architecture: Choose the suitable model based on domain, data, and performance requirements.
- Pretraining and Fine-tuning: Leverage pre-trained models and fine-tune them for specific tasks.
Model Evaluation and Benchmarking
- Evaluation Metrics: Assess model performance using accuracy, F1-score, and BLEU metrics.
- Deployment Strategies and Platforms: Decide between cloud-based and on-premises deployments. Implement continuous integration and delivery (CI/CD) pipelines.
Monitoring and Maintenance
- Model Drift: Regularly monitor and update models to mitigate performance deterioration.
- Scalability and Performance Optimization: Use technologies like Kubernetes for scalability.
Data Privacy and Protection
- Anonymization and Pseudonymization: Protect sensitive data by removing personally identifiable information (PII).
- Data Encryption and Access Controls: Encrypt data and control access to ensure confidentiality.
Regulatory Compliance
- Complying with Data Protection Regulations: Adhere to data protection laws like GDPR and CCPA.
- Privacy Impact Assessments (PIAs): Evaluate privacy risks and mitigate them.
The Advantages of LLMOps
Embracing LLMOps offers several compelling advantages:
- Enhanced Efficiency: LLMOps streamlines model and pipeline development, leading to significant time and resource savings.
- Improved Scalability: It enables organizations to scale LLMs efficiently, accommodating growing data volumes and real-time interactions.
- Increased Accuracy: LLMOps prioritizes high-quality data, improving accuracy and relevance in language model outputs.
- Simplicity: By simplifying AI development, LLMOps reduces complexity and makes AI more accessible and user-friendly.
- Risk Reduction: LLMOps places a strong emphasis on the safe and responsible use of LLMs, mitigating risks associated with bias, inaccuracy, and toxicity.
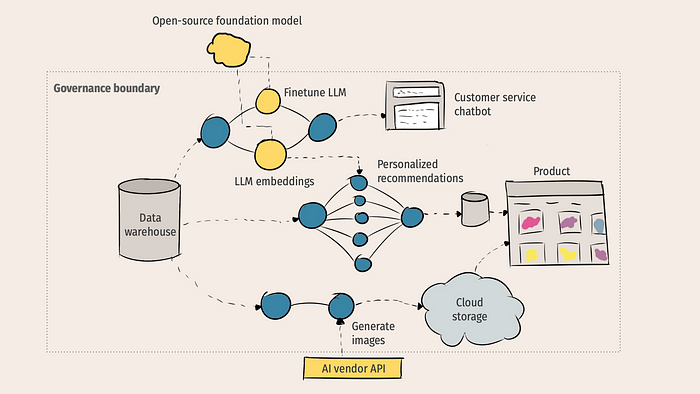
The Future of LLMOps
As we look ahead, LLMOps promises exciting advancements in various areas:
- Privacy-Preserving and Federated Learning: LLMOps will focus on preserving privacy while training models on decentralized data.
- Model Optimization and Compression: More efficient techniques will emerge to reduce computational resources needed for model training.
- Open-Source Integration: LLMOps will embrace open-source tools, simplifying the development and deployment of LLMs.
- Interpretability and Explainability: As LLMs become more powerful, the focus on understanding model decision-making processes will intensify.
- Integration with Other AI Technologies: LLMOps will collaborate with computer vision, speech recognition, and other AI domains, creating complex AI systems.
In conclusion, LLMOps is at the forefront of the AI revolution. It’s not just about technology; it’s about the transformation of industries, the enhancement of efficiency, and the responsible use of AI. The journey from MLOps to LLMOps is exciting, and its impact on our world continues to evolve. So, dive in, embrace LLMOps, and be part of the future of technology.
📣 Exciting News!
💌 Don’t miss a single update from me, Ayyüce Kızrak! 🚀 Subscribe now to receive instant email.
Feel free to follow me on GitHub and Twitter accounts for more content!
