
Tree-based machine learning methods are among the most commonly used supervised learning methods. They are constructed by two entities; branches and nodes. Tree-based ML methods are built by recursively splitting a training sample, using different features from a dataset at each node that splits the data most effectively. The splitting is based on learning simple decision rules inferred from the training data.
Generally, tree-based ML methods are simple and intuitive; to predict a class label or value, we start from the top of the tree or the root and, using branches, go to the nodes by comparing features on the basis of which will provide the best split.
Tree-based methods also use the mean for continuous variables or mode for categorical variables when making predictions on training observations in the regions they belong to.
Since the set of rules used to segment the predictor space can be summarized in a visual representation with branches that show all the possible outcomes, these approaches are commonly referred to as decision tree methods.
The methods are flexible and can be applied to either classification or regression problems. Classification and Regression Trees (CART) is a commonly used term by Leo Breiman, referring to the flexibility of the methods in solving both linear and non-linear predictive modeling problems.
Types of Decision Trees
Decision trees can be classified based on the type of target or response variable.
i. Classification Trees
The default type of decision trees, used when the response variable is categorical—i.e. predicting whether a team will win or lose a game.
ii. Regression Trees
Used when the target variable is continuous or numerical in nature—i.e. predicting house prices based on year of construction, number of rooms, etc.
Advantages of Tree-based Machine Learning Methods
- Interpretability: Decision tree methods are easy to understand even for non-technical people.
- The data type isn’t a constraint, as the methods can handle both categorical and numerical variables.
- Data exploration — Decision trees help us easily identify the most significant variables and their correlation.
Disadvantages of Tree-based Machine Learning Methods
- Large decision trees are complex, time-consuming and less accurate in predicting outcomes.
- Decision trees don’t fit well for continuous variables, as they lose important information when segmenting the data into different regions.
Common Terminology
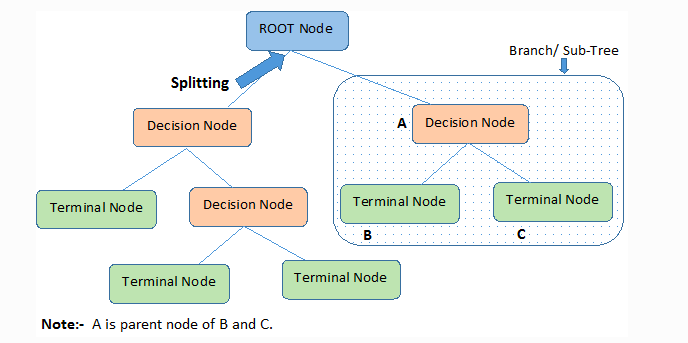
i) Root node — this represents the entire population or the sample, which gets divided into two or more homogenous subsets.
ii) Splitting — subdividing a node into two or more sub-nodes.
iii) Decision node — this is when a sub-node is divided into further sub-nodes.
iv) Leaf/Terminal node — this is the final/last node that we consider for our model output. It cannot be split further.
v) Pruning — removing unnecessary sub-nodes of a decision node to combat overfitting.
vi) Branch/Sub-tree — the sub-section of the entire tree.
vii) Parent and Child node — a node that’s subdivided into a sub-node is a parent, while the sub-node is the child node.
Algorithms in Tree-based Machine Learning Models
The decision of splitting a tree affects its accuracy. Tree-based machine learning models use multiple algorithms to decide where to split a node into two or more sub-nodes. The creation of sub-nodes increases the homogeneity of the resultant sub-nodes. Algorithm selection is based on the type of target variable.
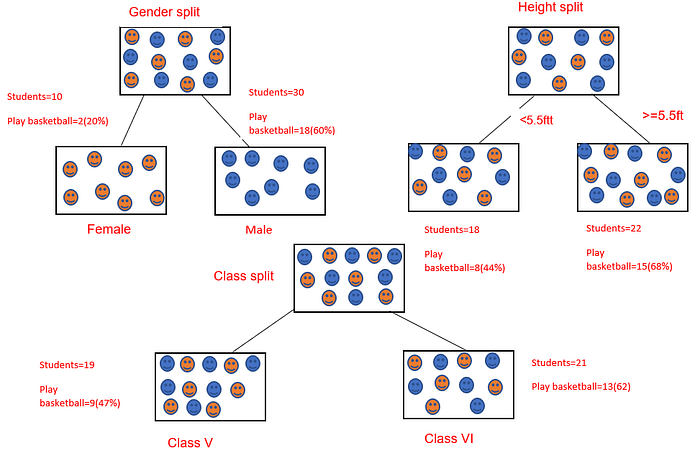
Suppose you’re the basketball coach of a grade school. The inter-school basketball competitions are nearby and you want to do a survey to determine which students play basketball in their leisure time. The sample selected is 40 students. The selection criterion is based on a number of factors such as gender, height, and class.
As a coach, you’d want to select the students based on the most significant input variable among the three variables.
Decision tree algorithms will help the coach identify the right sample of students using the variable, which creates the best homogenous set of student players.
Classification and Regression Tree (CART) Training Algorithm
CART is used to train a decision tree. It first splits the training set into two subsets using a single feature k and threshold tk—i.e. height≥150cm. The algorithm searches for the pair (k, tk) that produces the purest subsets. The cost function for the classification the algorithm tries to minimize is given by:

The CART algorithm splits the child nodes using the same approach recursively, and once it reaches the max-depth, it stops.
We’ll now have a look at the two commonly-used criteria for measuring the impurity of a node; the Gini index and entropy.
i) Gini Index
The Gini index states that if we select two items from a population at random, then they must be of the same class and probability if the population is pure. The target variable is normally categorical, such as pass or fail, and it performs only binary splits. The higher the value of the Gini index, the higher the homogeneity. The CART algorithm uses the Gini method to create binary splits.
Calculating the Gini index
- We first calculate Gini index for sub-nodes using the sum of the square of probability: p2+q2
- We then calculate Gini for the split using the weighted Gini score of each node of that split.
Referring to the example above, where the basketball coach wants to separate students based on whether they play basketball or not—using the input variables gender, height, and class, we’ll identify which split produces the most homogenous sub-nodes using the Gini index.
Split on Gender
Calculating:
- Gini for sub node female: (0.2*0.2) + (0.8*0.8) =0.68
- Gini for sub node male: (0.6*0.6) + (0.4*0.4) =0.52
- Calculating weighted Gini for split on gender: (10/40)*0.68+(30/40)*0.52=0.56
Split on Height
Calculating:
- Gini for sub node <5.5ft: (0.44*0.44) + (0.56*0.56) =0.51
- Gini for sub node >5.5ft: (0.68*0.68) + (0.32*0.32) =0.56
- Calculating weighted Gini for split on height: (18/40)*0.51+(22/40)*0.56=0.54
Split on Class
Calculating:
- Gini for sub-node class V: (0.47*0.47) + (0.53*0.53) =0.5
- Gini for sub-node class VI: (0.62*0.62) + (0.38*0.38) =0.53
- Calculating weighted Gini for split on class: (19/40)*0.5+(21/40)*0.53=0.52
It’s evident that the split based on gender has the highest Gini index, hence the split will take place on gender, which will result in the most homogenous sub-nodes.
If we want to calculate the Gini impurity:
1 — Gini index
- Calculating Gini impurity for gender: 1–0.65=0.35
- Calculating Gini impurity for height: 1–0.54=0.46
- Calculating Gini impurity for class: 1–0.52=0.48
The split on class has the highest Gini impurity and will produce the least homogenous sub-nodes.
ii) Entropy
In machine learning, entropy is commonly used as an impurity measure. If a sample is completely homogenous, the entropy is zero, and if the sample is equally divided (50%-50%), it has an entropy of one.
Entropy is calculated by the following equation:
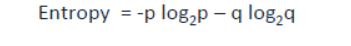
P and q are the probability of, say, success and failure in a particular node. Entropy can also be applied to categorical target variables. The lesser the entropy, the better the split.
Calculating entropy for a split
- Calculate the entropy of the parent node.
- Calculate the entropy of each individual node of the split.
- Calculate the weighted average of all sub-nodes available on the split.
We’ll now calculate the entropy for all the gender, height, and class nodes in the above example.
- Entropy for the parent node = -(20/40) log2 (20/40) — (20/40) log2 (20/40) = 1. This implies the node is impure.
- Entropy for the male node = -(18/30) log2 (18/30) — (12/30) log2 (12/30) = 0.97
- Entropy for the female node = -(2/10) log2 (2/10) — (8/10) log2 (8/10) = 0.72
- Entropy for split on gender = weighted entropy of sub nodes= (30/40) *0.97+(10/40)*0.72 = 0.91
- Entropy for the <5.5ft node = -(8/18) log2 (8/18) — (10/18) log2 (10/18) =0.99
- Entropy for the >5.5ft node = -(15/22) log2 (15/22) — (7/22) log2 (7/22) =0.92
- Entropy for split on height = weighted entropy of sub nodes=(18/40)*0.99+(22/40)*0.92=0.96
- Entropy for the class V node = -(9/19) log2 (9/19) — (10/19) log2 (10/19) =0.99
- Entropy for the class VI node = -(13/21) log2 (13/21) — (8/21) log2 (8/21) =0.96
- Entropy for split on class = weighted entropy of sub nodes=(19/40)*0.99+(21/40)*0.96= 0.98
It’s evident that the split on gender has the lowest entropy; hence, the most favorable split, which will give homogenous results.
Information gain can be calculated from entropy and is given as:
Information gain = 1 — entropy
Regularization of Hyperparameters
Decision trees make very few assumptions about the training data, as opposed to linear models which assume the data is linear.
The tree structure adapts itself to the training data if left unconstrained, resulting in overfitting. Such a model is known as a non-parametric model. The number of parameters in such a model isn’t determined prior to training and the model structure is free to fit closely to the data.
A parametric model, such as a linear model, has a predetermined number of parameters; thus, its degree of freedom is limited. This reduces the risk of overfitting but increases the risk of underfitting. In order to avoid overfitting on the training data, we need to restrict the decision tree’s freedom during training. This is known as regularization.
The regularization of hyperparameters depends on the algorithm used. Decision tree classifier algorithms use hyperparameters that restrict the shape of the decision tree, thus preventing both overfitting and underfitting. They include:
i) Min_samples_split
This is the minimum number of samples a node must have before it can be split. It reduces overfitting.
ii) Min_samples_leaf
The minimum number of samples a leaf node must have.
iii) Max_depth
The maximum depth of a tree. A higher depth allows the model to learn relations that are very specific to a particular sample.
iv) Max_leaf_nodes
The maximum number of leaf nodes.
v) Max_features
The maximum number of features that are evaluated for splitting at each node.
vi) Min_weight_fraction_leaf
It’s the same as mini_samples_leaf but expressed as a fraction of the total number of weighted instances.
Increasing the min_* hyperparameters or reducing max_* hyperparameters regularizes the model.
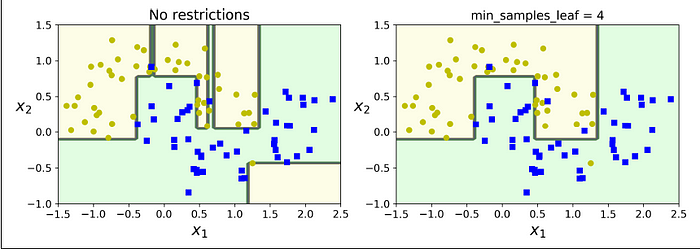
The figure above shows a decision tree trained with the default hyperparameters (no restrictions), and on the right, it’s trained with min_samples_leaf=4. It’s evident that the model on the left is overfitting, while the model on the right generalizes better to unseen data.
Pruning in Tree-based Algorithms
How do we implement pruning in decision trees?
A decision tree without constraints such as max_depth uses a greedy approach and will recursively look for the best split, hence an exponential growth in the nodes. A node whose children are all leaf nodes is considered unnecessary if the purity improvement it provides isn’t statistically significant.
Standard statistical tests such as the X2 test are used to estimate the probability that the improvement is purely a result of chance (null hypothesis).
If the probability (p-value) is higher than a given threshold (5%), then the node is considered unnecessary, and its children are deleted. Pruning continues until all the unnecessary nodes have been removed.
Random Forest and Ensemble Learning
If we aggregate the predictions of a group of predictors (regressor or classifier), we’ll often get better predictions than with the individual predictor.
A group of predictive models that aim to achieve model accuracy and stability is called an ensemble, and the technique used to achieve accuracy is ensemble learning. An ensemble learning algorithm, such as random forest, is an ensemble method.
We can train a group of decision tree classifiers, each on a different random subset of the training set. To make the final prediction, we obtain the predictions of all the individual trees, then predict the class that gets the most votes.
Such an ensemble of decision trees is called a random forest and is one of the most powerful machines learning algorithms out there for simple classification or regression tasks. It’s able to undertake dimensional reduction methods, treat missing values, outlier values, and perform other exploratory data analysis steps.
Random forest algorithms introduce extra randomness when growing trees— instead of searching for the very best feature when splitting a node, it searches for the best feature among a random subset of features. This results in a greater tree diversity, yielding an overall better model.
Conclusion
Tree-based algorithms are really important for every data scientist to learn. In this article, we’ve covered a wide range of details about tree-based methods; their features and structure, attribute selection algorithms (entropy, Gini index), and random forests.
