
The advent of Large Language Models (LLMs) has changed the Artificial Intelligence (AI) landscape. These powerful Natural Language Processing (NLP) models bring conversational AI to mainstream applications as business leaders move to integrate their products with chat-based capabilities.
During this language revolution, LangChain has been the pioneer in constructing production-grade LLM-based applications. It is an open-source framework that hosts Application Programming Interfaces (APIs) for several LLM and Chat models.
The models can be used out of the box or further fine-tuned for downstream tasks. Any LLM-related development requires proper experiment tracking and metric logging. These logs help track the model inputs and outputs and the results achieved with each iteration.
What is LangChain?
LangChain is presently the most popular library for application development using language models. The framework is available in prevalent languages, including Python and JavaScricpt, and provides access to popular models like OpenAIs GPT3.5.
Besides GPT, LangChain also boasts support for various open-source models from providers like HuggingFace and OpenLLM.Moreover, LangChain provides developers with various functionalities to construct prompts and use and fine-tune pre-trained LLMs.
Some key features include:
- Creating Prompt Templates: Prompt Templates help structure the inputs and outputs of an LLM and help the model make better predictions.
- Module Chaining: The chaining feature allows users to stack up various modules to enhance the model’s performance further. The output of one model becomes the input of the subsequent one.
- Agents: Agents help simulate complex steps for an LLM to help it reach specific results.
Every LLM project revolves around a few key components depending on the use case. Let’s discuss these in detail.
Want to learn how to build modern software with LLMs using the newest tools and techniques in the field? Check out this free LLMOps course from industry expert Elvis Saravia of DAIR.AI.
Components of an LLM-based Project
An LLM project may use a pre-trained model for generic use cases or fine-tune certain models for more specific tasks. Whatever may be the case, the project’s overall structure mostly remains the same. Let’s discuss a few components common to all LLM projects.
Foundation Model
A foundation model is the base model that is built on top of a highly complex architecture and is trained on massive text corpora covering various topics. Some popular foundation models include GPT4, BARD, and Llama. Foundation models are trained on extensive datasets and can be used as it is or further fine-tuned for specific use cases.
Training Corpus
The training dataset is a collection of text documents used to fine-tune the foundation model. The corpus can be related to a single topic or cover various subjects depending on the LLM requirements.
Prompts
A prompt is a text the user puts to the LLM. It may be a statement, question, or a simple salutation such as “Hello.” The LLM tokenizes and processes the prompt to output a relevant response.
Template
Prompt templates are a generic structure for the input prompts. They define a structure of the type of inputs that an LLM should expect and help the model reach a response more in line with the template. The templates help create reproducible prompts. An example would be:
“Tell me a story about {topic}”
This template will remain consistent for all prompts, and users only need to enter a different topic to get desirable results.
Chaining
Chaining is LangChain’s key feature that allows users to chain together various modules to reach better results. Developers can chain various models, such as a Grammar correction LLM, in conjunction with a chat model to ensure accurate interpretation and results. The output of each module in the chain becomes the input of the subsequent one until the chain ends.
Chains can also include prompt templates to structure the response before processing it via an LLM. The modules within the chain are arranged to allow the overall model to output the most favorable results.
Building a Model With LangChain and Comet
Comet provides easy integration with the LangChain framework using the model’s callbacks. The Comet documentation on third-party integration provides a step-by-step guide on logging LangChain projects.
Let’s see how we can set up our project. You can find the working code in our Google Colab Notebook.
Preliminary Setup
Before moving forward, you must create free accounts on Comet and HuggingFace and then install the relevant packages. These accounts will provide you with the API access keys to set up the required environment for the project.
Project Setup
# Install required libraries
!pip install langchain openai bitsandbytes accelerate transformers comet_ml comet-llm textstat
Next, we import all relevant libraries.
# import required libraries
import comet_ml
from langchain.llms import HuggingFacePipeline
from langchain import PromptTemplate, HuggingFaceHub, LLMChain
from langchain.prompts import PromptTemplate
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline, AutoModelForSeq2SeqLM
from langchain.callbacks import CometCallbackHandler
import torch
import os
Once all the libraries are installed and imported, you must initialize your workspace with Comet and HuggingFace.
# Define API key for HuggingFace
os.environ['HUGGINGFACEHUB_API_TOKEN'] = "YOUR_API_KEY"
# Initialize the project on comet. The experiment initialization will prompt the user to paste their API token.
comet_ml.login(project_name="LangChain-Experiment")
Once the environment is set up, we will initialize Comet’s callback handler. This handler will be passed to the HuggingFace model object. It will automatically log several aspects of the project. Remember to give the project a memorable and appropriate name.
# define Comet Callbacks
comet_callback = CometCallbackHandler(
project_name="LangChain-Experiment", # give the project an appropriate name
complexity_metrics=True,
stream_logs=True,
tags=["llm"],
visualizations=["dep", "ent"],
)
With everything set up, we can proceed to import models from HuggingFace in LangChain. LangChain allows users to access HuggingFace in two ways. You can directly access the HuggingFace Hub or use the HuggingFace Pipeline to download and use a model locally. We will work with the latter option.
## Initiaize Model and Tokenizer
model_id = "google/flan-t5-large"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForSeq2SeqLM.from_pretrained(model_id)
We have used a decent model for this demonstration, but you can choose to go for a bigger infrastructure if you have the VRAM and processing power. The entire HuggingFace model library can be browsed here.
Now, we only have to create the pipeline with the imported Tokenizer and Model and pass the required parameters.
# Create a local text2text pipeline using initialized model
pipe = pipeline(
"text2text-generation",
model=model,
tokenizer=tokenizer,
max_length=100,
do_sample=True,
temperature=0.2, # Response creativity
device=0, # Use GPU
)
# Initialize HuggingFacePipeline with the Comet Callback
local_llm = HuggingFacePipeline(pipeline=pipe, callbacks=[comet_callback], verbose = True)
Now, we can use the LLM as it is.
# Direct prediction from pre-trained LLM
local_llm.predict("Q: What is 2 multiplied by 6")
>> '2'
The initial results are not that great. The model outputs ‘2’ in response to the mathematical question.
We can use prompt templates to steer the model toward a better response.
Prompt Templates
LangChain allows users to create prompt templates that help the LLM understand how it is supposed to generate a response. Let’s see it in action.
# Create Prompt template to output polished results
template = """Question: {question}
Answer: Let's think step by step."""
prompt = PromptTemplate.from_template(template)
Let’s predict using this template.
chain = prompt | local_llm
# prompt LLM using the defined tempalte
question = "Q: What is 2 multiplied by 6"
chain.invoke({"question": question})
>> '2 multiplied by 6 equals 6 * 2 = 12. The answer: 12.'
Now we see the LLM has thought of the answer in a step-by-step approach and was able to divert itself to the correct response.
Let’s try another template.
# Create Prompt template to output polished results
translation_template = """Translate the following sentence to {language}.
Sentence: {sentence}
Here is the text translation in {language}:
"""
translation_prompt = PromptTemplate.from_template(translation_template)
This is a reusable template for users to enter any language and any sentence to make a language translator bot. Let’s see it in action.
chain2 = translation_prompt | local_llm
# prompt LLM using the defined tempalte
language = "German"
sentence = "Hello. I am Comet, a platform for tracking AI applications."
chain2.invoke({"language": language,
"sentence": sentence})
>> 'Ich bin Comet, eine Plattform für die Beobachtung von AI-Anwendungen.'
And now we have a language-translation tool.
Now, let’s see how our experimentation is logged in Comet.
Logging in Comet
Comet logs multiple experiments under a single project. This is helpful when you want to experiment with various parameters and want to compare the results across the board. The project panel displays comparison metrics of each experiment performed.
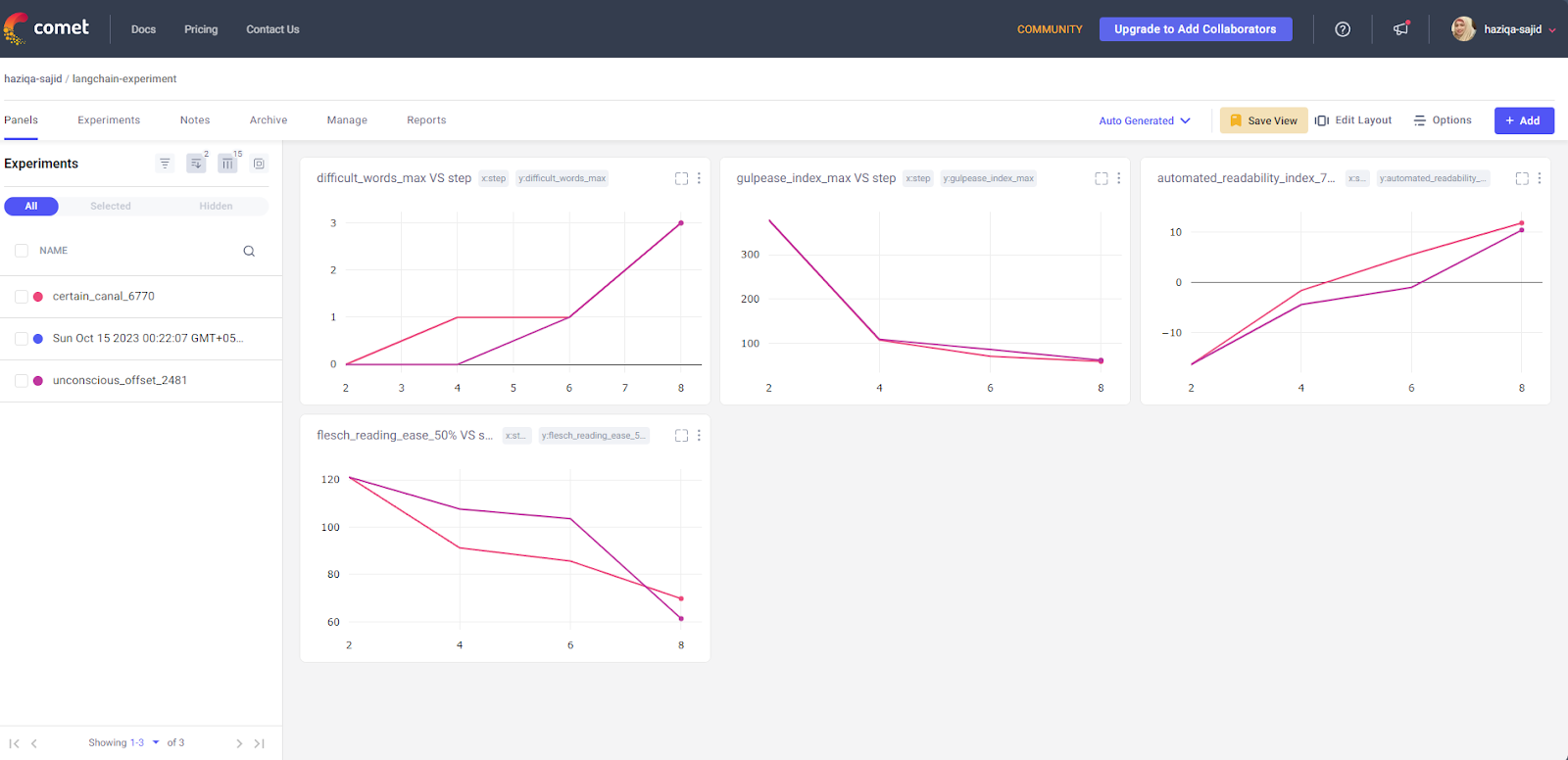
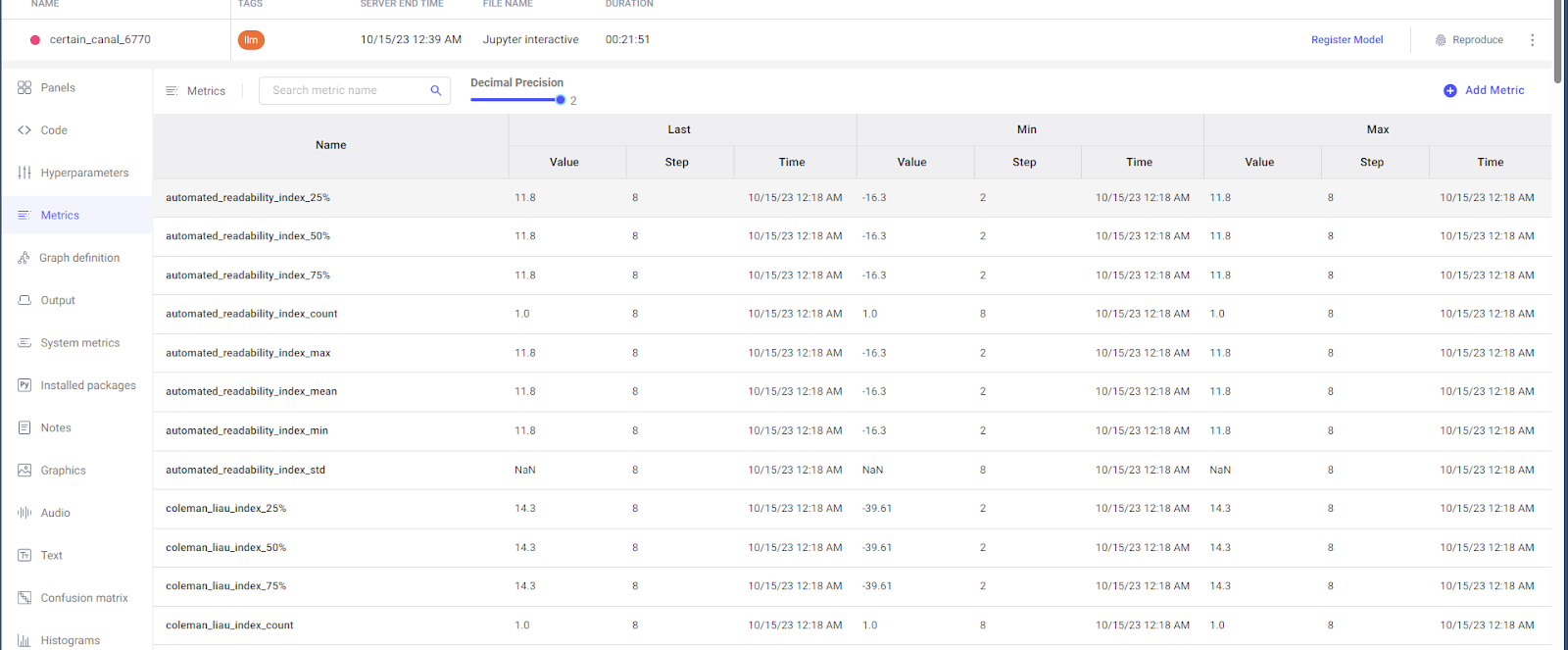
It has logged metrics for readability score and the difficult words against each iteration. Further drilling down to a single experiment provides more insight into the run. Comet has logged a variety of metrics, including the Readability Index, Coleman liau index, and Crawford score.
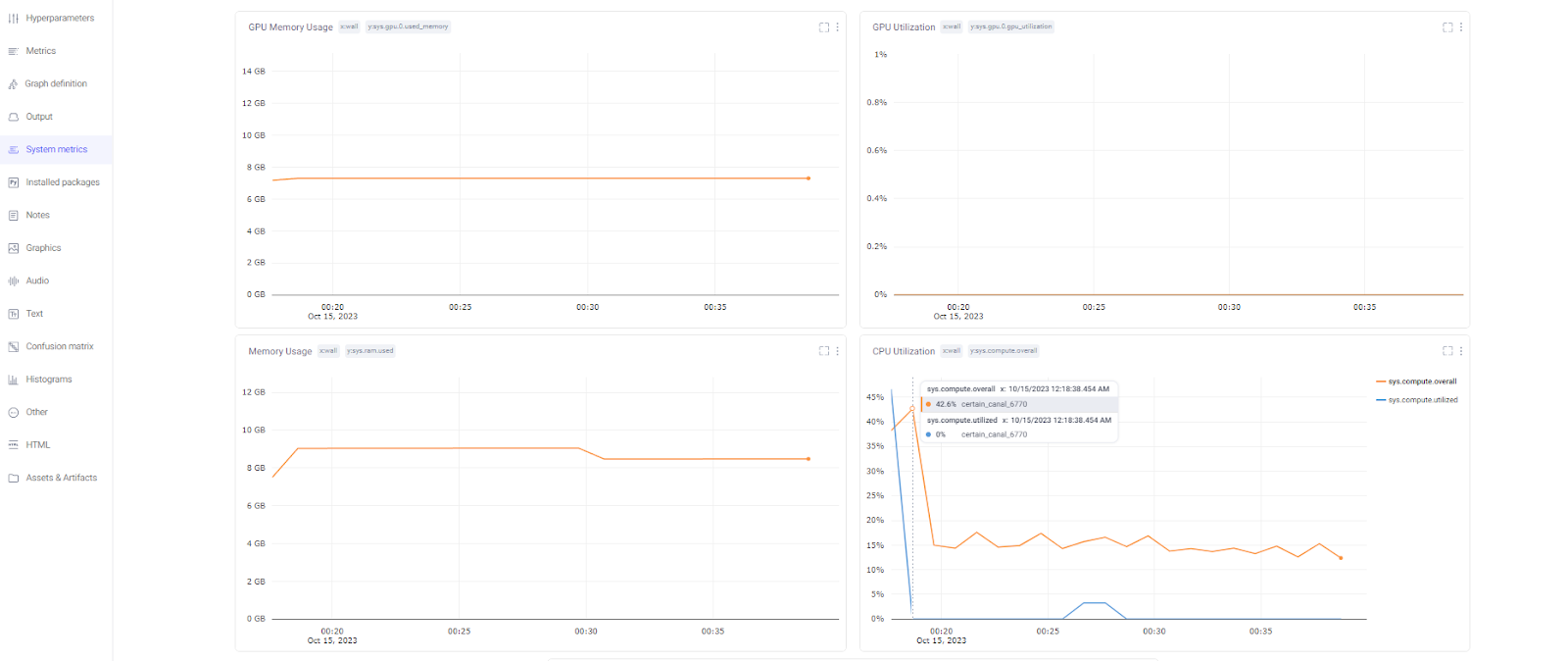
Additionally, it has logged GPU and CPU metrics for system monitoring.
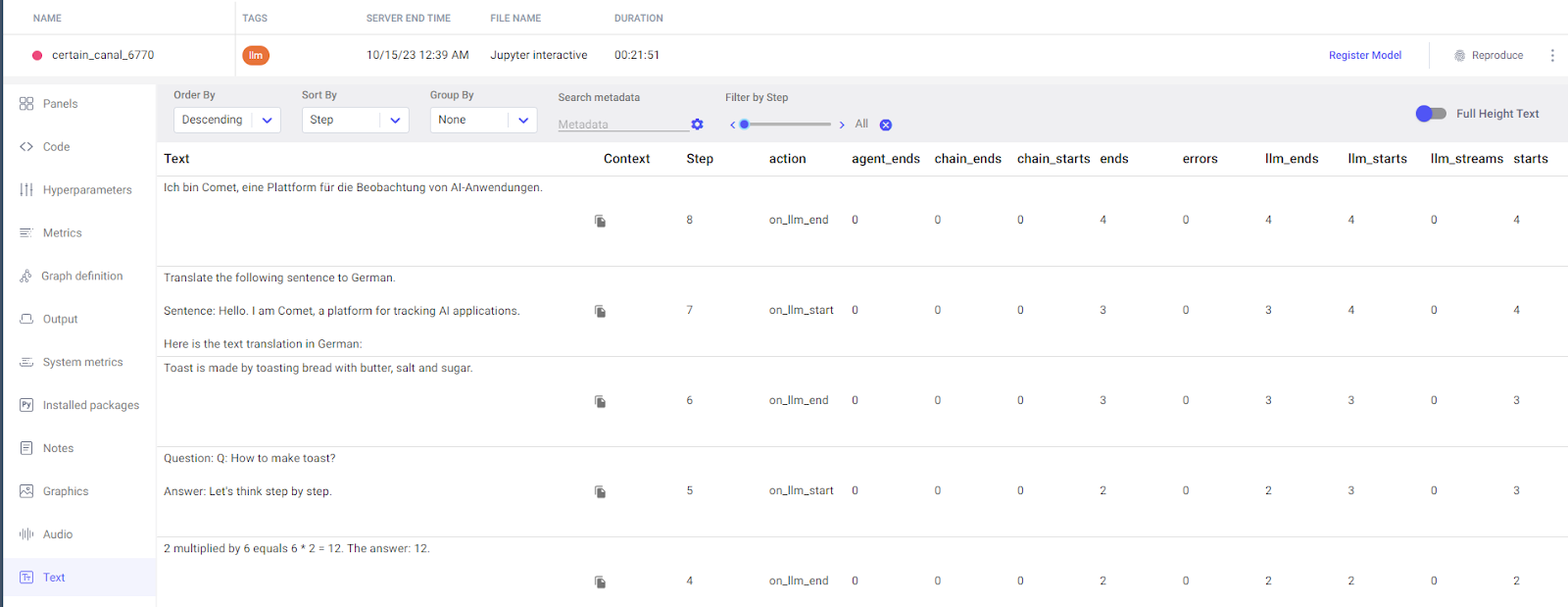
Lastly, Comet has logged all the text inputs and outputs generated during the experiment. These are logged in order of occurrence to keep track of whatever was passed to the model and when.
Key Takeaways
With technological advancements, LLMs have become more accessible than ever. They can be used to build various language-based applications, such as intuitive chatbots or language translation bots.
LangChain is an open-source framework that facilitates the construction of LLM-based applications. It hosts various open-source and paid models, including fine-tuning and model integration features.
It also supports easy experimentation logging with Comet using the Callback Handler. Comet automatically logs all experiment metrics and inputs and outputs received. It also compiles various experiments under a single project for easy comparison.
Comet is an AI-centric platform for tracking all machine-learning projects. It integrates with various Machine Learning (ML) service providers such as YOLO and HuggingFace and provides features like Data Versioning, Model Registration, and Automated Logging.
To learn more, schedule a demo today.
