All machine learning projects involve searching for the right model and features. As there is no way to know ahead of time what combination will best tackle a problem at hand, several experiments are conducted to try and find a solution worthy of being taken into production. At various steps in the process, you may need to reproduce an experiment: Maybe for auditing purposes, to draw comparisons, learning, etc. This is typically where the problems occur.
Attempting to reconstruct training data, features, models, frameworks, source code, etc., can be absolute hell if everything was not tracked and managed accordingly. In most cases, if you’ve failed to properly track experiments and their artifacts you’re going to struggle to reproduce them if it’s possible. The result is a whole lot of time wasted with not much to show for it.
Welcome the Artifact class in Comet ML.
In this article, we are going to discover how to do the following leveraging Comet ML:
→ How to add an asset to an Artifact
→ How to retrieve a logged Artifact
→ How to update the version of an Artifact
Adding an Artifact
Let’s be clear on what we are talking about when we say “artifacts.” An Artifact describes outputs that are created during the training process. This could be anything from a fully trained model, a models checkpoint, the data used to train a model, etc. We keep them to aid us with reproducibility.
An artifact is “something observed in a scientific investigation or experiment that is not naturally present but occurs as a result of the preparative or investigative procedure.” — Dictionary definition
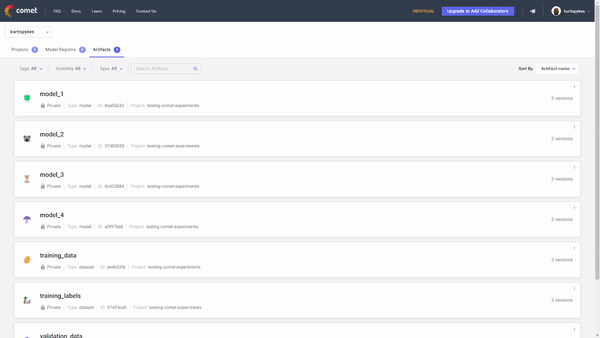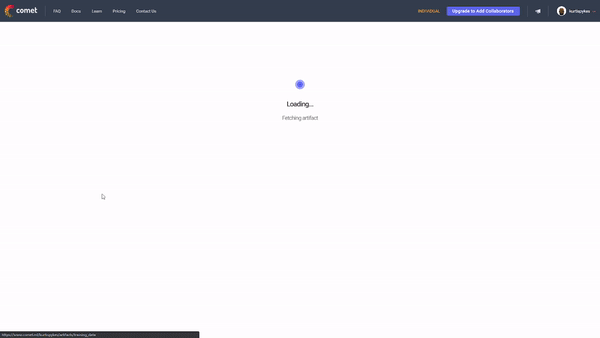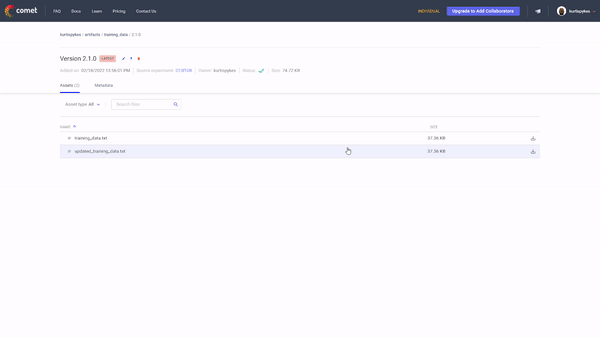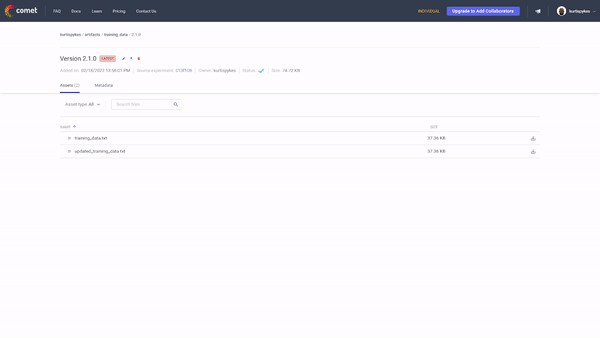
In Comet, each artifact lives in your workspace. They are distinguished by a name, and if there are many versions of an artifact, it can also be told apart by its version number.
Logging an Artifact is made simple with the Artifact() class. Each instance must be initialized with a name (to separate distinct artifacts), and a type (i.e. dataset, model, etc). You may also pass other information such as:
- Version → To tell Comet what version number to create. Note, if a version isn’t manually passed, Comet will automatically create one for you. It will do so by checking whether it’s the first time you’ve logged the artifact (using the name as a unique identifier) and logging the correct version accordingly.
- Aliases → To be attached to the future artifact version. The aliases list is converted to a set data type for de-duplication.
- Metadata → To add more information about the artifact being logged. The metadata must be a JSON-encodable dictionary.
The documentation states the following:
“After creating an Artifact instance, you then can add asset files or a remote URL to the Artifact.”
Let’s see this in action:
# initialize artifacts
train_data_artifact = comet_ml.Artifact(name="training_data",
artifact_type="dataset",
metadata={"current_data": datetime.datetime.utcnow().isoformat()})
train_labels_artifact = comet_ml.Artifact(name="training_labels",
artifact_type="dataset",
metadata={"current_data": datetime.datetime.utcnow().isoformat()})
validation_data_artifact = comet_ml.Artifact(name="validation_data",
artifact_type="dataset",
metadata={"current_date": datetime.datetime.utcnow().isoformat()})
validation_labels_artifact = comet_ml.Artifact(name="validation_labels",
artifact_type="dataset",
metadata={"current_date": datetime.datetime.utcnow().isoformat()})
for i in range(5):
experiment = comet_ml.Experiment(
api_key="KGsg6IUGc5FpgH2lp3uF2gMbv",
project_name="testing-comet-experiments",
auto_param_logging=True,
auto_histogram_weight_logging=True,
auto_histogram_gradient_logging=True,
auto_histogram_activation_logging=True,
auto_histogram_epoch_rate=True
)
model_artifact = comet_ml.Artifact(name=f"model_{i}",
artifact_type="model",
metadata={"current_date": datetime.datetime.utcnow().isoformat()})
# model training
with experiment.train():
seed = np.random.randint(low=0, high=1000, dtype=int)
np.random.seed(seed)
tf.random.set_seed(seed)
random.seed(seed)
experiment.log_parameter("random_seed", seed)
model.fit(X_train, y_train, epochs=50, verbose=0)
model.save(f"my_model_{i}.h5")
# adding the artifact
model_artifact.add(f"my_model_{i}.h5")
experiment.log_artifact(model_artifact)
if i==0:
np.savetxt("training_data.txt", X_train)
np.savetxt("training_labels.txt", y_train)
np.savetxt("validation_data.txt", X_val)
np.savetxt("validation_labels.txt", y_val)
# adding data
train_data_artifact.add("training_data.txt")
train_labels_artifact.add("training_labels.txt")
validation_data_artifact.add("validation_data.txt")
validation_labels_artifact.add("validation_labels.txt")
# logging each artifact
experiment.log_artifact(train_data_artifact)
experiment.log_artifact(train_labels_artifact)
experiment.log_artifact(validation_data_artifact)
experiment.log_artifact(validation_labels_artifact)
# model validation
with experiment.validate():
loss, acc = model.evaluate(X_val, y_val)
experiment.log_metric("loss", loss)
experiment.log_metric("accuracy", acc)
experiment.end()
I know what you’re thinking — “that’s a lot of code.” Don’t worry I’ll break it down.
Getting started with Comet is completely free — check out Artifacts for yourself today.
The first section shows us initializing lots of data artifacts. We’ve done this because we want to save our training data with labels, and likewise for the validation set.
# initialize artifacts
train_data_artifact = comet_ml.Artifact(name="training_data",
artifact_type="dataset",
metadata={"current_data": datetime.datetime.utcnow().isoformat()})
train_labels_artifact = comet_ml.Artifact(name="training_labels",
artifact_type="dataset",
metadata={"current_data": datetime.datetime.utcnow().isoformat()})
validation_data_artifact = comet_ml.Artifact(name="validation_data",
artifact_type="dataset",
metadata={"current_date": datetime.datetime.utcnow().isoformat()})
validation_labels_artifact = comet_ml.Artifact(name="validation_labels",
artifact_type="dataset",
metadata={"current_date": datetime.datetime.utcnow().isoformat()})
Next, we start a for loop. This is done so we can generate five different neural network architectures, thus, conducting five experiments. Notice that the beginning of each loop initialized a new Experiment() and Artifact()instance. We do this to let Comet know we are starting a new experiment and would like to save a new model artifact — if we didn’t do this it would update old versions.
for i in range(5):
experiment = comet_ml.Experiment(
api_key="KGsg6IUGc5FpgH2lp3uF2gMbv",
project_name="testing-comet-experiments",
auto_param_logging=True,
auto_histogram_weight_logging=True,
auto_histogram_gradient_logging=True,
auto_histogram_activation_logging=True,
auto_histogram_epoch_rate=True
)
model_artifact = comet_ml.Artifact(name=f"model_{i}",
artifact_type="model",
metadata={"current_date": datetime.datetime.utcnow().isoformat()})
After that, we begin our training and validation experiments respectively. To add an artifact to an Artifact instance, we must pass either a file path or a file-like asset. This is why we saved our model after training using model.save(), before adding it to the Artifact instance.
A similar procedure was followed for the train data/labels and validation data/labels — each array was saved with np.savetxt(). But since each model is seeing the same data (train and validation), we set a condition to only log it once.
# model training
with experiment.train():
seed = np.random.randint(low=0, high=1000, dtype=int)
np.random.seed(seed)
tf.random.set_seed(seed)
random.seed(seed)
experiment.log_parameter("random_seed", seed)
model.fit(X_train, y_train, epochs=50, verbose=0)
model.save(f"my_model_{i}.h5")
# adding the artifact
model_artifact.add(f"my_model_{i}.h5")
experiment.log_artifact(model_artifact)
if i==0:
np.savetxt("training_data.txt", X_train)
np.savetxt("training_labels.txt", y_train)
np.savetxt("validation_data.txt", X_val)
np.savetxt("validation_labels.txt", y_val)
# adding data
train_data_artifact.add("training_data.txt")
train_labels_artifact.add("training_labels.txt")
validation_data_artifact.add("validation_data.txt")
validation_labels_artifact.add("validation_labels.txt")
# logging each artifact
experiment.log_artifact(train_data_artifact)
experiment.log_artifact(train_labels_artifact)
experiment.log_artifact(validation_data_artifact)
experiment.log_artifact(validation_labels_artifact)
That’s all that’s happening.
Retrieving a Logged Artifact
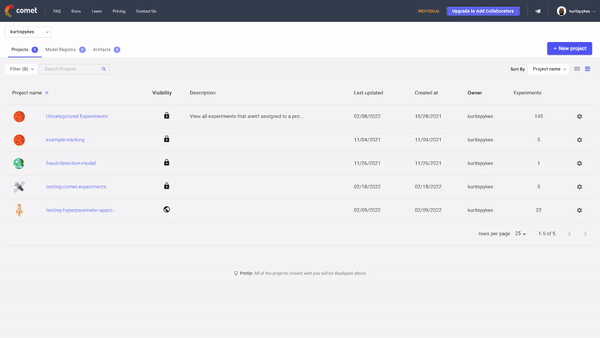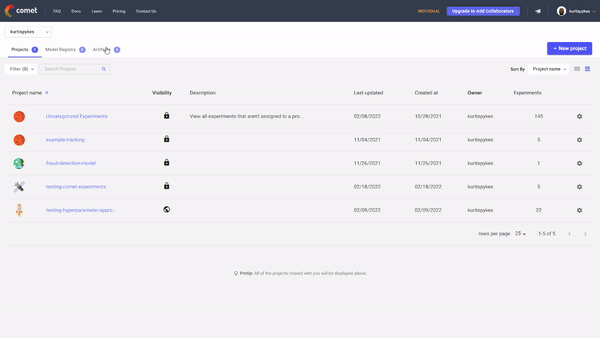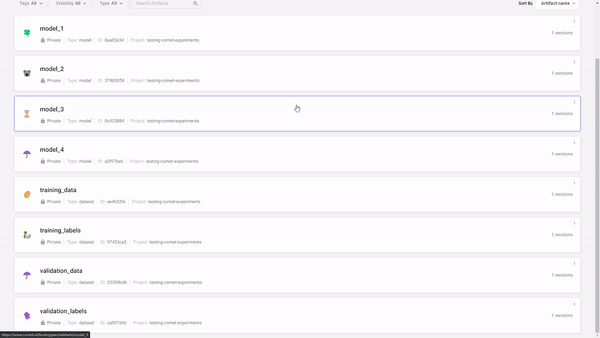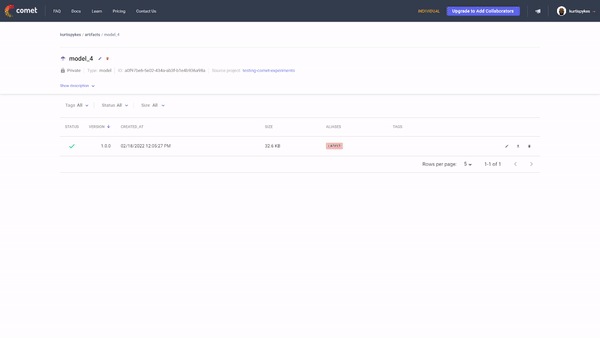
In our last run, we stored several different Artifacts. At some point, we may be required to retrieve them from our workspace. This action is done using the get_artifact() method on our Experiment() instance. The method takes the unique Artifact name and workspace.
Note: you may also retrieve a specific artifact version by setting the version_or_alias attribute to the appropriate version. Leaving it blank will retrieve the latest version.
experiment = comet_ml.Experiment(api_key="KGsg6IUGc5FpgH2lp3uF2gMbv")
artifact_model_3 = experiment.get_artifact(artifact_name="model_3",
workspace="kurtispykes")
To see all of the logged assets for an artifact version, we can use the assetsattribute of an Experiment() instance as seen below.
for asset in artifact_model_3.assets:
print(f"Logical path: {asset.logical_path}\n\
Size: {asset.size}\n\
Metadata: {asset.metadata}\n\
Type: {asset.asset_type}\n\
Artifact ID: {asset.artifact_id}\n\
ID: {asset.id}\n\
Version: {asset.artifact_version_id}")
And this will output the following:
Logical path: my_model_3.h5
Size: 33384
Metadata: None
Type: unknown
Artifact ID: 0c433884-b586-47a5-bf21-c841c8dc9733
ID: c27a83b616284beeafc91c69c1952df2
Version: 5fbcb375-bf52-47f9-a9f1-9e87fed09a25
Updating a Logged Artifact
Now, let’s say you’ve got some new data and you want to add it to the training data Artifact, how do we do that? Simple. We retrieve an existing Artifact, add the new file, bump the version, then log it — see the code below.
# generating new instances
X, y = make_circles(
n_samples=200, noise=0.05, random_state=42
)
# retrieve old training data
experiment = comet_ml.Experiment(api_key="KGsg6IUGc5FpgH2lp3uF2gMbv")
train_data_artifact = experiment.get_artifact(artifact_name="training_data",
workspace="kurtispykes")
train_labels_artifact = experiment.get_artifact(artifact_name="training_labels",
workspace="kurtispykes")
# download non-remote assets to local disk
local_train_data_artifact = train_data_artifact.download("new_data")
local_train_labels_artifact = train_labels_artifact.download("new_labels")
# loading the data from a txt file
train_data = np.genfromtxt("new_data/training_data.txt")
train_labels = np.genfromtxt("new_labels/training_labels.txt")
# joining the new data to old data
train_data_updated = np.concatenate((X_train, X), axis=0)
train_labels_updated = np.concatenate((y_train, y), axis=0)
# saving the updated data locally
np.savetxt("updated_training_data.txt", X_train)
np.savetxt("updated_training_labels.txt", y_train)
# logging the updated data artifacts
local_train_data_artifact.add("updated_training_data.txt")
local_train_labels_artifact.add("updated_training_labels.txt")
# bumping the version
local_train_data_artifact.version = train_data_artifact.version.next_minor()
local_train_labels_artifact.version = train_labels_artifact.version.next_minor()
# logging the artifacts
experiment.log_artifact(local_train_data_artifact)
experiment.log_artifact(local_train_labels_artifact)
When we visit our workspace, we will see there has been a new version added.
That’s all folks!
Thanks for reading.
