The Tokenization Concept in NLP Using Python
Tokenization is one of the main concepts of NLP. By definition, it is the process of breaking down given text in natural language processing into the smallest unit in a sentence, called a token. The smallest unit can be considered a word, not an individual character. A sentence’s lowest and smallest unit can be regarded as a word and separate special characters like an exclamation, dot, etc.
In this article, we will learn the following kinds of tokenization:
- Text Split
- Sentence Tokenization
- Word Tokenization
Let’s start with our first tokenization type.
Text Split Example:
Let us write the text:“Hi Everyone! We are learning NLP.” These are the words we have and the whole text. If you want just to split up the words based on the spaces, the result will look like this:
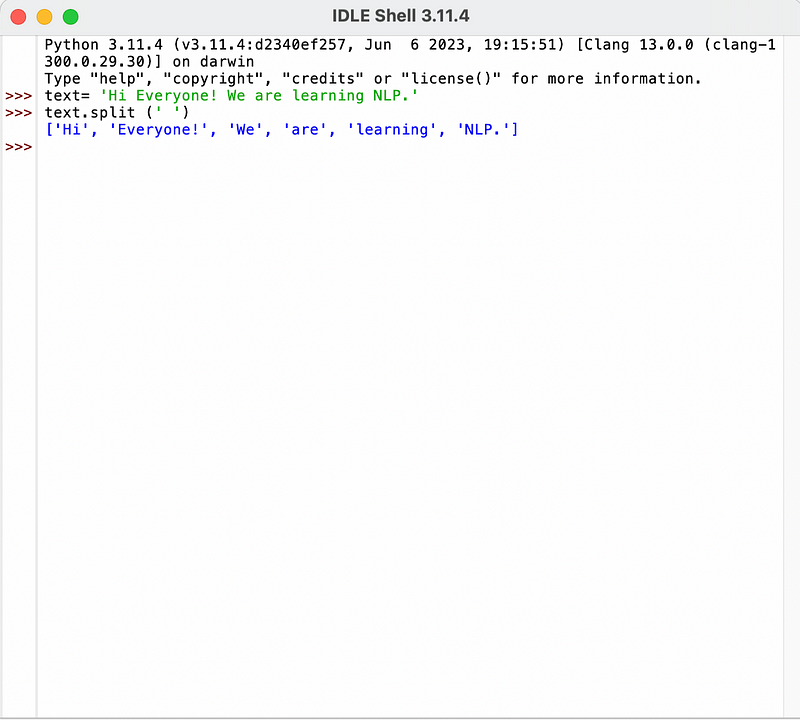
We just split the text with dots and space in the above code. You can see from the above screenshot it split every word, like “Hi” and “Everyone”.
As evident, the presence of an exclamation mark adds a special character, making the entire expression a token in text processing.
Example of Sentence Tokenization:
Sentence tokenization will separate the sentences. Let’s see an example with code:
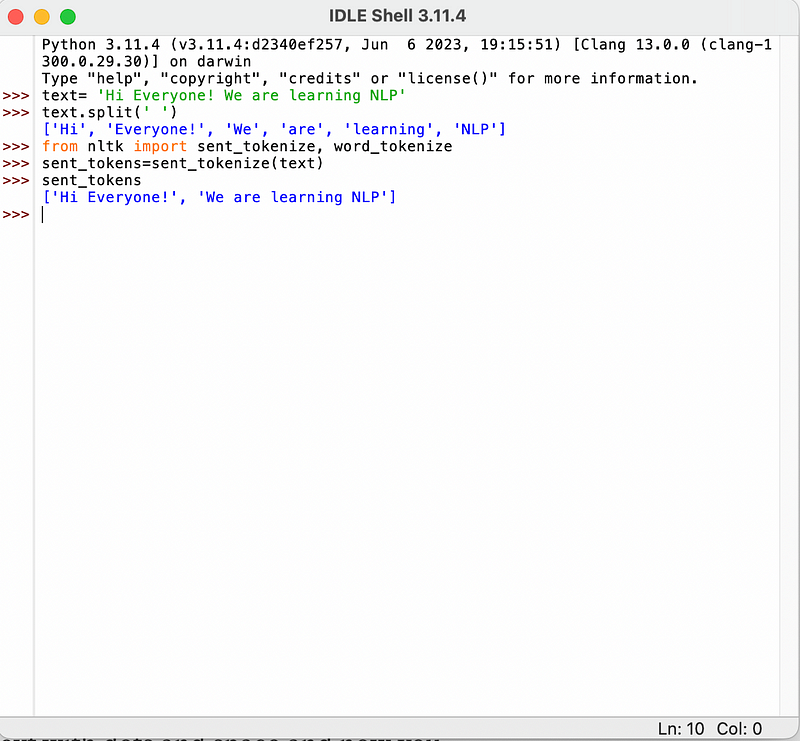
In the above code, we have imported sent_tokenization and word_tokenization from the nltk and passed the text. We will just display the send tokens.
Now you can see it split the sentence correspondingly, like Hi Everyone, We are learning NLP. This is how you can break up text, such as a big article or paragraphs, into a list of sentences.
Example of Word Tokenization:
Let’s explore the process of breaking down that sentence into individual words. This represents a granular level, where tokens, specifically word tokens, correspond to the word tokenize of the given text.
Let’s jump to the code:
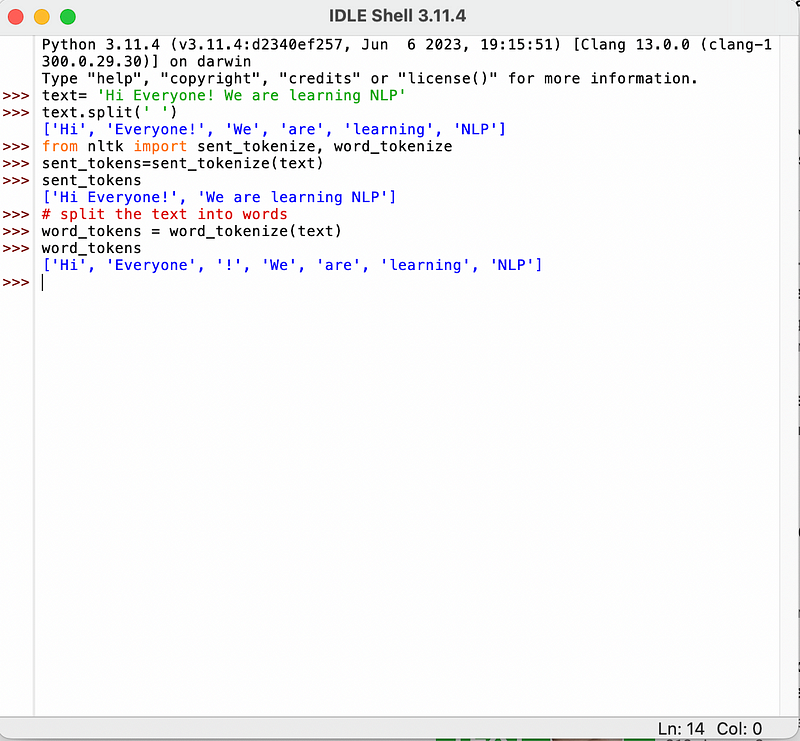
Now, let’s execute this. You can distinctly observe the contrast between a straightforward text-dot-split and the word tokenize. In the former, each word is treated as an individual token, including the exclamation mark. In the latter, “hi,” “everyone,” and the exclamation mark are treated as separate tokens. This approach considers special characters as distinct tokens, facilitating accurate word matching against the dictionary.
This will make it easier to process and avoid unnecessary, meaningless words. That’s why we use tokenization in every pre-processing step of NLP projects.
Conclusion
This article taught you the concept of tokenization in NLP. We discussed splitting the text, sentence tokenization, and word tokenization.
If you want to explore more about tokenization, then check out this source:
I hope this article was helpful. If you think something is missing, have questions, or would like to offer any thoughts or suggestions, go ahead and leave a comment below.
I’ve written some other Android-related content, and if you liked what you read here, you’ll probably also enjoy my Medium page.
Sharing (knowledge) is caring 😊 Thanks for reading this article. Be sure to clap or recommend this article if you found it helpful. It means a lot to me.
If you need any help, join me on Twitter, LinkedIn, GitHub, and subscribe to my YouTube Channel.
Related Articles


