SelfCheckGPT for LLM Evaluation
Detecting hallucinations in language models is challenging. There are three general approaches: Measuring token-level probability distributions for indications that a…
Detecting hallucinations in language models is challenging. There are three general approaches: Measuring token-level probability distributions for indications that a…

Perplexity is, historically speaking, one of the "standard" evaluation metrics for language models. And while recent years have seen a…

In this article, we’ll leverage the power of SAM, the first foundational model for computer vision, along with Stable Diffusion,…

In this article, we’ll compare the results of SDXL 1.0 with its predecessor, Stable Diffusion 2.0. We’ll also take a…

Introduction Prompt Engineering is arguably the most critical aspect in harnessing the power of Large Language Models (LLMs) like ChatGPT. Whether…
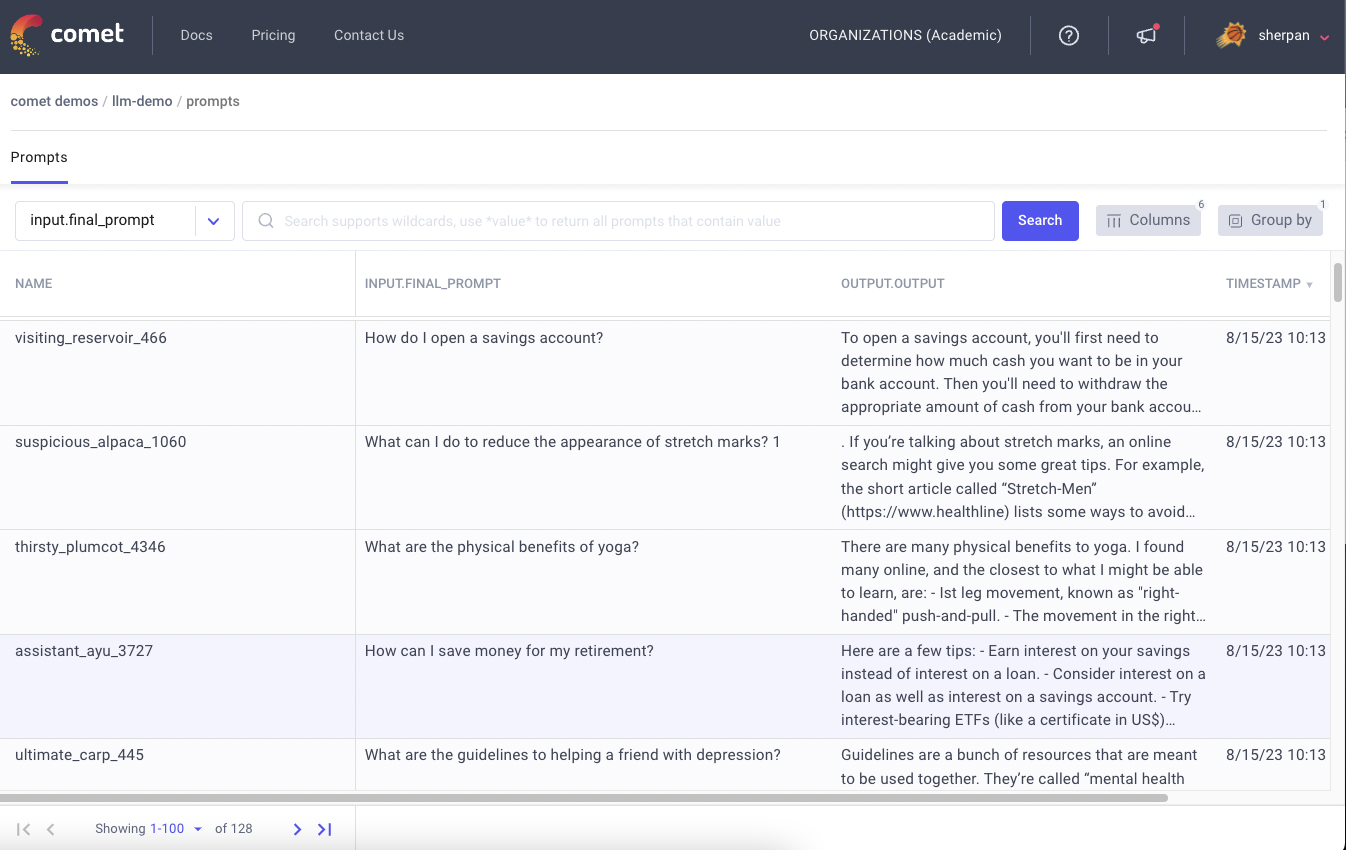
In this article we explore one of the most popular tools for visualizing the core distinguishing feature of transformer architectures:…

Introduction We often rely on scalar metrics and static plots to describe and evaluate machine learning models, but these methods…
