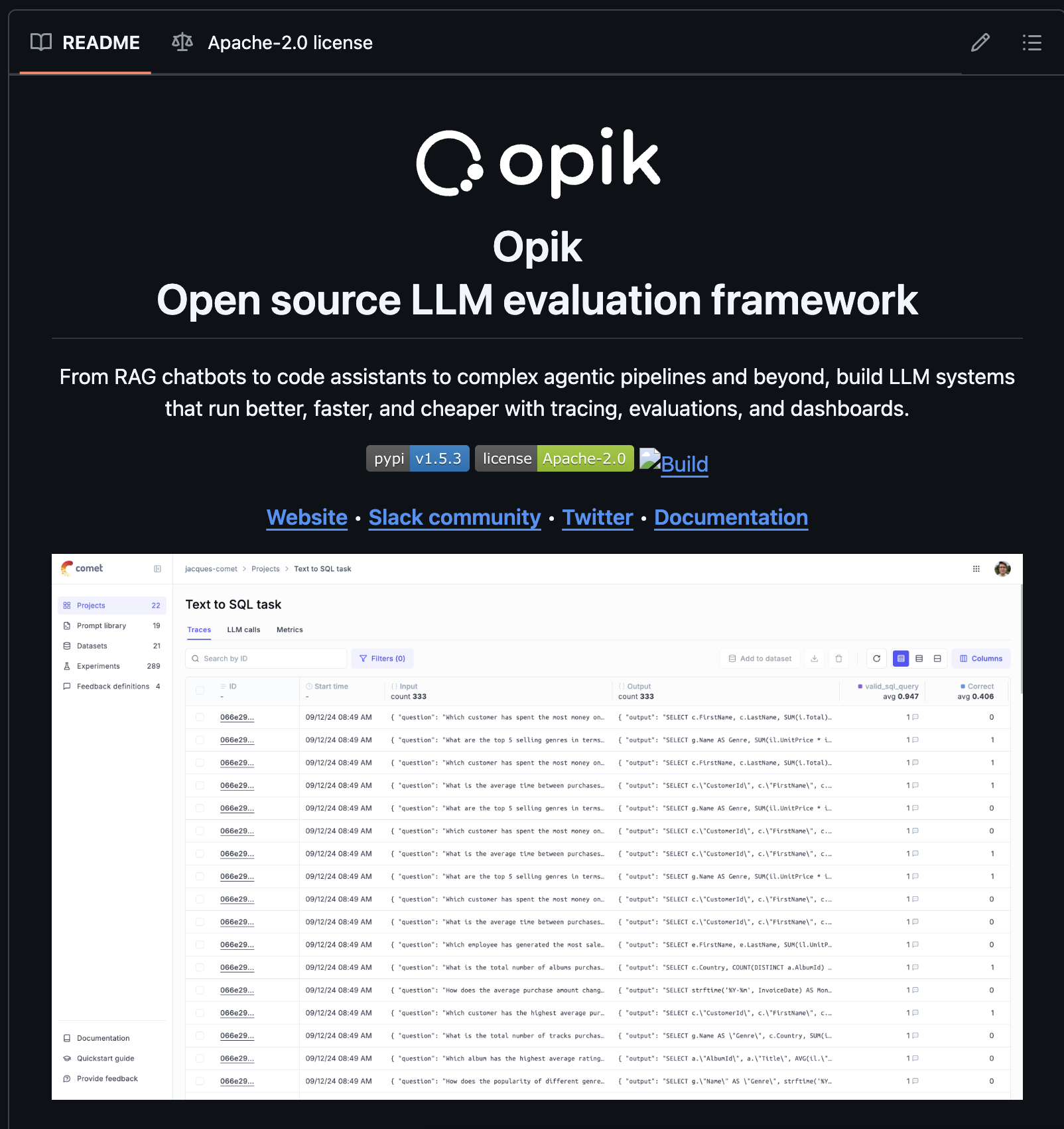
Research Guide: Model Distillation Techniques for Deep Learning

Knowledge distillation is a model compression technique whereby a small network (student) is taught by a larger trained neural network (teacher). The smaller network is trained to behave like the large neural network. This enables the deployment of such models on small devices such as mobile phones or other edge devices. In this guide, we’ll look at a couple of papers that attempt to tackle this challenge.
Distilling the Knowledge in a Neural Network (NIPS, 2014)
In this paper, a small model is trained to generalize in the same way as the larger teacher model. Transferring the generalization is done by using the class probabilities of the large model as targets while training the smaller model. If the large model is an ensemble of simpler models, the geometric or arithmetic mean of their predictive distributions is used as the target.
In testing the distillation, the authors trained a single large neural net with two hidden layers of 1200 linear hidden units on 60,000 training cases. The network was regularized using dropout and weight-constraints. The input images were jittered by two pixels in any direction. This network had 67 test errors. A smaller network with two hidden layers of 800 rectified linear units and no regularization had 146 errors. When the smaller network was regularized by matching the soft targets with the large net, it obtained 74 test errors.
The following results were obtained when the technique was used on speech recognition.

Contrastive Representation Distillation (2019)
This paper leverages the family of contrastive objectives to capture correlations and higher-order output dependencies. They are adapted in this paper for purposes of knowledge distillation from one neural network to another.
As shown below, the paper considers three distillation stages:
- model compression
- transferring knowledge from one modality (e.g RGB) to another (e.g., depth)
- distilling an ensemble of networks into a single network
The main idea in contrastive learning is learning a representation that’s close in some metric space for positive pairs while pushing away the representations between negative pairs.

The contrastive representation distillation (CRD) framework is tested on:
- model compression of a large network to a smaller one
- cross-modal knowledge transfer
- ensemble distillation from a group of teachers to a single student network
The technique was tested on CIFAR-100, ImageNet, STL-10, TinyImageNet, and NYU-Depth V2. Some of the results obtained are shown below.

Variational Student: Learning Compact and Sparser Networks in Knowledge Distillation Framework (2019)
The approach proposed in this paper is known as Variational Student. It incorporates the compressibility of the knowledge distillation framework and the sparsity inducing abilities of variational inference (VI) techniques. The authors build a sparse student network. The sparsity of this network is induced by the variational parameters found via optimizing a loss function based on VI. This is done by taking advantage of the knowledge learned from the teacher network.
This paper considers a Bayesian neural network (BNN) in a vanilla KD framework, whereby the student employs a variational penalized least-squares objective function. This ensures that the student network is compact as compared to the teacher network by the virtue of KD. It enables the integration of sparsity techniques, such as sparse variational dropout (SVD) and variational Bayesian dropout (VBD). This leads to the achievement of a sparse student.

Some of the results obtained with this method are shown below.

Improved Knowledge Distillation via Teacher Assistant: Bridging the Gap Between Student and Teacher (2019)
This paper shows that the performance of the student network degrades when the gap between the teacher and the student is large. The paper introduces a teacher assistant — a multi-step knowledge distillation — that bridges the gap between the student and the teacher. The approach is tested on CIFAR-10 and CIFAR-100 datasets.
The paper introduces Teacher Assistant Knowledge Distillation (TAKD), along with intermediate models known as teacher assistants (TAs). The TA models are distilled from the teacher, and the student is only distilled from the TAs.

Figure 2 below shows the distillation performance as the teacher size increases. Figure 3 shows that decreasing the student size increases the student’s performance.

The approach is evaluated using plain CNN and ResNet architectures. Here are some of the accuracies obtained with different TA sizes:

On the Efficacy of Knowledge Distillation (ICCV 2019)
This paper is majorly concerned with the ability of knowledge distillation techniques to effectively generalize in the training of the student network. According to the authors’ findings, a higher accuracy on the teacher network doesn’t necessarily mean a high accuracy for the student network. The network architectures used in this paper are ResNet, WideResNet, and DenseNet.

The figure below shows the error plot of student networks distilled from different teachers on CIFAR10.

The experiment was also conducted on ImageNet, with ResNet18 as the student and ResNet18, ResNet34, ResNet50, and ResNet152 as teachers. The experiments prove that bigger models aren’t better teachers.

The figure below shows that the reason bigger models are not better teachers is that the student network is unable to mimic the large teachers.

A solution proposed in this paper is to stop the teacher training early in order to obtain a solution that’s more amenable to the student.
Dynamic Kernel Distillation for Efficient Pose Estimation in Videos (ICCV 2019)
Localization of body joints in human pose estimation applies large networks on every frame in a video. This process usually incurs high computational costs. The authors of this paper propose Dynamic Kernel Distillation (DKD) to address this challenge.
DKD introduces a lightweight distillator to online distill pose kernels through enlarging temporal cues from the previous frame in a one-shot feed-forward manner. DKD simplifies body joint localization into a matching procedure between the pose kernels and the current frame. DKD transfers pose knowledge from one frame to provide guidance for body joint localization in the following frame. This enables the use of small networks in video-based pose estimation.

Dynamic Kernel Distillation for Efficient Pose Estimation in Videos
The training process is performed by exploiting a temporal adversarial training strategy. This strategy introduces a temporal discriminator to generate temporally coherent pose kernels and pose estimation results within a long range. This approach is tested on the Penn Action and Sub-JHMDB benchmarks.
The architecture of this approach is shown below. It’s made up of a pose initializer, a frame encoder, a pose kernel distillator, and a temporally adversarial discriminator. DKD uses the pose initializer to estimate its confidence maps. The frame encoder is responsible for extracting high-level features to match the pose kernel from the pose kernel distillator. The pose kernel distillator takes the temporal information as input and distills the pose kernels in a one-shot feed-forward manner. And the temporally adversarial discriminator is used to enhance the learning process of the pose kernel distillator, with confidence map variations as auxiliary temporal supervision.

Some of the results obtained with the Penn Action dataset are shown below:

Here’s a comparison of the results obtained on the Penn Action and Sub-JHMDB datasets.

DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter (NeurIPS 2019)
This paper proposes a way to pre-train a smaller general-purpose language representation model, known as DistilBERT — a distilled version of BERT. The architecture of DistilBERT is similar to that of BERT.
The performance of this approach compared to BERT is shown below.

DistilBERT is distilled on very large batches leveraging gradient accumulation, using dynamic masking and without the next sentence prediction objective. It’s trained on the original corpus of the BERT model and was assessed on the General Language Understanding Evaluation (GLUE) benchmark. DistilBERT retains 97% the performance of BERT and is 60% faster.
Conclusion
We should now be up to speed on some of the most common — and a couple of very recent — model distillation methods.
The papers/abstracts mentioned and linked to above also contain links to their code implementations. We’d be happy to see the results you obtain after testing them.
Related Articles