Imagine scrolling through your favorite online platform, whether it’s Netflix, YouTube, or Spotify, searching for that perfect movie, video, or song that matches your tastes. It can be daunting. Fortunately, recommender systems can help!
Have you ever wondered how these systems work behind the scenes? How do they predict what movies or songs you might like? Well, the answer lies in the power of optimization. Optimizing recommender systems is crucial to enhance their performance and provide accurate recommendations that resonate with each user.
Recommender systems are the unsung heroes behind the scenes, quietly analyzing our preferences, interests, and behaviors to provide us with personalized recommendations. They’re like our trusty digital companions, always ready to suggest the next great movie, the perfect song to lift our spirits, or the latest viral video.
Get ready to embark on a journey where we unravel the secrets behind optimizing recommender systems for online platforms. We will explore the challenges, the techniques, and the insights that Comet can bring to the table. So, let’s dive in and discover how we can make your online experience even more delightful with optimized recommender systems!
Selection of Recommender System Algorithms:
When selecting recommender system algorithms for comparative study, it’s crucial to incorporate various methods encompassing different recommendation approaches. This diversity ensures a comprehensive understanding of each algorithm’s performance under various scenarios.
One fundamental category is Collaborative Filtering (CF), which predicts user preferences based on collected data from numerous users. Within CF, there are two primary approaches. User-Based Collaborative Filtering (UB-CF) suggests items based on users with similar preferences. For example, if two users have rated several items similarly, the system might recommend an item liked by one user to the other. On the other hand, Item-Based Collaborative Filtering (IB-CF) focuses on item similarities. If a user likes a specific item, the system recommends other items that similar users have rated highly.
Another critical approach is Content-Based Filtering. This method utilizes item features (like genre or author in books and directors or actors in movies) to recommend items similar to those the user has shown interest in. For instance, if a user frequently watches sci-fi movies, the system might recommend other movies in the same genre.
Hybrid Systems blend collaborative filtering and content-based filtering, often resulting in more accurate recommendations. These systems can operate by combining predictions from both methods or integrating content-based capabilities into a collaborative filtering framework. The versatility of hybrid systems allows them to leverage the strengths of both approaches.
Matrix Factorization Techniques, such as Singular Value Decomposition (SVD), have gained popularity, especially in scenarios with large, sparse datasets. These techniques decompose the user-item interaction matrix into lower-dimensional matrices, capturing latent factors representing user preferences and item characteristics.
With the advent of Deep Learning, recommender systems have seen significant advancements. These methods accurately capture complex, non-linear relationships between users and items. Techniques like autoencoders, neural collaborative filtering, and recurrent neural networks (RNNs) are examples of this approach, offering nuanced and sophisticated recommendation capabilities.
Knowledge-Based Systems take a different approach, relying on explicit knowledge about users and items. They are particularly beneficial when there is insufficient user-item interaction data to employ collaborative or content-based methods effectively.
Context-Aware Recommenders consider the specific context of recommendations, such as time, location, or social circumstances. Adapting to these contextual factors can provide more relevant and timely recommendations.
A comprehensive study of recommender systems should ideally include a range of these algorithms, each offering unique strengths and catering to different aspects of user preference and behavior. The selection of algorithms should align with the dataset’s specific characteristics and the recommendation system’s overall goals.
Dataset Selection
Enter the “1,2,3,4,5 Dataset” — a seemingly simple yet intriguing dataset. Despite its modest numbers, it holds the secrets to understanding user opinions and preferences through numerical ratings. Users express their thoughts by assigning ratings ranging from 1 to 5, showing their likes, dislikes, and unique tastes.
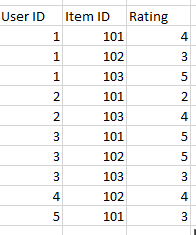
This dataset has five users (Users 1 to 5) and three items (Items 101 to 103). Each user has assigned a rating from 1 to 5 to different items based on their preferences.
Integration of Comet: Unleashing the Power of Experiment Management and Performance Tracking
We need to install and set Comet up to get started with the library in our Python environment.
Comet — Build better models faster
pip install comet_ml
After installation, we can import the Comet library into our code and initialize it with our Comet API key.
from comet_ml import Experiment
experiment = Experiment(
api_key = "YOUR-COMET-API-KEY",
project_name = "gicheru",
workspace= "innocent"
)
# Report multiple hyperparameters using a dictionary:
hyper_params = {
"learning_rate": 0.5,
"steps": 100000,
"batch_size": 50,
}
experiment.log_parameters(hyper_params)
# Or report single hyperparameters:
hidden_layer_size = 50
experiment.log_parameter("hidden_layer_size", hidden_layer_size)
# Long any time-series metrics:
train_accuracy = 3.14
experiment.log_metric("accuracy", train_accuracy, step=0)
# Run your code and go to /
Comparative Analysis: Unveiling Cosmic Performance
Dataset Loading and Preprocessing
import pandas as pd
# Load the dataset
data = {
'User ID': [1, 1, 1, 2, 2, 3, 3, 3, 4, 5],
'Item ID': [101, 102, 103, 101, 103, 101, 102, 103, 102, 101],
'Rating': [4, 3, 5, 2, 4, 5, 5, 3, 4, 3]
}
dataset = pd.DataFrame(data)
# Perform preprocessing steps (if required)
# ...
Dataset Splitting
from sklearn.model_selection import train_test_split
# Split the dataset into features (X) and target (y)
X = dataset[['User ID', 'Item ID']]
y = dataset['Rating']
# Split the data into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Print the shapes of the resulting datasets
print("Training set shape:", X_train.shape, y_train.shape)
print("Test set shape:", X_test.shape, y_test.shape)
Building and Training Recommender System Models
# Build and train recommender system models
# Example using collaborative filtering with surprise library
from surprise import Dataset, Reader, KNNBasic
from surprise.model_selection import cross_validate
# Prepare the data in Surprise format
reader = Reader(rating_scale=(1, 5))
surprise_data = Dataset.load_from_df(data[['User ID', 'Item ID', 'Rating']], reader)
# Define the model
model = KNNBasic()
# Perform cross-validation
cross_validate(model, surprise_data, measures=['RMSE', 'MAE'], cv=5, verbose=True)
# Train the model on the full training set
trainset = surprise_data.build_full_trainset()
model.fit(trainset)
Tracking Experiments with Comet:
# Import Comet.ml and initialize the experiment
from comet_ml import Experiment
experiment = Experiment(api_key="K41zohhUKne75k57jmZvBivYD", project_name="recommender-system")
# Log important information and parameters
experiment.log_dataset_info(name="1,2,3,4,5 Dataset")
experiment.log_parameters({"model": "KNNBasic", "cv": 5})
# Start tracking metrics during training
for epoch in range(num_epochs):
# Training code
# ...
# Log metrics
experiment.log_metric("loss", loss_value, step=epoch)
Evaluating Model Performance and Comparing Results
# Evaluate model performance on the test set
from surprise import accuracy
testset = surprise_data.construct_testset(test_data[['User ID', 'Item ID', 'Rating']].values)
predictions = model.test(testset)
# Calculate evaluation metrics
rmse = accuracy.rmse(predictions)
mae = accuracy.mae(predictions)
# Compare results with other models
# ...
Visualizing Experiment Metrics and Performance using Comet
# Visualize experiment metrics and performance
# Example using Comet.ml's interactive charts and graphs
# Log metrics and performance
experiment.log_metric("RMSE", rmse)
experiment.log_metric("MAE", mae)
# Generate visualizations
experiment.display()
In our quest to optimize recommender systems, we’ve uncovered their immense potential in enhancing user experiences on online platforms. Comet has been our guiding star, empowering us to manage experiments and track performance effortlessly.
Through techniques like feature engineering, hyperparameter tuning, and evaluation metrics, we’ve fine-tuned our models to deliver personalized recommendations that captivate users. With Comet, we’ve gained valuable insights and made informed decisions to elevate our recommender systems.
The impact of optimization is profound — user satisfaction soars, engagement deepens, and online platforms become realms of discovery and delight. By embracing recommender system optimization and harnessing the power of Comet, we can shape a digital universe where every recommendation is a revelation.
As we bid farewell to our journey, let us continue to optimize and explore the vast possibilities. With Comet as our ally, we can create a celestial online experience that leaves a lasting impression on users.
Together, let’s forge ahead, fueled by the desire to optimize recommender systems and unlock the true potential of online platforms. The cosmos of optimized recommendations await, ready to delight and inspire users around the globe.
Resources
Comet Documentation: Comet’s official documentation provides detailed information on integrating Comet into machine learning projects, tracking experiments, and visualizing results.
Comet — Build better models faster
TensorFlow Recommenders: TensorFlow Recommenders is an open-source library that provides tools and algorithms for building recommender systems using TensorFlow. It offers implementation examples and code snippets that can be referenced.
By leveraging these resources, you can deepen your understanding of recommender systems, explore optimization techniques, and utilize Comet effectively in your projects. Happy exploring and optimizing!
