
Introduction
Natural language processing (NLP) is the field that gives computers the ability to recognize human languages, and it connects humans with computers. One can build NLP projects in different ways, and one of those is by using the Python library SpaCy.
This post will go over how the most cutting-edge NLP software, SpaCy, operates. You will also discover SpaCy’s outstanding attributes and how they differ from NLTK, which offers an intriguing look at NLP.
What is spaCy?
SpaCy is a free, open-source library written in Python for advanced Natural Language Processing. If you are working as a developer and your work involves a lot of text, then you definitely need to know more about it.
SpaCy is designed specifically to build applications that process and understand large volumes of text data. One of SpaCy’s important strengths is its adaptability to construct and use specific models for NLP tasks, such as named entity identification or part-of-speech tagging. Developers can fine-tune their apps using relevant data to meet the needs of their particular use cases.
SpaCy has sophisticated entity recognition, tokenization, and parsing functions. It also supports a wide variety of widely used languages. SpaCy is a suitable option for developing production-level NLP applications because it is quick and effective at runtime.

With SpaCy, you may use a pipeline to transform the raw text into the final Doc, and enabling you to add additional pipeline components to your NLP library and respond to user input.
It offers a ton of fantastic pre-trained models in a variety of languages, but it also enables you to train your own models using your own data to optimize for a particular use case.
Installation of SpaCy
The installation of Python on the system is a prerequisite for configuring SpaCy. They are available for download and installation on the Python website.
Installing SpaCy and its model is the next step after installing Python and pip. The following command can be used to accomplish this.
pip install spacy
python -m spacy download en_core_web_sm
By executing this, the small English model—which covers fundamental NLP features like tokenization, POS tagging, and dependency parsing — will be downloaded. Developers can also download larger models with extra capabilities like named entity recognition and word vectors if they require more sophisticated capabilities.
Comet is now integrated with SpaCy! Learn more and get started for free today.
Objects and Features of SpaCy
Using container objects, you may get at the linguistic characteristics that SpaCy offers the text. A container object can logically represent text units such as a document, a token (a text is made up of tokens), or a section of a document.
- Doc: It is the most frequently used container object. To create our first Doc container, It is best practice to always refer to this object as “doc” (in lowercase). Next, call “nlp” object and pass the text as a single argument to construct a doc container.
with open ("dataFolder/wiki_data.txt", "r") as f:
text = f.read()
#Create a Doc container with the text file wiki_data.txt
doc = nlp(text)
#To print all the text held in The doc container
print (doc)
2. Tokenization: The fundamental text units used in every NLP activity are word tokens. It is the process of segmenting text into “tokens” made up of words, commas, spaces, symbols, punctuation, and other elements. Splitting text into tokens is the initial stage of text processing.
from spacy.lang.en import English
nlp = English()
# Process the given text line
doc = nlp("Singapore is nice place to visit")
# Select the first token from the line
token1 = doc[0]
# Print the first token from the text
print(token1.text)
Output: Singapore
The below image shows the word and their token position in the input text

3. Parts of speech (POS) tagging: SpaCy has methods for organizing sentences into lists of words and classifying each word according to its part of speech in the context. Splitting words into grammatical characteristics like nouns, verbs, adjectives, and adverbs is part of the POS process.
The below code will explain the POS tagging:
import spacy
nlp = spacy.load("en_core_web_sm")
text1 = "Susan is my neighbor; She is charming and having 1 brother"
# Now, Process the input text
doc = nlp(text1)
for token in doc:
# Get the token text, part-of-speech (POS) tag
token_text1 = token.text
token_pos1 = token.pos_
# This is for formatting only
print(f"{token_text1:<12}{token_pos1:<8}")
Output:
Susan NOUN
is AUX
my ADJ
neighbor NOUN
she PROPN
................
................
1 NUM
4. Entity recognition: Finding entities in the text is one of the most frequent labeling issues. It is a sophisticated form of language processing that recognizes significant text input items, including places, people, organizations, and languages. Since you can easily select relevant subjects or pinpoint crucial chunks of text, this is incredibly beneficial for swiftly extracting information from text.
The code in the section will demonstrate entity recognition in simple terms. To do this, first, import SpaCy and load the model to process the text. Then, iterate through each entity and output its label.
import spacy
nlp = spacy.load("en_core_web_sm")
text1 = "Upcoming iPhone XII release date leaked as apple discloses it's pre-orders"
# Process the input text
doc = nlp(text1)
# Iterate over the entities
for ent in doc.ents:
# Print the entity from the input text and label
print(ent.text, ent.label_)
Output: Apple ORG
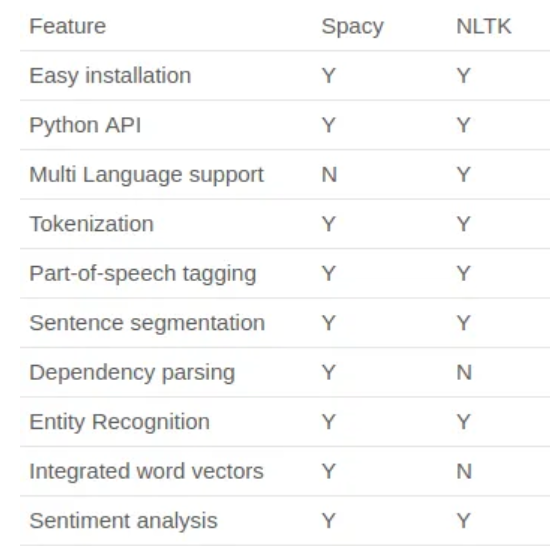
Difference between SpaCy and NLTK
NLTK and SpaCy differ significantly in several ways.
1. NLTK can support various languages, but SpaCy has models for only seven languages: English, French, German, Spanish, Portuguese, Italian, and Dutch.
2. SpaCy uses an object-oriented approach where, when you parse a text, it will return a document object whose words and sentences are objects themselves, whereas NLTK takes strings as input and returns strings or lists of strings as output because it is a string processing library.
3. The performance of SpaCy is typically better than that of NLTK since it uses the most up-to-date and effective algorithms. SpaCy performs better in word tokenization and POS tagging, whereas NLTK surpasses SpaCy in sentence tokenization.
4. NLTK does not have support for word vectors, but SpaCy has that feature.
The below image shows the quick difference between NLTK and SpaCy.
Conclusion
When developing an NLP system, NLTK and SpaCy are both excellent choices. But as we’ve seen, SpaCy is the best tool to employ in a real-world setting due to its high user-friendliness and performance, which are driven by its core principle, providing a service rather than just a tool. Hopefully, this article has inspired you to experiment with SpaCy.
