
In the ever-evolving landscape of artificial intelligence and machine learning, researchers and practitioners continuously seek to elevate the capabilities of intelligent systems. Among the myriad breakthroughs in this field, Meta-Learning is pushing the boundaries of machine learning.
Meta-Learning presents a radical departure from conventional approaches by endowing machines with the extraordinary ability to learn how to learn. At its core, Meta-Learning equips algorithms with the aptitude to quickly grasp new tasks and domains based on past experiences, paving the way for unparalleled problem-solving skills and generalization abilities.
This article explores Meta-Learning by delving into the cutting-edge algorithms driving its advancements and the diverse applications that redefine machine learning paradigms. Beyond a theoretical approach, this article further integrates Comet, a powerful experiment management platform that enriches the Meta-Learning landscape. With Comet’s integrated suite of tools, we will perform a meta-learning task using the Omniglot dataset.
What is Meta-Learning?
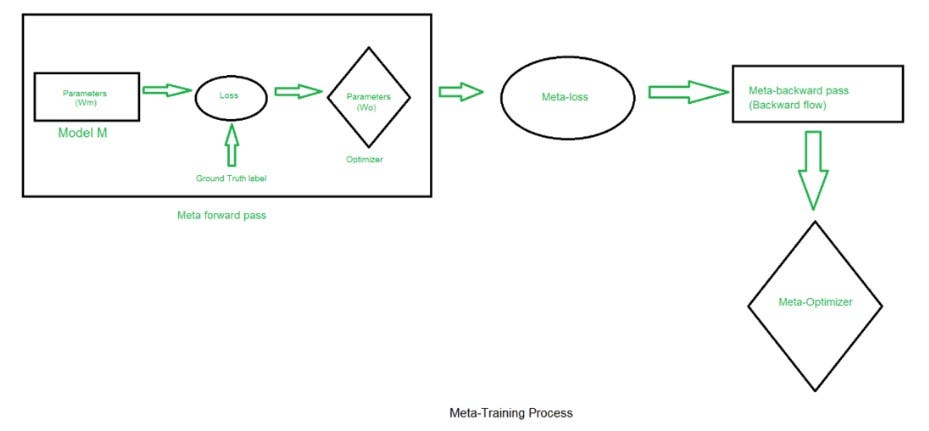
Meta-Learning, also known as “learning to learn” or “higher-order learning,” is a subfield of machine learning that focuses on equipping algorithms with the ability to learn how to learn efficiently. Instead of solely learning to solve specific tasks, meta-learning aims to improve the learning process itself, enabling models to adapt quickly to new, previously unseen tasks based on past experiences.
Imagine an AI system that becomes proficient in many tasks through extensive training on each specific problem and a higher-order learning process that distills valuable insights from previous learning endeavors. Such a system has the potential to revolutionize diverse domains, from computer vision and natural language processing to reinforcement learning and optimizer design.
Why Use Meta-Learning?
According to Sebastian Thrun, a leading figure in AI and robotics, Meta-Learning seeks to discover ways to dynamically search for the perfect learning strategy as the number of tasks increases. Also, Vilalta and Drissi, in the article “A Perspective View and Survey of Meta-Learning,” emphasize that Meta-Learning understudies how learning systems can increase their efficiencies through experiences by understanding how “learning” itself can become more flexible according to the task or domain being studied.
Meta-Learning takes a holistic approach by training models on diverse tasks and datasets based on data assumptions. The model learns from this meta-dataset and generalizes its knowledge to novel functions with only a few examples, sometimes referred to as few-shot learning.
A typical Meta-Learning process includes the following components:
- Meta-Learner: The primary learning algorithm or model responsible for acquiring knowledge from the meta-dataset and adapting its parameters to learn new tasks quickly.
- Task Distribution: A distribution of tasks from the meta-dataset that the meta-learner uses to simulate new and unseen tasks during training and evaluation.
- Meta-Data: The experiences gained from training on various tasks in the meta-dataset, which the meta-learner uses to inform its adaptation to new tasks.
These components endow models with the capacity to effectively generalize across different tasks, domains, or datasets, reducing the need for vast task-specific training data.
Prominent Meta-Learning Approaches
Meta-Learning runs on algorithms that control how the system swiftly adapts to novel tasks with minimal data. These approaches form the backbone of the system’s agility, enabling it to quickly grasp new concepts, learn from limited examples, and apply knowledge across various challenges. With new Meta-Learning algorithms being developed, some prominent approaches include:
Model-Agnostic Meta-Learning (MAML)
Model-Agnostic Meta-Learning (MAML) is an algorithm that epitomizes the essence of Meta-Learning. MAML trains a model’s initial parameters to fine-tune rapidly for new tasks with just a few examples. This process is achieved by optimizing the model’s parameters to enable efficient adaptation across a distribution of functions. MAML’s framework is not tied to a specific model architecture, making it incredible and applicable across various domains, from computer vision to natural language processing.
Reptile (Meta-SGD)
Reptile, also known as “Meta-SGD,” delves into the essence of optimization itself. It is a meta-learning algorithm that falls under model-agnostic meta-learning approaches. OpenAI introduced it in their research to explore methods for enhancing the adaptation capabilities of machine learning models across various tasks.
Reptile simulates the process of stochastic gradient descent (SGD) meta-optimization by gradually adapting a model’s parameters across multiple tasks. It emphasizes fast convergence during the fine-tuning process and demonstrates the power of simple yet effective strategies in Meta-Learning.
Memory-Augmented Neural Networks (MANNs)
The path that led to Memory-Augmented Neural Networks started with conceptualizing the Neural Turing Machine (NTM). NTMs introduced the revolutionary concept of incorporating dynamic memory storage into neural networks. Memory-Augmented Neural Networks (MANNs) take inspiration from human memory systems to enhance Meta-Learning. These architectures contain external memory banks that allow models to store task-specific information for rapid retrieval during adaptation.
For instance, in few-shot image classification, a MANN, having learned representations of different image attributes from diverse tasks, can promptly adapt to a new object category with only a handful of examples. This flexibility stems from the MANN’s ability to selectively retrieve relevant information from its external memory, facilitating faster adaptation and reducing the demand for extensive task-specific training.
Learning to Learn (L2L) Initialization
Learning to Learn Initialization focuses on the critical moment of initializing a model’s parameters. This algorithm explores the optimal initialization strategy, ensuring that models start with a configuration that facilitates quick adaptation to new tasks. Enhancing this initial state, L2L minimizes the required learning iterations for adaptation. The L2L paradigm showcases how the right starting point can significantly expedite the Meta-Learning process.
Meta-RL: Meta-Reinforcement Learning
Meta-RL bridges the gap between Meta-Learning and Reinforcement Learning (RL), showcasing how adaptability extends to dynamic environments. Thus, Meta-RL agents learn to generalize their policy learning strategies by training on the distribution of tasks in various environments. This enables them to quickly adapt to new environments, reinforcing the principles of meta-learning in the context of RL.
Performing a Meta-Learning Task With Comet
This section will explain a basic example of conducting a meta-learning task using the Comet platform. Specifically, we will utilize the Omniglot dataset. This dataset is renowned for its suitability in evaluating models’ abilities to learn from a limited number of examples per class.
Step 1: Set Up Comet Experiment
The first step is to set up your Comet environment. Comet is a platform for experiment tracking and reproducibility in machine learning. Comet lets you easily track and compare experiments, visualize results, and collaborate.
We will install the package with the following command:
!pip install comet_ml
Step 2: Import Required Libraries and Modules
Next, we gather the essential tools needed for this task. We will import key libraries and modules to lay the foundation for building our meta-learning solution.
import comet_ml
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
# Import your custom dataset module and meta-learning model
from omniglot_dataset import OmniglotDataset
from model import MetaLearner
Step 3: Set Hyperparameters and Preprocessing
In this phase, we establish the parameters that guide our Meta-Learning process. We will set hyperparameters, such as the number of classes, shots, queries, epochs, and learning rates, to define the core parameters that govern our model’s behavior.
Also, we lay the groundwork for data preprocessing by specifying transformations that transform raw data into a format suitable for training. This step forms the backbone of our meta-learning configuration, ensuring that our model operates precisely and adaptably.
num_classes = 5
num_shots = 5
num_queries = 5
num_epochs = 10
learning_rate = 0.001
transform = transforms.Compose([
transforms.Resize((28, 28)),
transforms.ToTensor(),
])
Step 4: Load the Omniglot Dataset
Loading the Omniglot dataset involves accessing the collection of images that represent various handwritten characters from multiple alphabets. These images will serve as the foundation for our model to learn from a few examples per class.

We will initiate the loading process of the Omniglot dataset with this line of code:
# Load Omniglot dataset
train_dataset = OmniglotDataset(root_dir="path/to/omniglot/train", transform=transform)
train_loader = DataLoader(train_dataset, batch_size=num_classes, shuffle=True)
The dataset is stored in a directory specified by the root_dir parameter. The path/to/omniglot/train placeholder should be replaced with the path to the directory where your training data is stored.
Step 5: Initialize the Meta-Learner Model
Here, we will initialize the model, defining its structure, including the number of classes it will be trained on, the number of shots (examples) per class in the support set, and the number of queries for evaluation. Let’s use this command for that:
# Initialize the MetaLearner model
meta_learner = MetaLearner(num_classes, num_shots, num_queries)
Step 6: Define the Loss Function and Optimizer
With our Meta-Learner model ready, let’s proceed to equip it with the tools for refinement — the loss function and optimizer. The loss function quantifies the difference between the predicted outputs of our model and the ground truth labels. At the same time, the optimizer steers the process of fine-tuning the model’s parameters to minimize the loss. We will set it with the following:
# Define loss and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(meta_learner.parameters(), lr=learning_rate)
Step 7: Training Loop
Within the training loop, we iterate through data from the Omniglot dataset. Each batch consists of support sets (examples used for learning) and query sets (examples used for evaluation).
In the forward pass, the Meta-Learner model processes the support set and generates predictions for the query set. These predictions are then compared to the actual labels to compute the loss. Also, backpropagation computes the gradients of the model’s parameters concerning the loss. The optimizer then adjusts these parameters to minimize the loss, thus fine-tuning the model’s performance.
Throughout the training loop, we log key metrics, such as the loss, using Comet. This logging aids in tracking the model’s progress and provides insights into its learning trajectory.
Let’s run this command with the following code:
# Training loop
for epoch in range(num_epochs):
for batch_idx, (support_set, query_set) in enumerate(train_loader):
optimizer.zero_grad()
# Move data to device (e.g., GPU)
support_set = support_set.to(device)
query_set = query_set.to(device)
# Forward pass and backward pass
loss = meta_learner(support_set, query_set)
loss.backward()
optimizer.step()
# Log loss to Comet ML
experiment.log_metric("loss", loss.item(), step=batch_idx + epoch * len(train_loader))
Step 8: Log Final Metrics and End Experiment
After completing the training loop, we will log the final metrics encapsulating our Meta-Learner model’s performance.
# Log final metrics and close the experiment
experiment.log_metric("final_loss", loss.item())
experiment.end()
We create a tangible record of our model’s accomplishments by recording these metrics, such as the final loss. This information validates our efforts and provides a comprehensive overview of the model’s capabilities.
You should have a final visualization of the Omniglot dataset looking like this:

Benefits of Meta-Learning
Meta-Learning brings innovation to machine learning, and its array of benefits includes the following enhancements that resonate across various applications and challenges:
- Greater Efficiency: Meta-Learning redefines learning, enabling models to glean insights from various tasks. This heightens learning efficiency, reducing the need for extensive data to grasp new concepts and surpassing the data-hungry norm.
- Rapid Adaptation to New Tasks: The core of Meta-Learning lies in swiftly equipping models to adapt to new tasks. This agile ability enables AI to pivot seamlessly across domains, industries, and unforeseen scenarios.
- Zero-Shot and Few-Shot Learning: Meta-Learning transforms limited data from challenge to opportunity. With the ability to learn from related tasks, it empowers models for success in few-shot and zero-shot learning scenarios, reducing the need for extensive labeled examples.
- Enhanced Generalization: Through diverse task exploration, Meta-Learning imparts models with a comprehensive grasp of underlying patterns. This results in exceptional generalization, enabling AI to apply insights from one task to different problem domains.
- Reduced Annotation Burden: Learning from minimal data lessens annotation workload. Meta-Learning’s adaptability frees AI practitioners from labor-intensive dataset annotation, becoming a powerful driver of resource-efficient learning.
- Transferable Expertise: The skills gained from Meta-Learning extend beyond individual tasks, forming a versatile foundation of knowledge. This expertise smoothly applies to different challenges, guiding AI into multitasking and adaptive specialization.
Potential Challenges in Meta-Learning
Several challenges might occur with Meta-Learning, adding complexity to this approach. These challenges, though tough, may inspire innovation and help meta-learning enthusiasts expand their possibilities:
- Adaptation and Overfitting Balance: Striking the delicate balance between adapting to new tasks while avoiding overfitting is like fine-tuning an instrument. Too much adaptation might lead to losing sight of broader patterns, while too little might hinder swift learning.
- Architecture for Task Generalization: Another challenge is the “transferability bottleneck.” Imagine trying to drive a different type of vehicle after mastering a car — you might struggle to adapt despite your driving expertise. Similarly, when our model excels in one task, transferring that knowledge effectively to a new, related task might be difficult. This hurdle pushes us to create architectures that can smoothly move expertise from one task to another, enhancing the adaptability and effectiveness of Meta-Learning systems.
- Efficient Adaptation to Novel Tasks: A model could face the challenge of adapting to novel tasks. Novel tasks refer to new and previously unseen challenges or activities a model encounters. When a model adapts swiftly to new tasks, it might prioritize some tasks over others, leading to an uneven distribution of adaptation efforts.
- High Operational Costs: The cost of operation can be a challenge for Meta-Learning. Training and adapting models in a meta-learning framework often requires significant computational resources, including powerful GPUs or TPUs. This can lead to higher operational costs regarding hardware infrastructure and energy consumption.
Various Applications of Meta-Learning
Meta-Learning applications are versatile because they tap into a fundamental concept: the ability to learn how to learn. This unique quality opens doors to many domains where AI’s adaptability and rapid knowledge acquisition are paramount. Here are several key applications that showcase the diverse impact of meta-learning:
- Personalized Healthcare: Meta-learning enables AI to adapt to individual patient profiles quickly, optimizing treatment plans and drug recommendations. For example, when a patient with a rare disease has limited available data, traditional AI models might struggle to provide tailored recommendations. However, Meta-Learning allows the AI to draw insights from related medical cases, even if they are not directly similar. This accelerates precise and effective healthcare decisions.
- Autonomous Robotics: In robotics, Meta-Learning equips machines to navigate diverse environments and tasks with minimal training data. Robots can adapt on the fly, mastering new tasks and scenarios as they arise.
- Financial Forecasting: Meta-Learning enhances economic models by quickly adapting to changing market dynamics. This agility aids in making accurate predictions and informed investment decisions.
- Natural Language Processing: With Meta-Learning, language models can be generalized across various languages and dialects. Therefore, translation, sentiment analysis, and dialogue generation tasks are accelerated.
- Recommendation Systems: Meta-Learning augments recommendation algorithms, enabling platforms to understand users’ preferences and adapt recommendations in real time.
- Industrial Automation: In manufacturing settings, Meta-Learning allows machines to adapt to new tasks easily, reducing production downtime and enhancing operational efficiency.
- Video Game AI: Game characters with Meta-Learning can adapt to players’ strategies, offering challenging and dynamic gameplay experiences.
These applications exemplify the power of Meta-Learning in diversifying AI’s capabilities and enhancing its utility across industries.
Conclusion
In conclusion, Meta-Learning is a game-changer, empowering machines to learn better, adapt faster, and solve new problems. This ability to learn how to learn takes AI to new heights, even when data is scarce. As Meta-Learning keeps growing, its influence spreads across different fields, leading us towards AI excellence and smarter systems that keep breaking limits.
Resources
- Generalization Ability || ScienceDirect
- Omniglot dataset || Kaggle
- Natural Language Processing (NLP) Tutorial || Geeksforgeeks.com
- Vilalta R. & Drissi Y. || A Perspective View and Survey of Meta-Learning
- Kondu R. (2022). Everything You Need to Know About Few-Shot Learning || Paperspace Blog
- Model-Agnostic Meta-Learning (MAML) Made Simple || InstaDeep
- Nichol, A. & Schulman, J. (2018) Reptile: A scalable meta-learning algorithm || OpenAI.com
- Xavier L. (2019). Hands On Memory-Augmented Neural Networks Build(Part One) || Towards Data Science
- Comet ML || Documentation
- A simple introduction to Meta-Reinforcement Learning || InstaDeep
