This article, written by Kurtis Pykes, first appeared on Heartbeat.
A large portion of your time as a machine learning practitioner will be dedicated to improving models. This is typically done iteratively. After an experiment has run, the results are examined to determine whether the most recent upgrade to the model had a positive impact on its performance. If it didn’t, the model will typically be discarded. If it did, the model will be kept and built upon.
Things that may be altered in each experiment include: hyperparameter values, the addition or subtraction of a feature, the model, the approach, etc. Keeping a mental note of each experimentation cycle can possibly lead to a severe migraine — especially if experiments are being run simultaneously.
Tracking experiments is a great solution to record what you’ve done in the past so you can compare past experiments. It also makes reproducing past results seamless as it can be complicated in machine learning projects. Comet’s tracking tool makes this process easy — we will be covering how it works in the remainder of this article.
In this article you will discover the following:
→ The various experiment types available in Comet ML
→ The Comet ML Experiment class
→ How to implement a Comet Experiment
→ Comparing experiments in Comet
What’s Available in Comet?
Noticing the discrepancies between machine learning projects and traditional software projects is not so obvious at first. At the end of the day, both involve writing code. But machine learning introduces two new axes to traditional software that makes projects more complex: data and models. Other factors exist too, such as:
→ Machine learning projects involve far more experimentation which can be expensive.
→ Debugging is more challenging since machine learning code doesn’t always throw errors: Instead, the model underperforms.
→ Varying any one of the axes involved in machine learning projects (data, code, model) can significantly impact the outcome of a model.
Experiment tracking is introduced as means of managing the components inherent in machine learning projects. Comet ML is a solution that permits machine learning practitioners to monitor, compare, and optimize models.
In Comet ML there are five different experiment types available which all serve a different purpose. Let’s have a look at them:
Experiment
The main experiment object in Comet is Experiment. Its role is to stream all logging of the full experiment in the background (to the cloud) so the execution of your code runs as normal. It also supports all of Comet’s auto-logging functionality and Optimizer.
“Experiment is a unit of measurable research that defines a single run with some data/parameters/code/results.
Creating an Experiment object in your code will report a new experiment to your comet.ml project. Your Experiment will automatically track and collect many things and will also allow you to manually report anything.”
—Comet ML Documentation
ExistingExperiment
If you want to run continue training for an experiment that was conducted in the past you’ll need the ExistingExperiment class. Like Experiment, the ExistingExperiment class also streams logging to the cloud in the background so that code runs as fast as normal. It also supports all of Comet’s auto-logging functionality and has the full support of the Optimizer.
“Existing Experiment allows you to report information to an experiment that already exists on comet.ml and is not currently running. This is useful when your training and testing happen on different scripts.”
— Comet ML Documentation
OfflineExperiment
When you don’t have an internet connection, or it’s intermittent, OfflineExperiment allows you to track experiments by logging its data on your local disk. The class has the full support of auto-logging functionality available in Comet.
“The
OfflineExperiment()interface allows you to log your experiment data on your local disk until you are ready to upload it from memory to comet.ml.”
— Comet ML Documentation
ExistingOfflineExperiment
The ExisitingOfflineExperiment class combines OfflineExperiment and ExistingExperiment to construct an offline experiment that continues on from an existing experiment. It streams the logging in the background to the file system so the efficiency of your code is unaffected, and supports all of Comet ML’s auto-logging functionality.
“Existing Offline Experiment allows you to report information to an experiment that already exists on comet.ml, is not currently running, but capture the logging information for later upload. This is useful when your training and testing happen on different scripts, and you have an unreliable connection to the comet.ml server.”
— Comet ML Documentation
APIExperiment
The APIExperiment class is useful when you quickly want to make experiment updates or to query and analyze experiment data offline. It’s combined with the Python API to enable the continuation or querying of experiments in a non-streaming mode.
Comet’s documentation states the Experiment class is “the only class you need.” Meaning most of the time you should use this class. Let’s implement it in a use case to see how it works.
Example Use Case
Before we can start tracking experiments we need a problem to solve. For simplicity’s sake, we will be using Scikit-learn’s make_circles function to generate a dataset. To put emphasis on tracking, we will only be using a small dataset that consists of 1000 samples. We will also add a 0.05 standard deviation of Gaussian noise to give the model a challenge — this will help us get different results for each model.
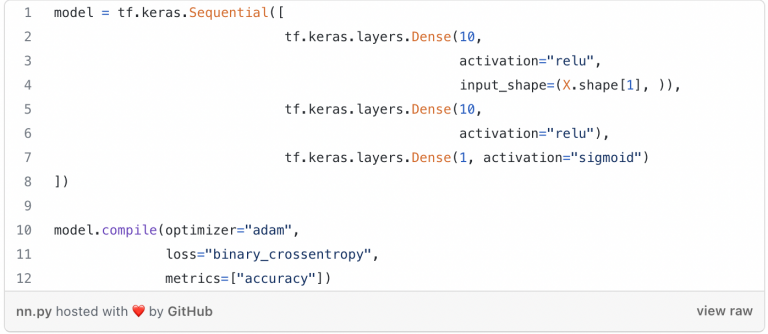
The model we will be using is a three layer neural network built using TensorFlow Keras. We will use different seeds for the random number generator to build five different models using the same architecture.
To conduct automatic logging we will call the Experiment object with the following parameters set to True:
auto_param_logging: To log the hyperparameters of the model.auto_histogram_weight_logging: To log and create a histogram for the weights and biases.auto_histogram_gradient_logging: To log and create a histogram for the gradients.auto_histogram_activation_logging: To log and create a histogram for the activations.auto_histogram_epoch_rate: To log and create a histogram of the steps and epochs.
We will log the accuracy of the model manually, although it can be done automatically using auto_metric_logging. Another parameter we will log is the random seed value used to generate random numbers for each model.
Another thing we must do is pass an API key to our Experiment so we have access to our Comet ML dashboard. I’ve also included a project name so a project is created under that name in my dashboard.
Note: Do not commit API keys to version control.
Now let’s train and test our models:

We now have successfully tracked our five experiments which can be found in our Comet ML dashboard.
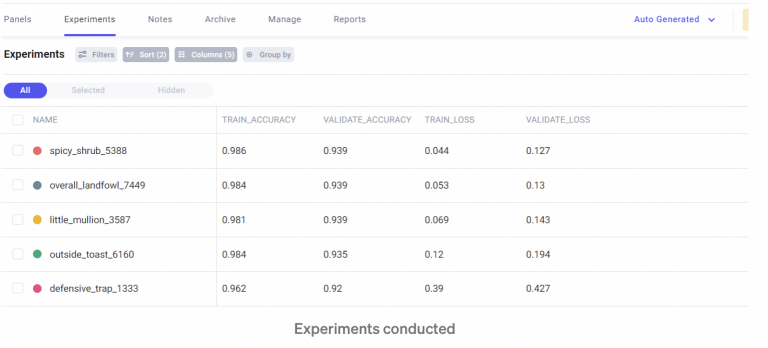
Comparing Experiments
Typically in machine learning projects, several experiments are conducted to identify a champion model to take to production. Though there is value in reviewing the performance of a model in isolation, we can derive much more feedback when experiments are reviewed in the context of other experiments.
Take the image of the table we’ve displayed above. There are only five experiments and we’ve selected only four columns to display, yet still it can be tricky to clearly identify a champion model.
A better way to compare models is to look through the Panels tab. This allows us to easily compare different models. If a model sticks out as a clear champion, clicking on it will take you to the experiment page so more digging into the model can be done.
Experiments are done iteratively to try and determine a champion model to be taken to production. Several variables are introduced into machine learning projects which make them more complex than traditional software projects. By tracking experiments, we can manage all the components involved in an experiment, which in turn makes comparing and reproducing experiments easier.