
Have you ever imagined how cool it would be to analyze, explore and visualize your data in Pandas without typing a single line of code by yourself?
The world is changing so fast with the advent of LLMs (large language models). During my quest for more knowledge on LLMs and how to better leverage what this new tech has in store, I came across YOLOPandas, a tool to interact with Pandas objects via LLMs and LangChain.
This article will dive into YOLOPandas, flex its abilities, and incorporate it with Comet.
Overview of YOLOPandas
YOLOPandas is based on Langchain, a powerful library allowing abstractions over language models from different providers. It lets you specify commands with natural language and execute them directly on Pandas objects. You can preview the code before executing or set yolo=True to execute the code straight from the LLM.
Installation
pip install yolopandas
Once imported into our notebook, YOLOPandas adds an llm accessor to Pandas DataFrames. We will consider two examples of how this works and better understand how to use it for maximum productivity.
Note: We will need an OpenAI API key, which can be found on our account here, then we will need to set it as an environment variable.
import os
os.environ['OPENAI_API_KEY'] = '*******'
First Example: Using a Dataset
We will use a movie rating dataset that I got from Kaggle. It contains data about different movies, their runtimes, IMDb ratings, where they were produced, and lots more.
- Import the libraries.
from yolopandas import pd
import matplotlib.pyplot as plt
We imported the YOLOPandas library into our notebook as well as the Matplotlib library for visualizations.
- Explore the dataset.
We can now start exploring the dataset using the LLM accessor. By default, the yolo parameter is set to false which gives us the ability to preview the code before executing and either accept it and apply it or reject it. When we set yolo=True it applies the code without any preview and executes the code straight from the LLM.
The yolo parameter is a boolean flag that controls whether or not the code is executed straight from the LLM. The yolo parameter can be used with any of the YOLOPandas query functions.
movie_reviews.llm.query("Show the first three movies in the dataset", yolo=True)
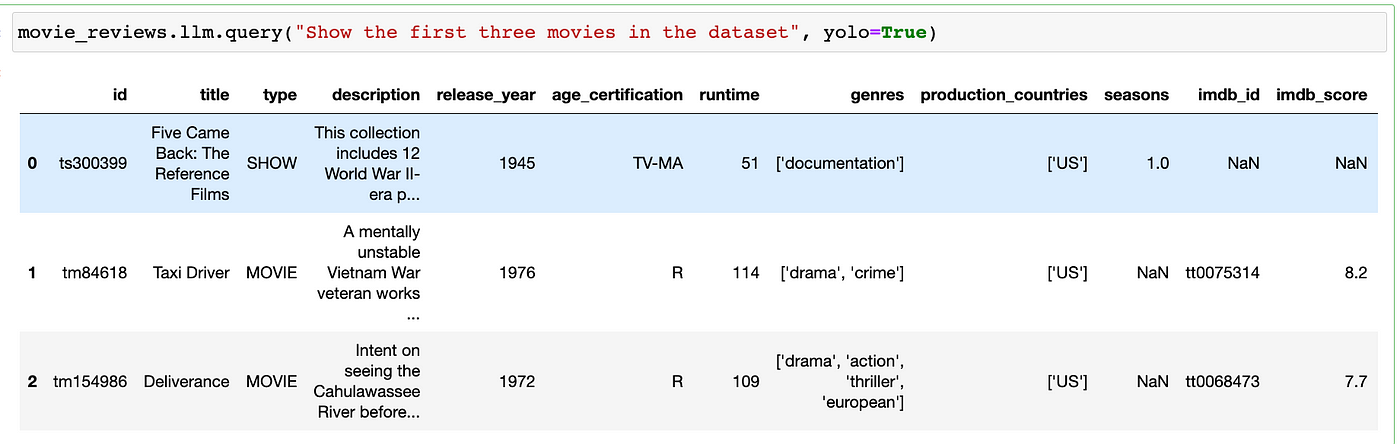
movie_reviews.llm.query("for each movie, count the number of reviews and their average score. Show the 5 with the highest reviews", yolo=True)
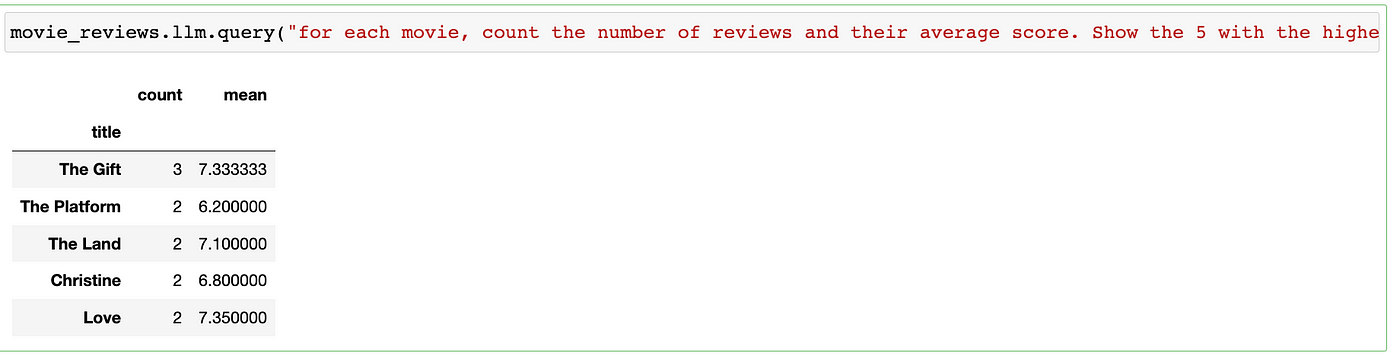
movie_reviews.llm.query("Show the row with the movie title 'The Gift' in the dataset", yolo=True)
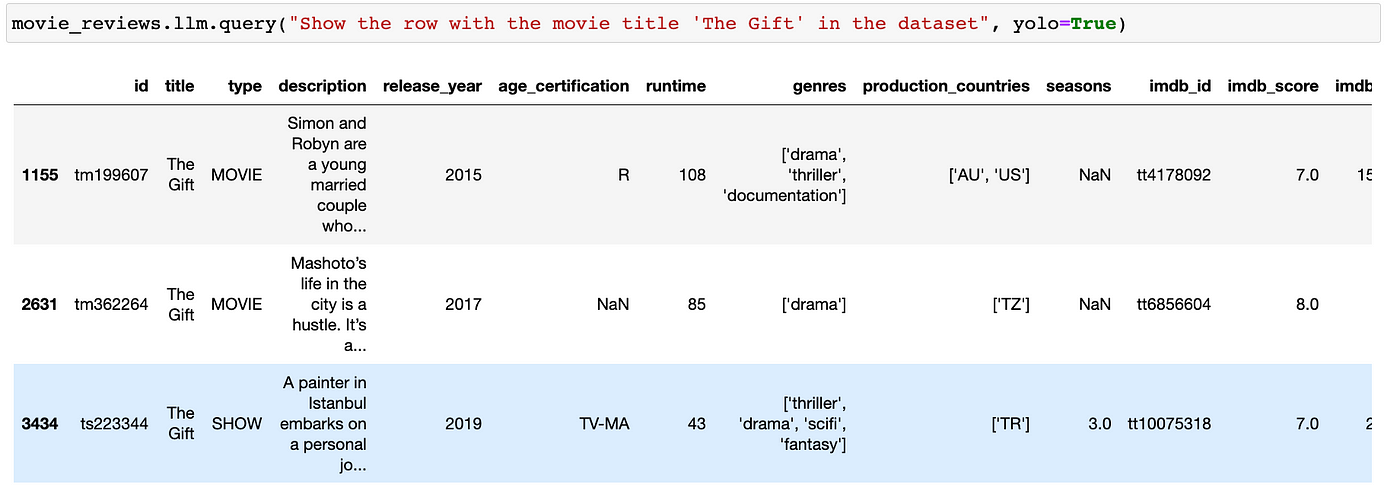
movie_reviews.llm.query("make a bar chart showing the rating of the movie The Gift", yolo=True)
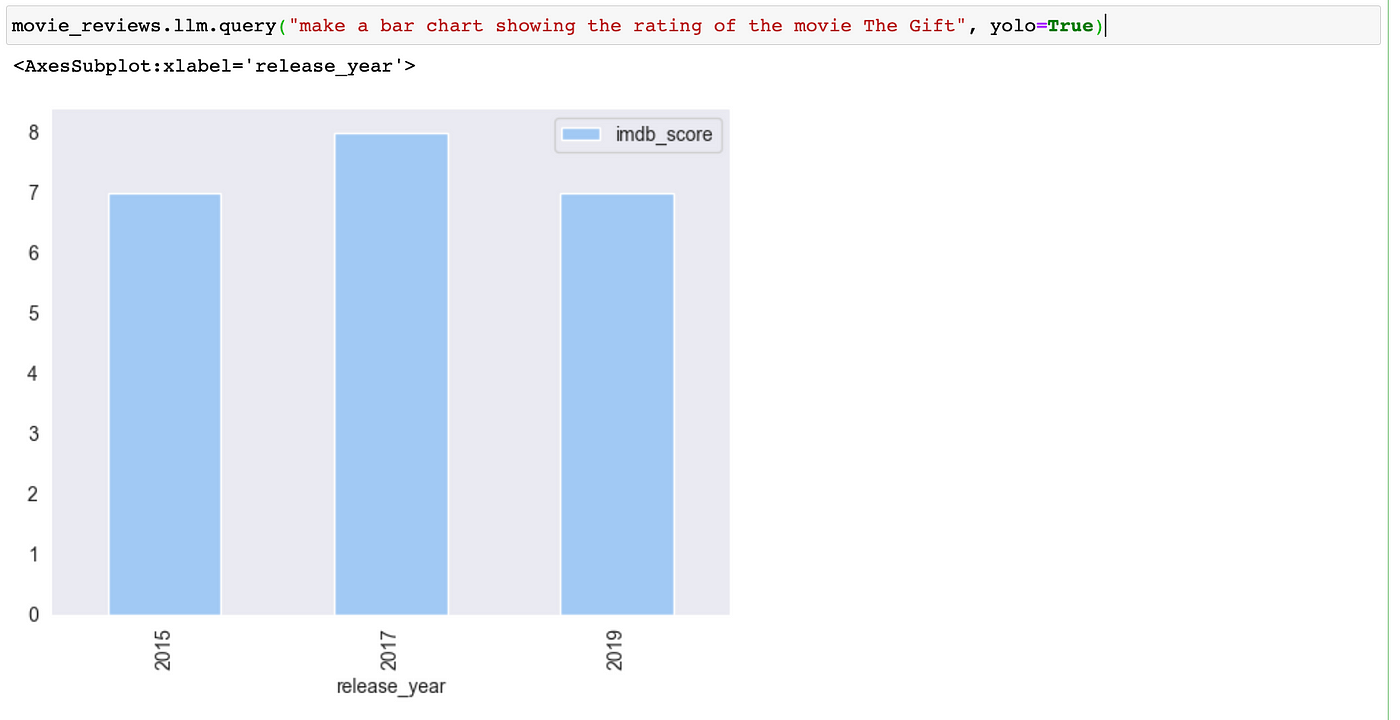
movie_reviews.llm.query("Show 5 movies with the highest rating, their year of release and production countries", yolo=True)
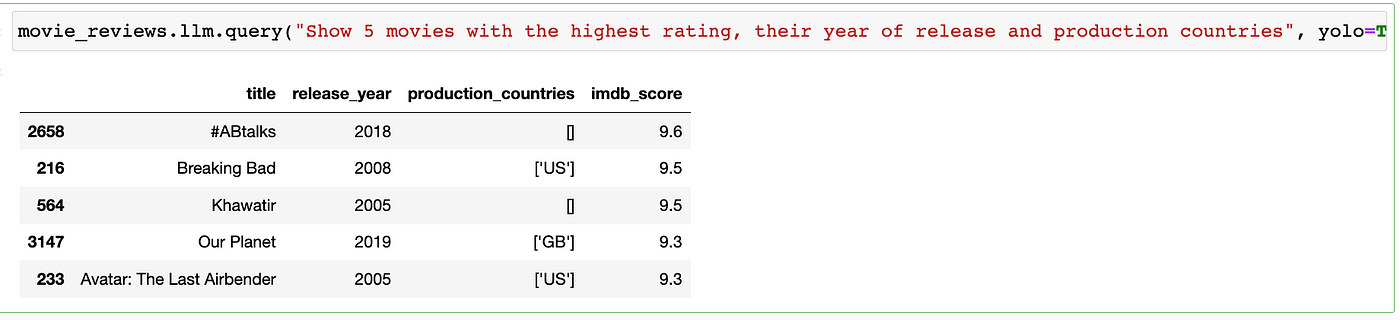
movie_reviews.llm.query("Show 5 movies with the lowest rating, their year of release and production countries", yolo=True)
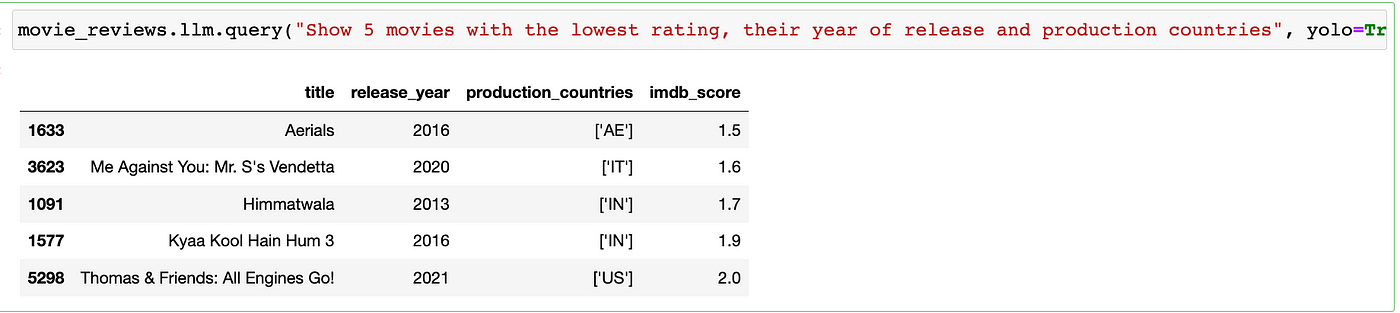
movie_reviews.llm.query("Create a line chart to show the number of movies produced in the US", yolo=True)
movie_reviews.llm.query("What is the oldest movie in the dataset", yolo=True)

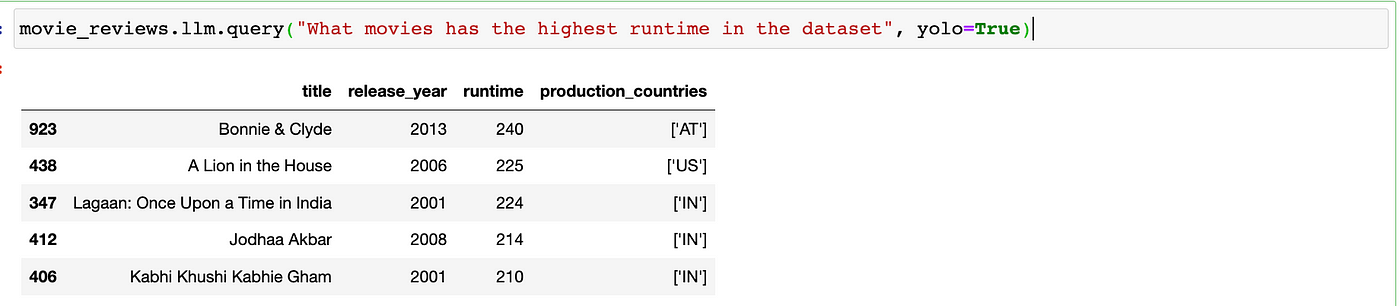
movie_reviews.llm.query("What movies has the highest runtime in the dataset", yolo=True)
You can go ahead and explore and analyze the dataset, and once we are done, we will log the dataset to Comet.
from comet_ml import Artifact, Experiment
movie_dataset = pd.read_csv("titles.csv")
artifact_one = Artifact(name="Training-dataset", artifact_type="dataset")
artifact_one.add("titles.csv")
#log the two datasets as artifacts to Comet
experiment.log_artifact(artifact_one)
We then have to end the experiment.
#End experiment
experiment.end()
Second Example: Using a Pandas DataFrame
We were able to explore a dataset in the first example. Similarly, we can do the same to a Pandas DataFrame. The first thing to do is create the DataFrame, and without YOLOPandas imported into the notebook, we can start using the LLM accessor to write the queries.
Create the DataFrame.
product_df = pd.DataFrame(
[
{"name": "The Da Vinci Code", "type": "book", "price": 15, "quantity": 300, "rating": 4},
{"name": "Jurassic Park", "type": "book", "price": 12, "quantity": 400, "rating": 4.5},
{"name": "Jurassic Park", "type": "film", "price": 8, "quantity": 6, "rating": 5},
{"name": "Matilda", "type": "book", "price": 5, "quantity": 80, "rating": 4},
{"name": "Clockwork Orange", "type": None, "price": None, "quantity": 20, "rating": 4},
{"name": "Walden", "type": None, "price": None, "quantity": 100, "rating": 4.5},
],
)
product_df

product_df.llm.query("What columns are missing values?")

product_df.llm.query("Now show me all products that are books.")

product_df.llm.query("Of these, which has the lowest items stocked?")

from IPython.display import display
df1, df2 = product_df.llm.query("Split the dataframe into two, 1/3 in one, 2/3 in the other. Return (df1, df2).")
display(df1)
display(df2)
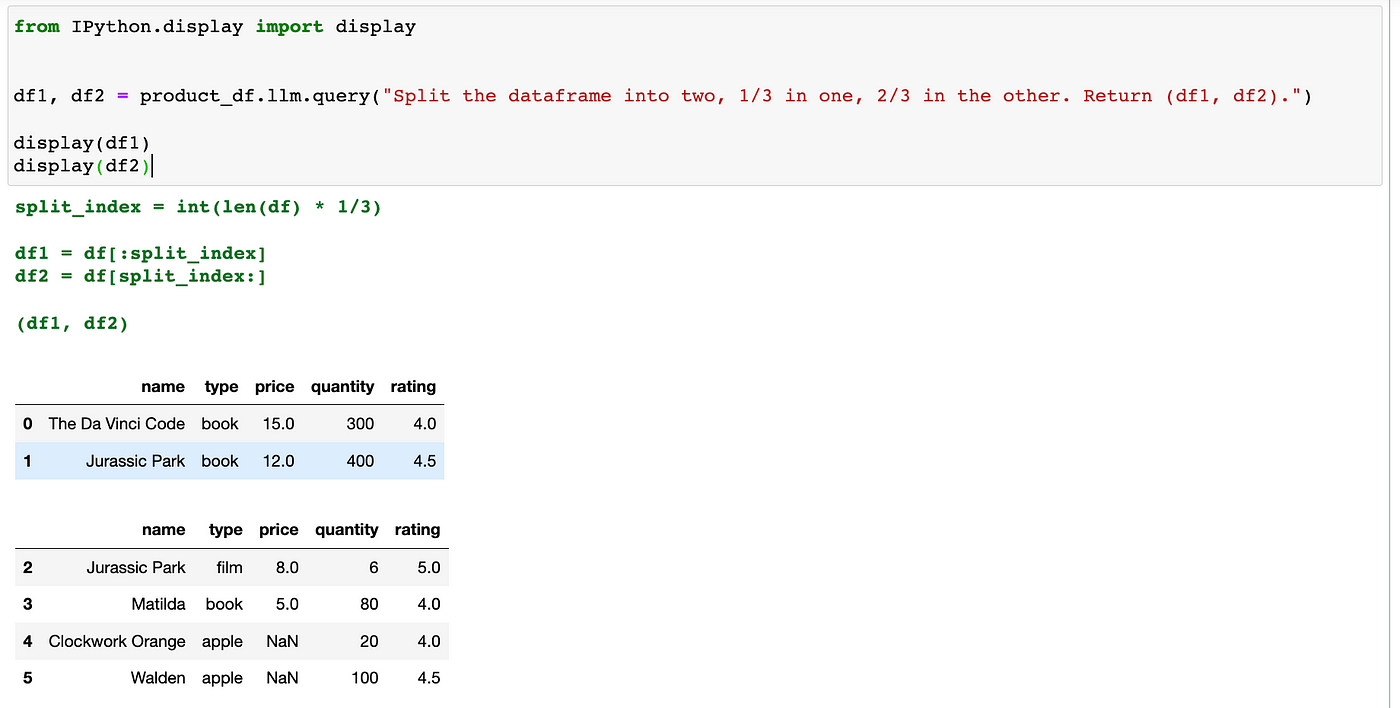
Visualize the DataFrame.
product_df.llm.query("Group by type and take the mean of all numeric columns.", yolo=True).llm.query("Make a bar plot of the result and use a log scale.", yolo=True)
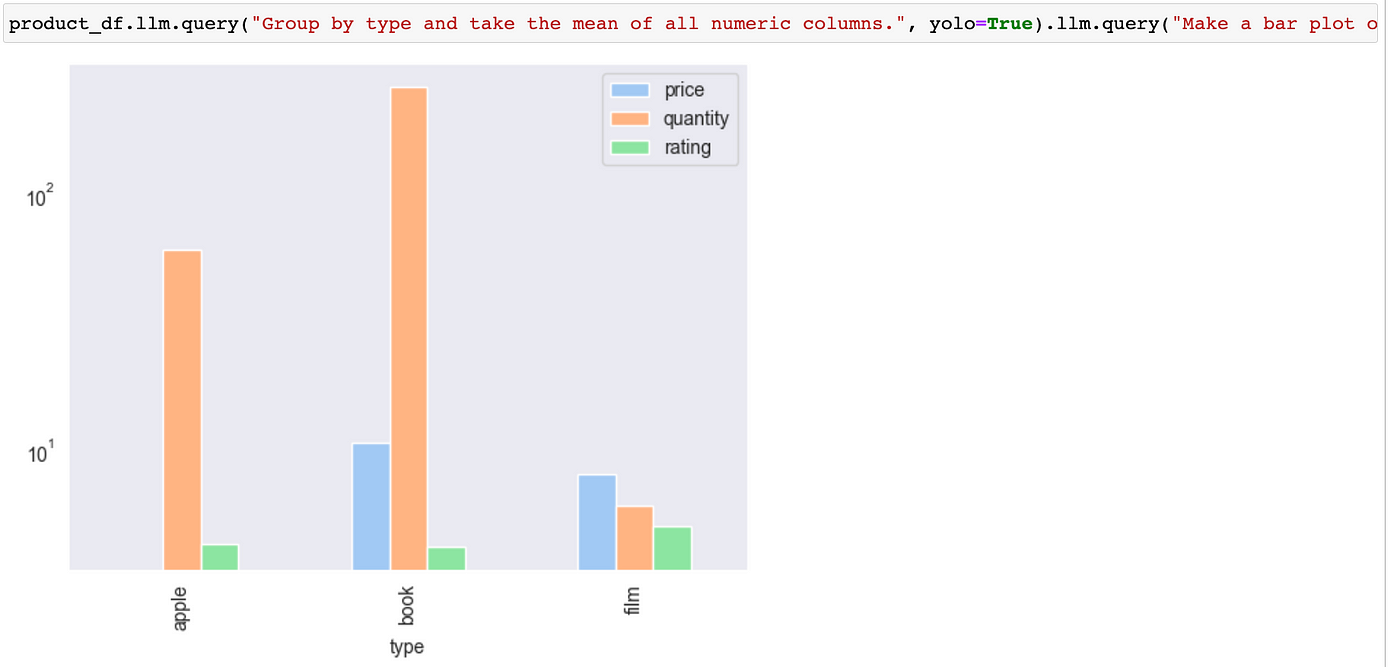
The default chain used by YOLOPandas utilizes the LangChain concept of memory. This allows for “remembering” previous commands, making it possible to ask follow-up questions or ask for the execution of commands that stem from previous interactions.
For example, the query "Make a Seaborn plot of price grouped by type" can be followed with "Can you use a dark theme, and pastel colors?" upon viewing the initial result. But if you are resetting the chain, you can also specify whether to use memory there:
df.reset_chain(use_memory=False)
Conclusion
YOLOPandas queries have proven to be correct 70% — 80% of the time for complex questions; even with a wrong query, the library returns the query code, making it easy to fix.
All these queries cost money, so if you want to have a better idea of how much each query costs, you can use the function run_query_with_cost to compute the cost in $USD.
from yolopandas.utils.query_helpers import run_query_with_cost
run_query_with_cost(product_df, "What item is the least expensive?", yolo=True)
You can check out your usage on OpenAI here.
⚠️ Warning: YOLOPandas will execute arbitrary Python code on the machine it runs on.
