Welcome to Lesson 3 of 12 in our free course series, LLM Twin: Building Your Production-Ready AI Replica. You’ll learn how to use LLMs, vector DVs, and LLMOps best practices to design, train, and deploy a production ready “LLM twin” of yourself. This AI character will write like you, incorporating your style, personality, and voice into an LLM. For a full overview of course objectives and prerequisites, start with Lesson 1.
Lessons
- An End-to-End Framework for Production-Ready LLM Systems by Building Your LLM Twin
- Your Content is Gold: I Turned 3 Years of Blog Posts into an LLM Training
- I Replaced 1000 Lines of Polling Code with 50 Lines of CDC Magic
- SOTA Python Streaming Pipelines for Fine-tuning LLMs and RAG — in Real-Time!
- The 4 Advanced RAG Algorithms You Must Know to Implement
- Turning Raw Data Into Fine-Tuning Datasets
- 8B Parameters, 1 GPU, No Problems: The Ultimate LLM Fine-tuning Pipeline
- The Engineer’s Framework for LLM & RAG Evaluation
- Beyond Proof of Concept: Building RAG Systems That Scale
- The Ultimate Prompt Monitoring Pipeline
- [Bonus] Build a scalable RAG ingestion pipeline using 74.3% less code
- [Bonus] Build Multi-Index Advanced RAG Apps
We have changes everywhere. Linkedin, Medium, Github, Substack can be updated everyday.
To be able to have or Digital Twin up to date we need synchronized data.
What is synchronized data?
Synchronized data is data that is consistent and up-to-date across all systems and platforms it resides on or interacts with. It is the result of making sure that any change made in one dataset is immediately reflected in all other datasets that need to share that information.
Change Data Capture(CDC)’s primary purpose is to identify and capture changes made to database data, such as insertions, updates, and deletions.
It then logs these events and sends them to a message queue, like RabbitMQ. This allows other system parts to react to the data changes in real-time by reading from the queue, ensuring that all application parts are up-to-date.
Today, we will learn how to synchronize a data pipeline and a feature pipeline by using CDC pattern.
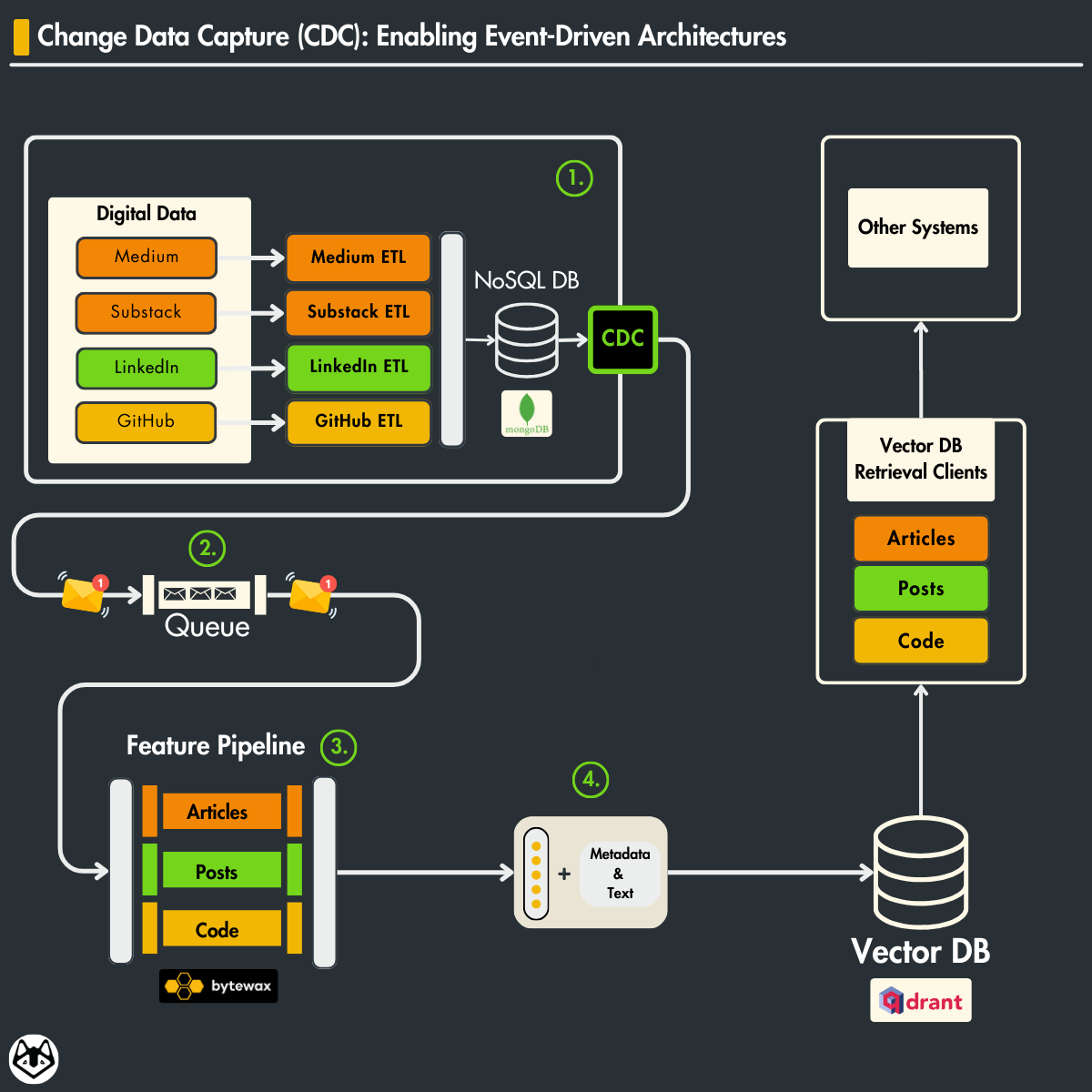
Table of Contents
- CDC pattern — Overview
- CDC pattern —Digital Twin Architecture Use Case
- CDC with MongoDB
- RabbitMQ Message Broker
- Hands-on CDC: Mongo+RabbitMQ
- Running the CDC microservice
1. CDC pattern – Overview
Change Data Capture, commonly known as CDC, is an efficient way to track changes in a database.
The purpose of CDC is to capture insertions, updates, and deletions applied to a database and to make this change data available in a format easily consumable by downstream applications.
Why do we need CDC pattern?
- Real-time Data Syncing: CDC facilitates near-real-time data integration and syncing.
- Efficient Data Pipelines: It allows incremental data loading, which is more efficient than bulk load operations.
- Minimized System Impact: CDC minimizes the impact on the source system by reducing the need for performance-intensive queries.
- Event-Driven Architectures: It enables event-driven architectures by streaming database events.
What problem does CDC solve?
Change Data Capture (CDC) is particularly adept at solving consistency issues in distributed systems.
Consider a common scenario where an application is required to perform a sequence of actions in response to a trigger — such as a REST call or an event receipt.
These actions usually involve making a change to the database and sending a message through a messaging service like Kafka.
However, there’s an inherent risk: if the application encounters a failure or loses its connection to the messaging service after the database transaction but before the message dispatch, the database will reflect the change, but the corresponding message will never be sent. This discrepancy leads to an inconsistent state within the system.
CDC solve this challenge by decoupling the database update from the messaging.
It works by treating the database as a reliable source of events. Any committed change in the database is automatically captured by the CDC mechanism, which then ensures the corresponding message is sent to the messaging queue.
This separation of concerns provided by CDC means that the database update and the message dispatch are no longer directly dependent on the application’s stability or network reliability.
By employing CDC, we can maintain consistency across distributed components of a system, even in the face of application failures or network issues, thereby solving a critical problem in maintaining the integrity of distributed systems.
Another advantage of using change streams is that they read from this Oplog, not directly from the database.
This method significantly reduces the load on the database, avoiding the common pitfall of throttling database performance with frequent direct queries.
By tapping into the Oplog, CDC can efficiently identify and capture change events (such as insertions, updates, or deletions) without adding undue stress on the database itself. You can learn more about it here [2], [3] and [4]
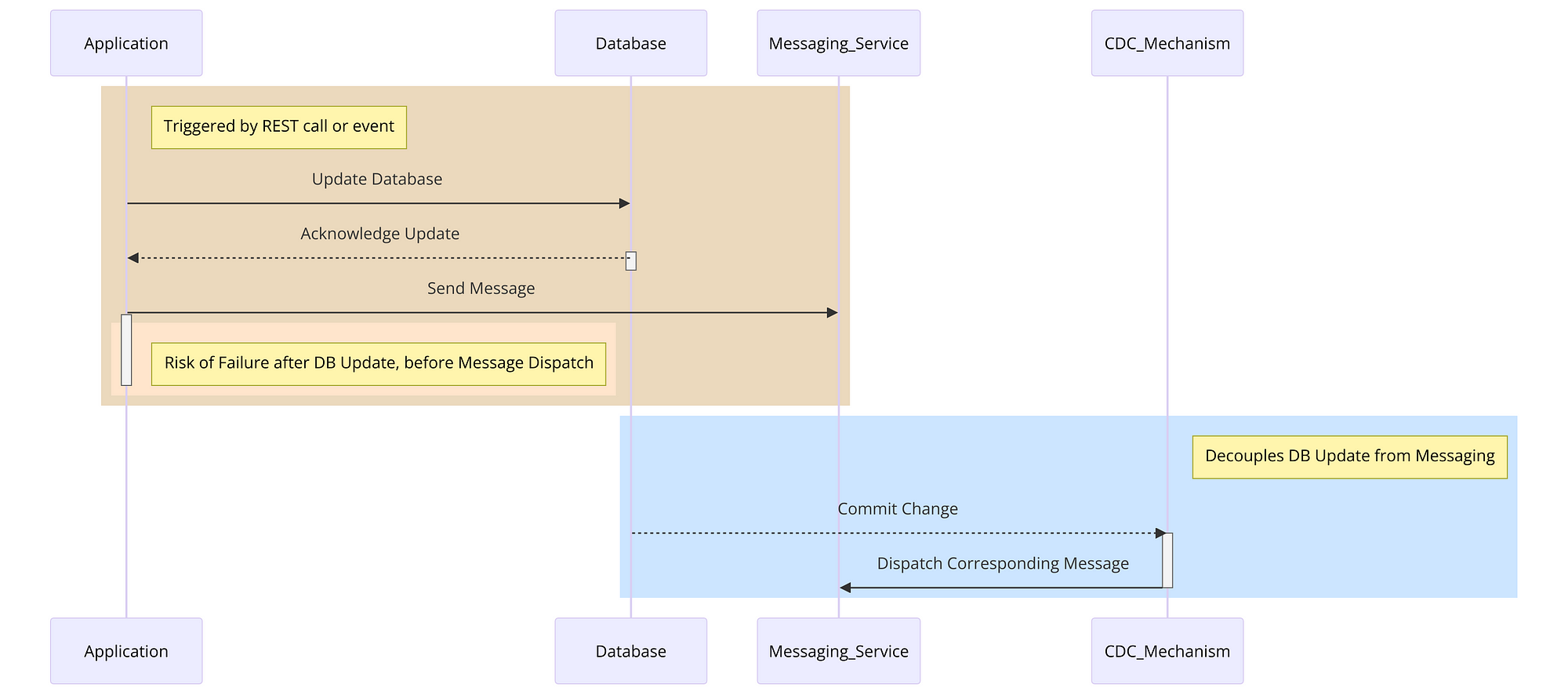
Summary of diagram:
- Application Triggered: The diagram begins with an application that is triggered by a REST call or an event.
- Update Database: The application first updates the database. This is shown as a communication from the ‘Application’ to the ‘Database’.
- Database Acknowledges: The database acknowledges the update back to the application.
- Send Message Attempt: Next, the application tries to send a message through the messaging service (like Kafka). This is where the risk of failure is highlighted — if the application fails after updating the database but before successfully sending the message, it results in inconsistency.
- CDC Mechanism: To resolve this, the CDC mechanism comes into play. It decouples the database update from the messaging.
- Database Commit Triggering CDC: Any committed change in the database is automatically captured by the CDC mechanism.
- CDC Dispatches Message: Finally, the CDC mechanism ensures that the corresponding message is sent to the messaging service. This maintains consistency across the system, even if the application encounters issues after updating the database.
2. CDC pattern — Digital Twin Architecture Use Case
The Digital Twin Architecture is respecting ‘the 3-pipeline architecture’ pattern:
- The feature pipeline
- The training pipeline
- The inference pipeline
But one of the most important component in our architecture is the entry point of the system: the data pipeline
To ensure our feature store stays up-to-date with the data pipeline, we need a mechanism that detects changes at the pipeline’s entry point. This way, we can avoid discrepancies like having 100 entries deleted from our RAW Database while the Vector Database lags behind without these updates.
In the Data Collection Pipeline, data from various digital platforms like Medium, Substack, LinkedIn, and GitHub is extracted, transformed, and loaded (ETL) into a NoSQL database.
Once this raw data is stored, the CDC pattern comes into play.
The CDC pattern comes into action after data storage, meticulously monitoring and capturing any changes — insertions, updates, or deletions within the NoSQL database.
These changes then trigger events that the CDC system captures and pushes onto a queue, managed by RabbitMQ (message broker).
On the other side of the CDC pattern is the Feature Pipeline, where the data continue to flow.
A streaming ingestion pipeline, implemented in Bytewax, takes the queue’s data and processes it in real-time. The processed data includes articles, posts, and code which are then transformed into features, such as actionable insights or inputs for machine learning models.
The processed data is then loaded into a Vector DB (Qdrant), where it’s organized and indexed for efficient retrieval.
The Vector DB Retrieval Clients serve as the access points for querying and extracting these processed data features, now ready to be used in various applications, including training machine learning models or powering search algorithms.
3. CDC with MongoDB
In the world of data-driven applications, timing is everything.
The swifter a system can respond to data changes, the more agile and user-friendly it becomes. Let’s dive into this concept, especially in the context of MongoDB’s change streams, a feature that fundamentally transforms how applications interact with data.
Immediate Response to Data Changes
Consider a scenario where LinkedIn posts are regularly updated in our MongoDB database. Each post might undergo changes — perhaps an edit to the content, a new comment, or an update in user engagement metrics.
In a traditional setup, reflecting these updates into our feature store, specifically Qdrant, could involve significant delays and manual intervention.
However, with MongoDB’s change streams, we implement a observer within our database. This feature is detecting changes in real-time. When a LinkedIn post is edited, MongoDB instantly captures this event and relays it to our data pipeline.
Our data pipeline, upon receiving a notification of the change, springs into action. The updated LinkedIn post is then processed — perhaps analyzed for new keywords, sentiments, or user interactions — and updated in Qdrant.
The sweet spot of MongoDB’s change streams is in their ability to streamline this process. They provide a direct line from the occurrence of a change in MongoDB to its reflection in Qdrant, ensuring our feature store is always in sync with the latest data.
This capability is crucial for maintaining an up-to-date and accurate data landscape, which in turn, powers more relevant and dynamic analytics for the LLM twin.
Before change streams, applications that needed to know about the addition of new data in real-time had to continuously poll data or rely on other update mechanisms.
One common, if complex, technique for monitoring changes was tailing MongoDB’s Operation Log (Oplog). The Oplog is part of the replication system of MongoDB and as such already tracks modifications to the database but is not easy to use for business logic.
Note that you cannot open a change stream against a collection in a standalone MongoDB server because the feature relies on the Oplog which is only used on replica sets.
When registering a change stream you need to specify the collection and what types of changes you want to listen to. You can do this by using the $match and a few other aggregation pipeline stages which limit the amount of data you will receive.
4. RabbitMQ Message Broker
RabbitMQ is a reliable and mature messaging and streaming broker, which is easy to deploy on cloud environments, on-premises, and on your local machine. It is currently used by millions worldwide.
Why do we need a message broker?
- Reliability: RabbitMQ guarantees reliable message delivery, ensuring that change events are conveyed to the Feature Pipeline, even in the face of temporary outages.
- Decoupling: This enables loose coupling between services, promoting autonomous operation and mitigating the propagation of failures across the system.
- Load Management: It evenly distributes the data load across multiple consumers, enhancing system efficiency.
- Asynchronous Processing: The system benefits from asynchronous processing, with RabbitMQ queuing change events for processing without delay.
- Scalability: RabbitMQ’s scalability features accommodate growing data volumes by facilitating easy addition of consumers and horizontal scaling.
- Data Integrity: It ensures messages are processed in the order they’re received, which is critical for data integrity.
- Recovery Mechanisms: RabbitMQ offers message acknowledgment and redelivery features, vital for recovery from failures without data loss.
5. Hands-on CDC: Mongo+RabbitMQ
We are building the RabbitMQConnection class, a singleton structure, for establishing and managing connections to the RabbitMQ server. This class is robustly designed to handle connection parameters like username, password, queue name, host, port, and virtual_host, which can be customized or defaulted from settings.
Utilizing the pika Python library, RabbitMQConnection provides methods to connect, check connection status, retrieve channels, and close the connection. This improved approach encapsulates connection management within a singleton instance, ensuring efficient handling of RabbitMQ connections throughout the system lifecycle, from initialization to closure.
from typing import Self import pika from config import settings from core.logger_utils import get_logger logger = get_logger(__file__) class RabbitMQConnection: """Singleton class to manage RabbitMQ connection.""" _instance = None def __new__(cls, *args, **kwargs) -> Self: if not cls._instance: cls._instance = super().__new__(cls, *args, **kwargs) return cls._instance def __init__( self, host: str | None = None, port: int | None = None, username: str | None = None, password: str | None = None, virtual_host: str = "/", fail_silently: bool = False, **kwargs, ) -> None: self.host = host or settings.RABBITMQ_HOST self.port = port or settings.RABBITMQ_PORT self.username = username or settings.RABBITMQ_DEFAULT_USERNAME self.password = password or settings.RABBITMQ_DEFAULT_PASSWORD self.virtual_host = virtual_host self.fail_silently = fail_silently self._connection = None def __enter__(self): self.connect() return self def __exit__(self, exc_type, exc_val, exc_tb): self.close() def connect(self): try: credentials = pika.PlainCredentials(self.username, self.password) self._connection = pika.BlockingConnection( pika.ConnectionParameters( host=self.host, port=self.port, virtual_host=self.virtual_host, credentials=credentials, ) ) except pika.exceptions.AMQPConnectionError as e: logger.exception("Failed to connect to RabbitMQ:") if not self.fail_silently: raise e def is_connected(self) -> bool: return self._connection is not None and self._connection.is_open def get_channel(self): if self.is_connected(): return self._connection.channel() def close(self): if self.is_connected(): self._connection.close() self._connection = None print("Closed RabbitMQ connection”) Publishing to RabbitMQ: The publish_to_rabbitmq function is where the magic happens. It connects to RabbitMQ , ensures that the message delivery is confirmed for reliability, and then publishes the data.
The data variable, which is expected to be a JSON string, represents the changes captured by MongoDB’s CDC mechanism.
def publish_to_rabbitmq(queue_name: str, data: str): """Publish data to a RabbitMQ queue.""" try: # Create an instance of RabbitMQConnection rabbitmq_conn = RabbitMQConnection() # Establish connection with rabbitmq_conn: channel = rabbitmq_conn.get_channel() # Ensure the queue exists channel.queue_declare(queue=queue_name, durable=True) # Delivery confirmation channel.confirm_delivery() # Send data to the queue channel.basic_publish( exchange="", routing_key=queue_name, body=data, properties=pika.BasicProperties( delivery_mode=2, # make message persistent ), ) print("Sent data to RabbitMQ:", data) except pika.exceptions.UnroutableError: print("Message could not be routed") except Exception as e: print(f"Error publishing to RabbitMQ: {e}")For example, you can call it as:
publish_to_rabbitmq("test_queue", "Hello, World!") → Full RabbitMQ code at core/mq.py.
CDC Pattern in MongoDB
Setting Up MongoDB Connection: The script connects to a MongoDB database using the MongoDatabaseConnector class. We instantiate the connection instance, which we will use to communicate with MongoDB.
from pymongo import MongoClient from pymongo.errors import ConnectionFailure from core.config import settings from core.logger_utils import get_logger logger = get_logger(__file__) class MongoDatabaseConnector: """Singleton class to connect to MongoDB database.""" _instance: MongoClient | None = None def __new__(cls, *args, **kwargs): if cls._instance is None: try: cls._instance = MongoClient(settings.MONGO_DATABASE_HOST) logger.info( f"Connection to database with uri: {settings.MONGO_DATABASE_HOST} successful" ) except ConnectionFailure: logger.error(f"Couldn't connect to the database.") raise return cls._instance def get_database(self): assert self._instance, "Database connection not initialized" return self._instance[settings.MONGO_DATABASE_NAME] def close(self): if self._instance: self._instance.close() logger.info("Connected to database has been closed.") connection = MongoDatabaseConnector() Monitoring Changes with watch: The core of the CDC pattern in MongoDB is realized through the watch method. Here, the script sets up a change stream to monitor for specific types of changes in the database.
In this case, it’s configured to listen for insert operations in any collection within the scrabble database.
changes = db.watch([{'$match': {'operationType': {'$in': ['insert']}}}])/code>Processing Each Change: As changes occur in the database, the script iterates through each change event.
The script extracts essential metadata for each event, like the data type (collection name) and the entry ID. It also reformats the document by removing the MongoDB-specific _id and appending the data type and entry ID. This formatting makes the data compatible with the feature pipeline.
for change in changes:
data_type = change["ns"]["coll"]
entry_id = str(change["fullDocument"]["_id"]) # Convert ObjectId to string
change["fullDocument"].pop("_id")
change["fullDocument"]["type"] = data_type
change["fullDocument"]["entry_id"] = entry_id
if data_type not in ["articles", "posts", "repositories"]:
logging.info(f"Unsupported data type: '{data_type}'")
continue Conversion to JSON and Publishing to RabbitMQ: The transformed document is converted to a JSON string (serialized) and sent to the RabbitMQ queue:
data = json.dumps(change["fullDocument"], default=json_util.default) logger.info( f"Change detected and serialized for a data sample of type {data_type}." ) publish_to_rabbitmq(queue_name=settings.RABBITMQ_QUEUE_NAME, data=data) logger.info(f"Data of type '{data_type}' published to RabbitMQ.") → Full code available at data_cdc/cdc.py
The full system docker-compose
This docker-compose configuration outlines the setup for a system comprising a MongoDB database and a RabbitMQ message broker. The setup is designed to facilitate a development or testing environment using Docker containers.
Let’s walk through the critical components of this configuration:
This docker-compose configuration outlines the setup for a system comprising a MongoDB database and a RabbitMQ message broker. The setup is designed to facilitate a development or testing environment using Docker containers.
Let’s walk through the critical components of this configuration:
MongoDB Service Setup
- Image: Each MongoDB instance uses the
mongo:5image, which is the official V5 MongoDB Docker image - Container Names: Individually named (
mongo1,mongo2,mongo3) for easy identification. - Commands: Each instance is started with specific commands:
--replSet "my-replica-set"to set up a replica set named ‘my-replica-set’.--bind_ip_allto bind MongoDB to all IP addresses.--port 3000X(where X is 1, 2, or 3) to define distinct ports for each instance.
Using three replicas in a MongoDB replica set is a common practice primarily for achieving high availability, data redundancy, and fault tolerance. Here’s why having three replicas is beneficial:
- High Availability: In a replica set, one node is the primary node that handles all write operations, while the others are secondary nodes that replicate the data from the primary. If the primary node fails, one of the secondary nodes is automatically elected as the new primary. With three nodes, you ensure that there’s always a secondary node available to take over if the primary fails, minimizing downtime.
- Data Redundancy: Multiple copies of the data are maintained across different nodes. This redundancy safeguards against data loss in case of a hardware failure or corruption on one of the nodes.
- Volumes: Maps to the mongo-replica-1-data, mongo-replica-2-data, and mongo-replica-3-data volumes managed by Docker. This ensures data persistence across container restarts.
- Ports: Exposes each MongoDB instance on a unique port on the host machine (30001, 30002, 30003).
- Healthcheck (only for
mongo1): Regularly checks the health of the first MongoDB instance, ensuring the replica set is correctly initiated and operational.
RabbitMQ Service Setup
- Image and Container: Uses RabbitMQ 3 with management plugin based on Alpine Linux.
- Ports: Exposes RabbitMQ on port
5673for message queue communication and15673for management console access. - Volumes: Maps local directories for RabbitMQ data and log storage, ensuring persistence and easy access to logs.
- Restart Policy: Like MongoDB, it’s configured to always restart if it stops.
services: mongo1: image: mongo:5 container_name: llm-twin-mongo1 command: ["--replSet", "my-replica-set", "--bind_ip_all", "--port", "30001"] volumes: - mongo-replica-1-data:/data/db ports: - "30001:30001" healthcheck: test: test $$(echo "rs.initiate({_id:'my-replica-set',members:[{_id:0,host:\"mongo1:30001\"},{_id:1,host:\"mongo2:30002\"},{_id:2,host:\"mongo3:30003\"}]}).ok || rs.status().ok" | mongo --port 30001 --quiet) -eq 1 interval: 10s start_period: 30s restart: always mongo2: image: mongo:5 container_name: llm-twin-mongo2 command: ["--replSet", "my-replica-set", "--bind_ip_all", "--port", "30002"] volumes: - mongo-replica-2-data:/data/db ports: - "30002:30002" restart: always mongo3: ... # Another read-only replica similar to mongo2 mq: image: rabbitmq:3-management-alpine container_name: llm-twin-mq ports: - "5673:5672" - "15673:15672" volumes: - ./rabbitmq/data/:/var/lib/rabbitmq/ - ./rabbitmq/log/:/var/log/rabbitmq restart: always qdrant: ... data-crawlers: ... data_cdc: image: "llm-twin-data-cdc" container_name: llm-twin-data-cdc build: context: . dockerfile: .docker/Dockerfile.data_cdc env_file: - .env depends_on: - mongo1 - mongo2 - mongo3 - mq feature_pipeline: ... volumes: mongo-replica-1-data: mongo-replica-2-data: mongo-replica-3-data: qdrant-data: → Full Docker compose file available at docker-compose.yml
6. Running the CDC microservice
The CDC microservice will run automatically when starting the Docker containers defined in the Docker compose file from above.
To build and run the Docker images, run the following:
make local-startThis will start by default the CDC microservice, which will listen to changes done to the MongoDB and send them to the RabbitMQ queue.
For macOS/Linux users, for the multi-replica set-up to work correctly, you have to add the following lines of code to your /etc/hosts file:
127.0.0.1 mongo1 127.0.0.1 mongo2 127.0.0.1 mongo3→ More details in our INSTALL_AND_USAGE docs.
To test it out, trigger the crawlers to send some data to MongoDB as follows:
make local-test-medium # or make local-test-githubThis will crawl a Medium (or GitHub) article, which will be saved to MongoDB, trigger the CDC service, and send the event to the RabbitMQ queue.
You can check the logs of the Docker containers by running:
docker logs llm-twin-data-crawlers # Crawler service docker logs llm-twin-data-cdc # CDC service docker logs llm-twin-mq # RabbitMQIf everything runs as expected, you should see in the logs of the CDC service something similar to the image below:

Find step-by-step instructions on installing and running the entire course in our INSTALL_AND_USAGE document from the repository.
Conclusion
This lesson presented the Change Data Capture (CDC) pattern, a powerful strategy for synchronizing data across multiple databases crucial for maintaining real-time data consistency in event-driven systems.
We showed how to implement the CDC pattern using a MongoDB data warehouse and a RabbitMQ queue.
As this lesson is part of the LLM Twin course, we presented how to integrate the CDC microservice into a larger system that contains data and feature engineer pipelines through Docker containers.
In Lesson 4, we will explore the feature pipeline, which will be implemented as a streaming pipeline using Bytewax. It will consume real-time events from the RabbitMQ queue and process them to fine-tune LLMs and RAG, ultimately loading the processed data into a vector DB.
🔗 Check out the code on GitHub [1] and support us with a ⭐️
References
[1] Your LLM Twin Course — GitHub Repository (2024), Decoding ML GitHub Organization
[2] Change Streams, MongoDB Documentation
[3]Shantanu Bansal, Demystifying MongoDB Oplog: A Comprehensive Guide with Oplog Entry Examples, 2023, Medium
[4] How Do Change Streams Work in MongoDB?, MongoDB Documentation

