LLM Monitoring & Maintenance in Production Applications

Generative AI has become a transformative force, revolutionizing how businesses engage with users through chatbots, content creation, and personalized recommendations. Yet, behind its promise of efficiency and creativity lies a critical challenge: ensuring applications based on GenAI models stay reliable and effective over time.
Like a high-performance car that needs regular servicing, GenAI models, particularly large language models (LLMs), require consistent updates to stay relevant. As user expectations evolve and data becomes outdated, neglecting maintenance can lead to performance degradation, irrelevant outputs, or reputational risks.
LLMs are uniquely vulnerable to model drift, where changing environments, data, or user behavior diminish their accuracy. Without proactive monitoring and updates, businesses risk outputs that are biased, incoherent, or ethically problematic.
This brings us to a crucial question: How can organizations maintain GenAI models and LLM-powered applications to ensure sustained performance and trust? Let’s explore the key challenges and how teams are using new LLM monitoring tools to track, measure, and optimize their applications over time in production.

Key Challenges Monitoring & Maintaining LLM Applications
LLM monitoring helps teams stay ahead of challenges that can arise when their applications call LLMs in real time on behalf of end users.
Lack of Rigorous Testing
Applications based on LLMs need ongoing validation to ensure accurate and contextually relevant outputs. Without robust testing pipelines, errors can go undetected, leading to hallucinations or inappropriate content.
For instance, a customer service chatbot might recommend non-existent products or generate outdated information, frustrating users and damaging trust.
Analogy: Maintaining an LLM application is like inspecting a dam for cracks. Small issues left unchecked can grow into catastrophic failures.
Evolving Data and Context
Data and user preferences evolve rapidly. LLM applications built on past data may fail to capture new trends, making their responses less relevant.
Example: A chatbot built in 2022 may lack the vocabulary to discuss emerging technologies or cultural events in 2024.
Analogy: An LLM is like a library. If no new books are added, its knowledge becomes outdated, reducing its usefulness and trustworthiness.
Lack of Continuous Human Oversight
While GenAI models can automate tasks, they still need human oversight to avoid unintended outcomes, such as reinforcing biases or producing unethical content.
Without monitoring, biases can amplify over time, leading to outputs that are discriminatory or misaligned with organizational values.
Analogy: Think of an LLM like a high-tech autopilot system on a plane. It can handle most of the flight, but a pilot is still needed to monitor its decisions, intervene in emergencies, and ensure a safe journey.
Declining Relevance
Irrelevant or confusing outputs discourage users. A virtual assistant that provides off-topic or nonsensical responses quickly loses credibility, reducing adoption rates and engagement.
Example: A customer service bot that struggles with common queries erodes confidence in the brand’s ability to support its customers.
Analogy: Imagine a customer service agent who constantly gives off-topic answers, users would stop relying on them.
Why Continuous Evaluation and LLM Monitoring Matter
Occasionally spot checking LLM traces and user feedback scores from production can provide some reassurance, but it’s difficult to capture the full picture of how your application is performing and changing over time without continuous logging and analysis, which can be automated at scale. With an automated system in place, teams mitigate the risk of problems magnifying slowly over time.
LLM Monitoring as a Defense
Monitoring allows businesses to detect anomalies, prevent errors, and adapt to evolving user needs. Proactive detection of issues like drift or bias minimizes risks and ensures consistent performance.
Analogy: Monitoring an LLM application is like tuning a musical instrument. Without regular tuning, even the best instrument will go out of harmony over time.

Avoiding Neglect
Failing to evaluate GenAI models leads to inefficiencies, compliance risks, and user dissatisfaction. Small issues, if ignored, can escalate into larger problems.
Analogy: Skipping maintenance on an airplane might not cause immediate issues, but over time, small oversights can lead to significant failures.
The Solution: LLM Monitoring & Evaluation Tools
Given the variety of LLM monitoring and maintenance challenges discussed above, many teams building with LLMs start out by spot checking LLM responses, manually tweaking their applications’ prompts and pipelines, and hoping for the best. But at scale in production, this quickly becomes impractical and difficult to trust. A new category of open-source tools is helping teams automate and organize tracking, dataset creation, scoring and evaluation, prompt iteration, and production monitoring for these types of large and complex applications.
That’s why our team at Comet created Opik, an open-source LLM evaluation framework that offers a streamlined solution to this challenge, automating the evaluation process and enabling teams to iterate faster and with greater precision. By focusing on two core pillars, datasets and experiments, Opik transforms the way LLM applications are tested, monitored, and improved.
The Role of Datasets in LLM Evaluation
A dataset is more than a simple collection of inputs and outputs; it is the foundation for assessing how effectively your LLM application performs under diverse scenarios. Each dataset is composed of individual samples, known as Dataset Items, which include the input (what the model is given), the expected output (what the model should ideally produce), and metadata providing context for evaluation.
Building these datasets is a critical step, and teams often dedicate considerable effort to curating them. This can be done in several ways. A common starting point is manual curation, where developers and subject matter experts identify key examples based on their understanding of the application. This ensures the dataset reflects realistic and meaningful use cases.
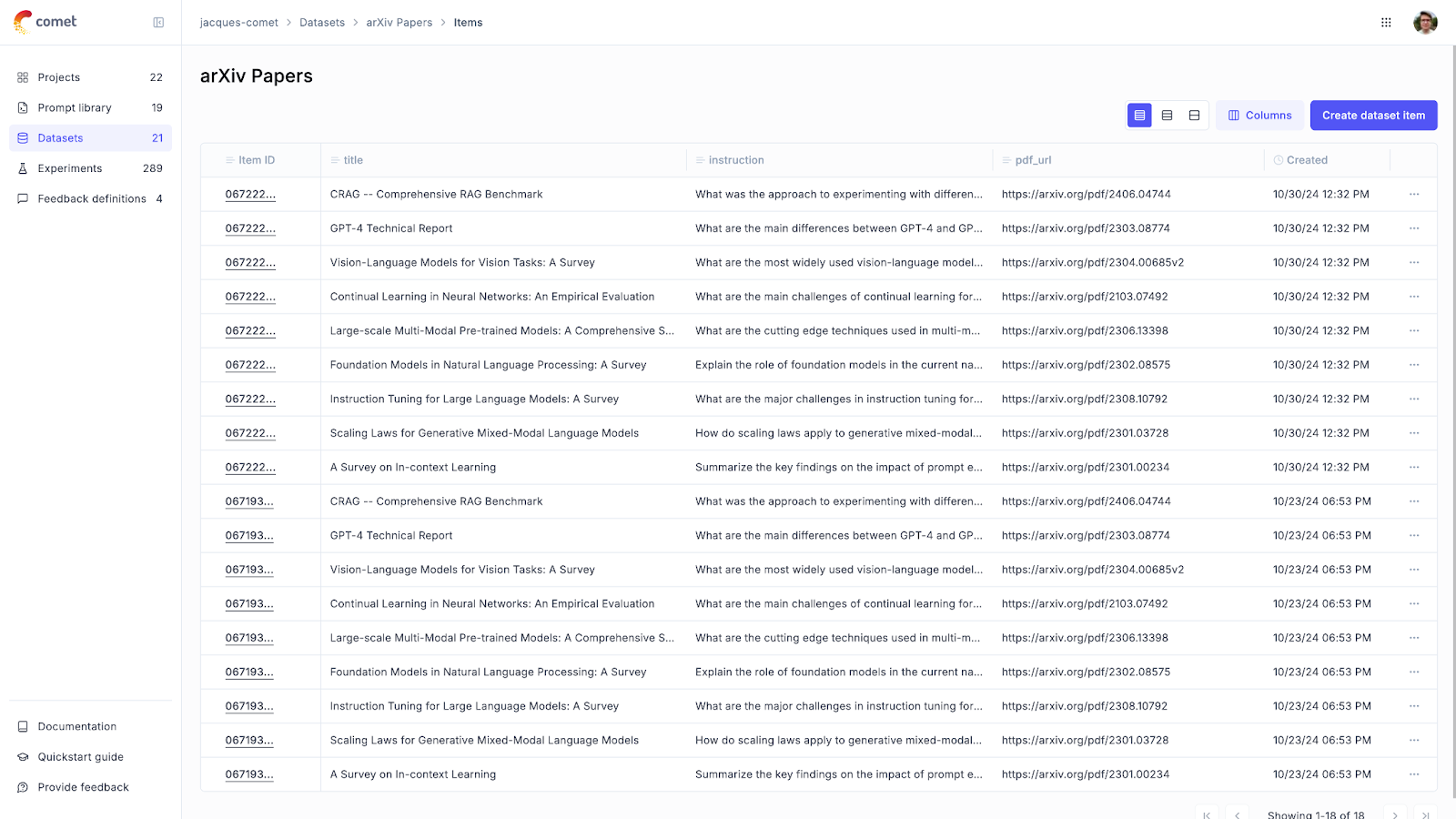
However, when data is scarce, synthetic data generation tools can be invaluable. Teams can use these tools to produce a variety of examples that challenge the model’s limitations. For instance, the LangChain cookbook shows how to generate synthetic datasets tailored to specific use cases.
For applications already in production, real-world data offers an additional source for enriching datasets. By incorporating production traces, teams can evaluate their models on actual user interactions, ensuring that improvements align with real-world behavior. Opik’s interface simplifies this process, allowing teams to quickly add traces to their datasets with just a few clicks.
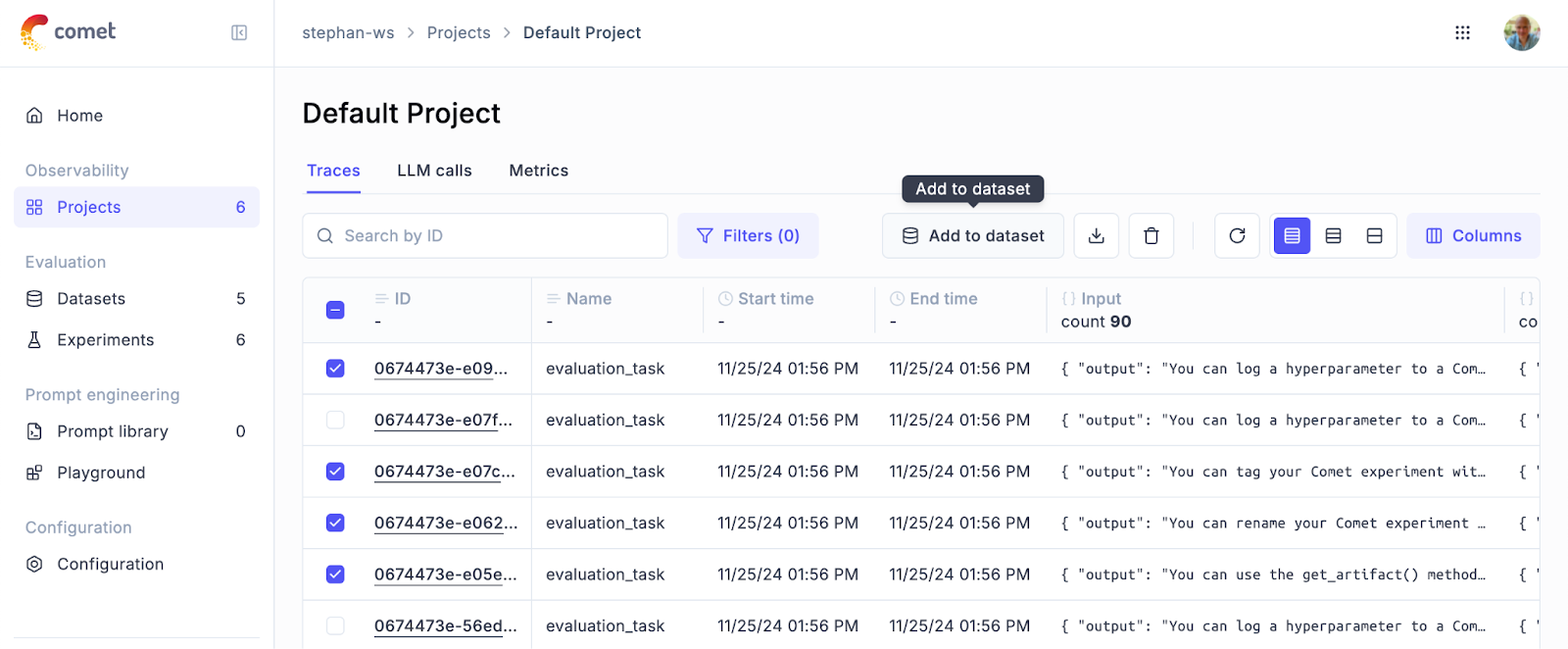
Experiments: Testing and Iterating with Confidence
Once the dataset is prepared, the next step is running experiments. In Opik, an experiment is a single evaluation run where each dataset item is processed, the model’s output is generated, and the results are scored. This structured approach provides a clear framework for comparing different iterations of your LLM application.
Experiments in Opik are built around two key components: configuration and results. The configuration defines the parameters of the evaluation, such as the model used, the system RAG, the prompt template, and any relevant hyperparameters. This metadata is essential for tracking changes between experiments, allowing teams to identify what modifications improve performance and which do not.
The results, or Experiment Items, contain a detailed breakdown of each dataset sample. For every input, Opik stores the expected output, the actual output produced by the model, and the score assigned during evaluation. Additionally, each Experiment Item is traceable, providing a window into why a specific score was given. This level of transparency is invaluable for debugging and refining model performance.
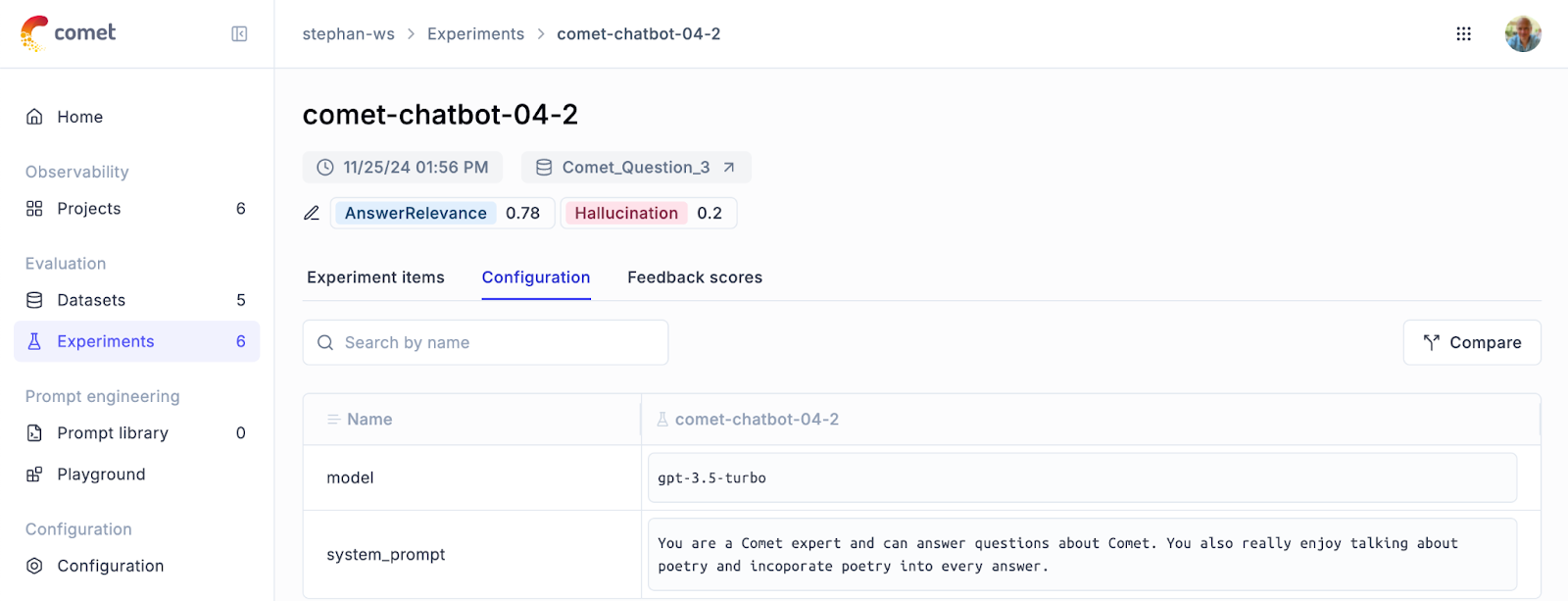
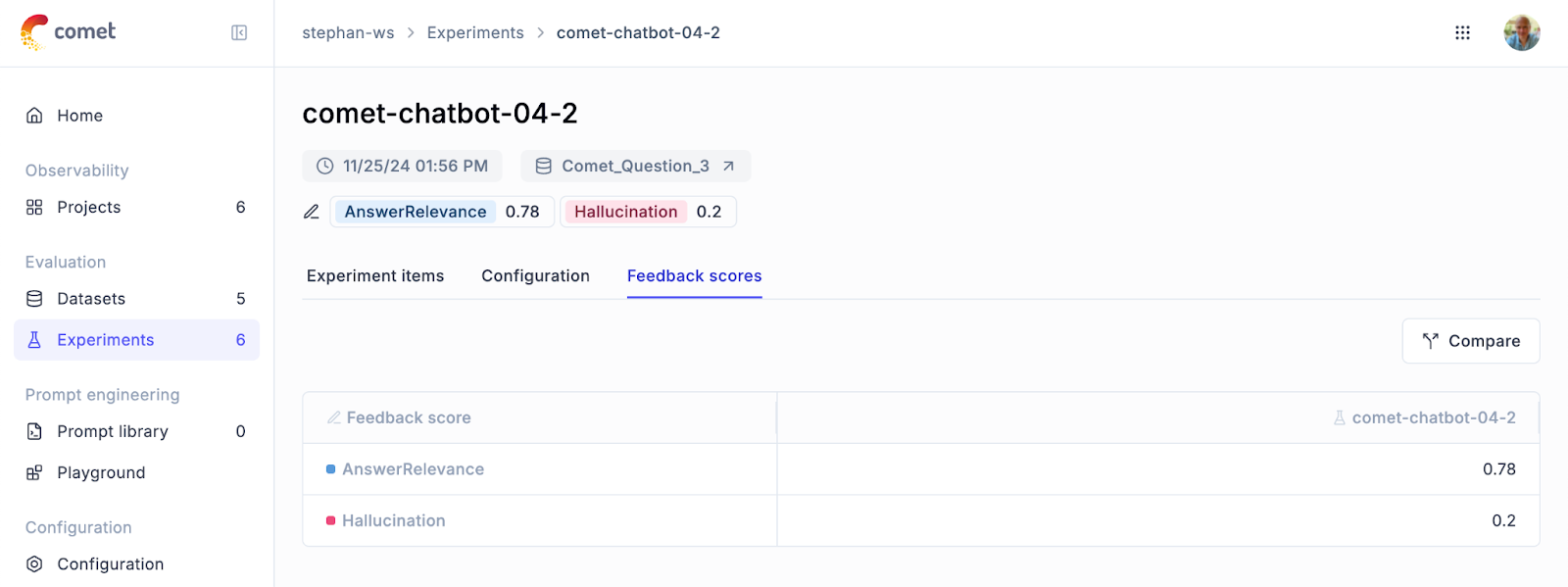
How Opik Simplifies LLM Evaluation
Running an evaluation in Opik is straightforward. You select your dataset, define the evaluation task by mapping inputs to desired outputs, and choose the metrics you wish to measure, such as accuracy, coherence, or relevance. Once these parameters are set, the evaluation is launched, and Opik handles the rest.
The platform processes the dataset, generates outputs for each sample, and calculates scores based on the selected LLM evaluation metrics. This automated process not only saves time but also ensures consistency across evaluations.
Empowering Teams with Better Insights
By automating and standardizing the evaluation process, Opik allows teams to focus on what truly matters: building better LLM applications. With its robust dataset management, detailed experiment tracking, and transparent scoring system, Opik eliminates the guesswork from evaluation and provides actionable insights at every step.
For organizations striving to push the boundaries of GenAI, Opik offers the tools needed to iterate faster, improve accuracy, and build models that inspire trust and deliver consistent value.
Monitoring Your LLM Applications in Production with Opik
Opik has been meticulously designed to handle high volumes of traces, making it the ideal solution for monitoring your production LLM applications with its robust dashboard and comprehensive tracking capabilities. Opik offers a detailed overview of your application’s performance in production, enabling you to maintain and improve the quality of your LLM-driven processes.
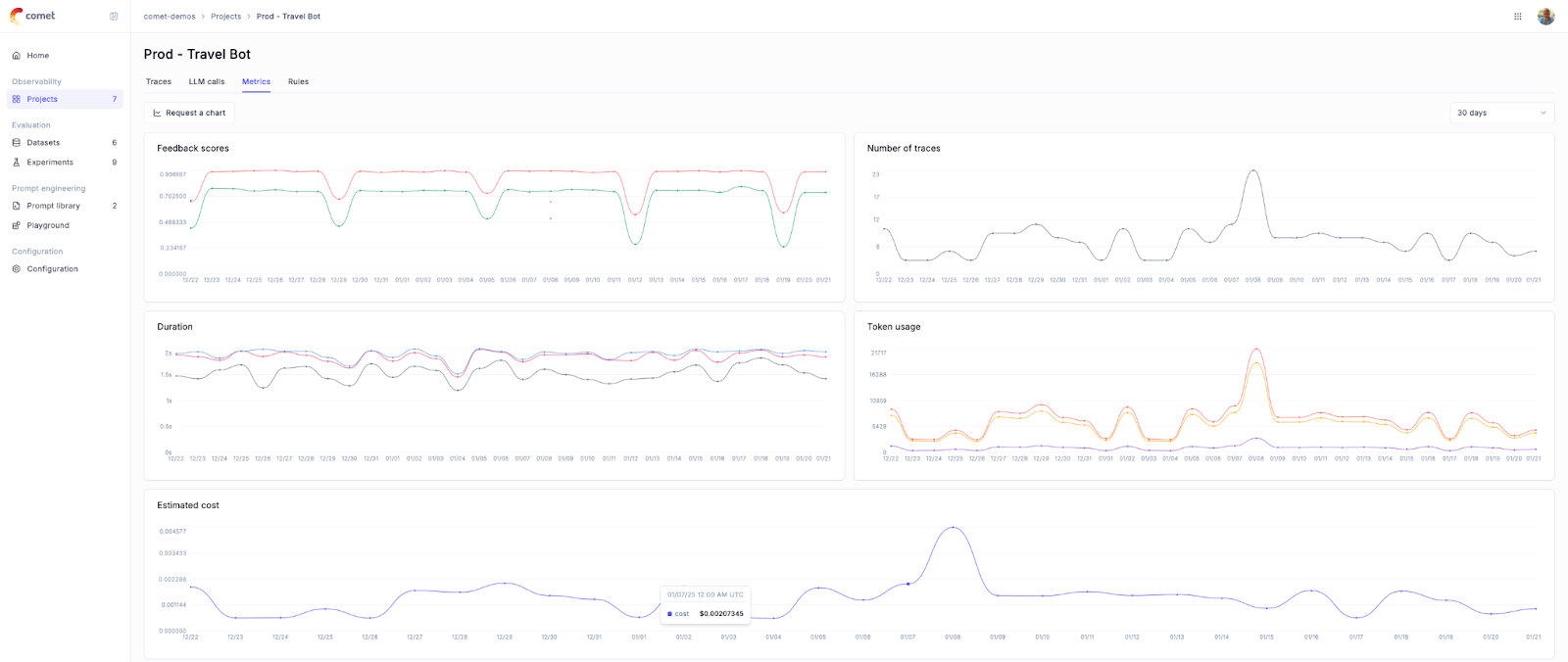
Opik LLM Monitoring Dashboard
The Opik dashboard provides real-time insights into your application’s performance by displaying key metrics such as feedback scores, trace counts, and token usage. These metrics can be reviewed over various timeframes, offering both daily and hourly granular views. This makes it easy to track and analyze trends in your application’s performance over time.
Some Key Metrics and Their Impact on Production Monitoring
- Feedback Scores aggregate user ratings or system-generated quality scores for LLM responses. Decreasing feedback scores can indicate a decline in response relevance, accuracy, or user satisfaction, enabling early intervention.
- Trace Counts to know the number of user interactions or requests processed by the LLM over a given period. Sudden spikes or drops in trace counts can highlight traffic anomalies, system bottlenecks, or integration failures.
- Token Usage to know the volume of tokens consumed per request or session. Excessive token usage may signal inefficiencies in prompt design, redundant model outputs, or unoptimized application logic.
- Response Time Metrics to know the time taken for the LLM to process a request and return a response. Latency spikes could indicate system slowdowns, model overloading, or API integration issues.
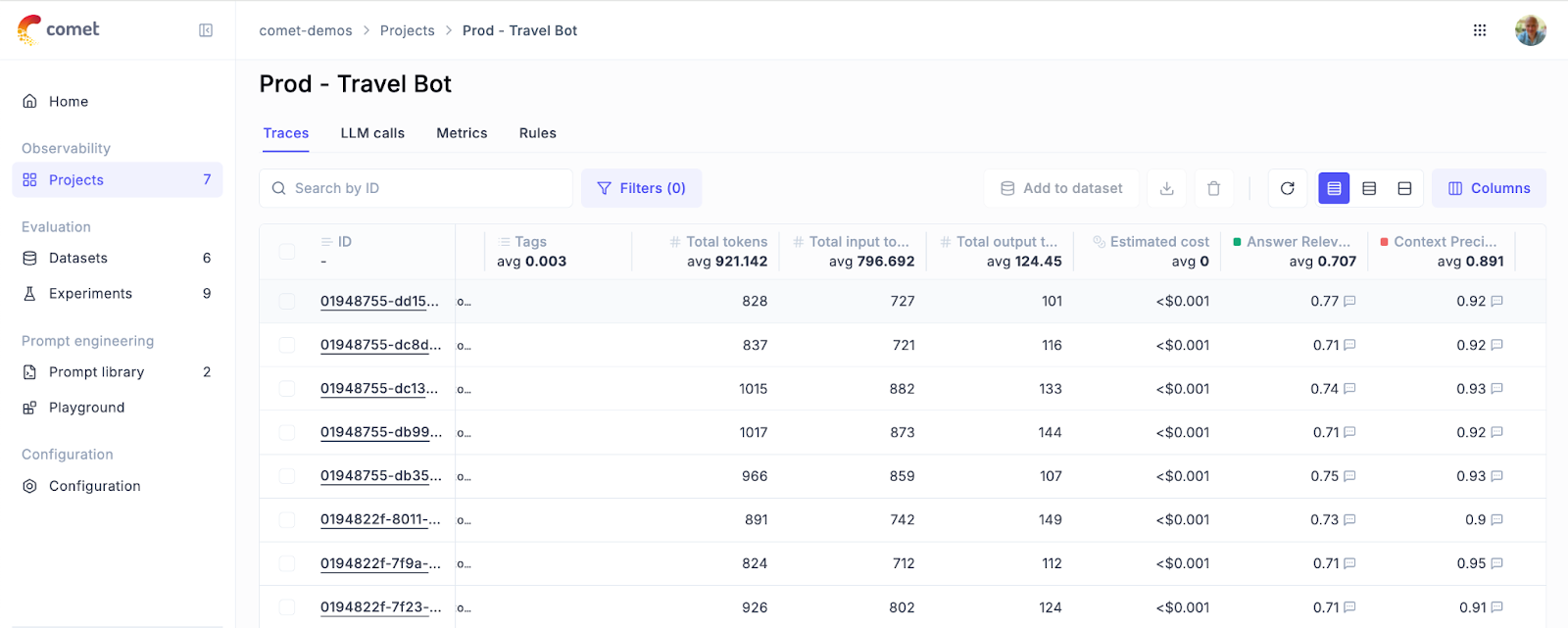
In addition to monitoring trends, Opik’s traces table displays average feedback scores for all traces in your project, offering a detailed snapshot of your LLM’s effectiveness and user satisfaction in production.
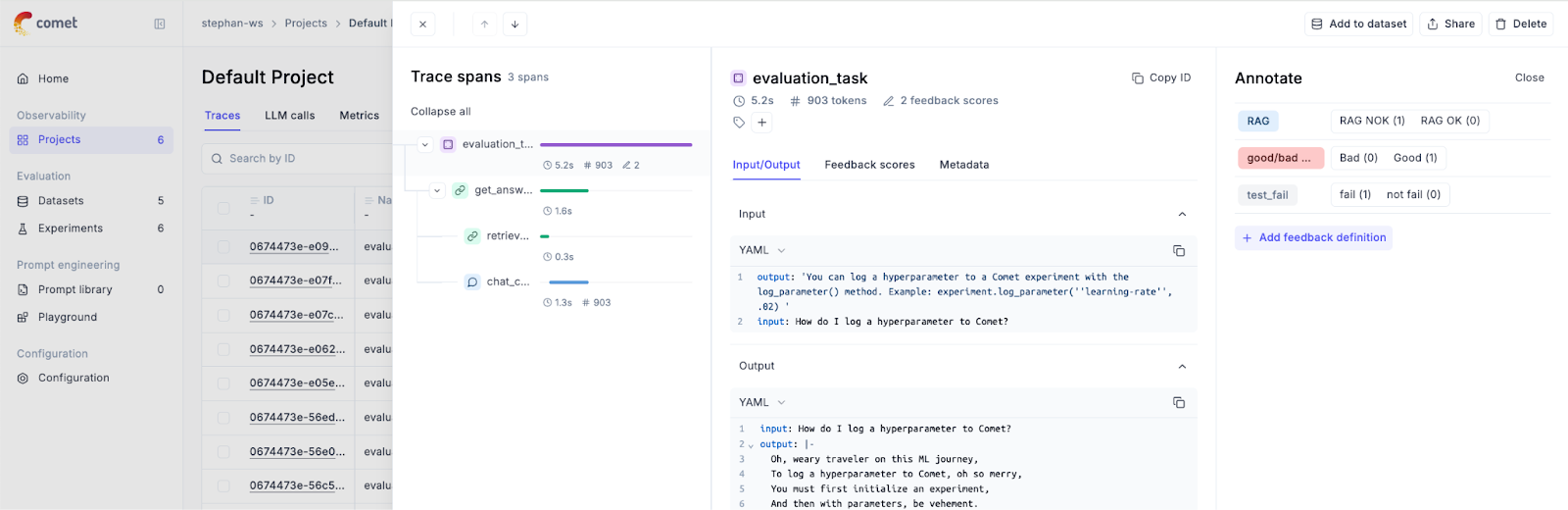
Logging Feedback Scores
To effectively monitor the performance of your LLM application, you can log feedback scores using both the Python SDK and the user interface (UI). These scores are essential for evaluating how well your LLM is performing based on user feedback.
Tracking feedback scores over time enables you to identify when specific use cases or user groups experience reduced satisfaction.
By correlating feedback scores with trace metadata, such as query type or input size, you can pinpoint areas where your LLM’s performance might need optimization.
Regularly monitoring feedback allows you to iterate on prompts, fine-tune your model, or adjust system integrations to better align with user needs.
By seamlessly integrating feedback into your monitoring workflow, Opik helps ensure your LLM application remains responsive and aligned with user expectations. The actionable insights provided by Opik enable continuous improvement, ensuring your production systems deliver consistent, high-quality results.
Future-Proofing Your GenAI Applications with Opik
GenAI has the potential to transform industries, but its success depends on effective LLM monitoring and maintenance. Businesses must tackle challenges like model drift, evolving data, and user expectations to ensure consistent performance and trust.
Opik offers a solution that simplifies the complex task of GenAI maintenance. By integrating advanced monitoring, drift detection, and in production real-time feedback, Opik enables businesses to future-proof their AI systems.
Opik is genuinely free to use, with its full LLM evaluation featureset available in the open-source version on GitHub. You can also sign up free to try the hosted version and log up to 10,000 traces per month at no charge, with no credit card required at signup.
Related Articles


