LLM Hallucination Detection in App Development

Even ChatGPT knows it’s not always right. When prompted, “Are large language models (LLMs) always accurate?” ChatGPT says no and confirms, “While they are powerful tools capable of generating fluent and contextually appropriate text based on their training, there are several reasons why they may produce inaccurate or unreliable information.”
One of those reasons: Hallucinations.
LLM hallucinations occur when the response to a user prompt is presented confidently by the model as a true statement, but is in fact inaccurate or completely fabricated nonsense. These coherent but incorrect outputs call the reliability and trustworthiness of LLM tools into question, and are a known issue you will need to mitigate if you are developing an app with an LLM integration.
For reference, if we look at GPT-4 as an example, the rate of LLM hallucinations varies anywhere from 1.8% for general usage all the way to 28.6% for specific applications. And there can be real consequences for businesses who rely on LLM agents to serve their customers. Take the case of Air Canada last year—the company was taken to court, and required to pay legal expenses plus a settlement due to a hallucination its LLM-driven chatbot made while answering a customer’s question about refund policies.
To help you address the challenges hallucinations cause during the LLM app development process and reduce your chances of becoming the person with the revenue-losing chatbot, this article will explore:
- What LLM hallucinations are and what causes them
- Different types of LLM hallucinations plus examples
- Challenges specific to developers building with LLMs
- How to automate LLM evaluation and prevent hallucinations
What is LLM Hallucination?
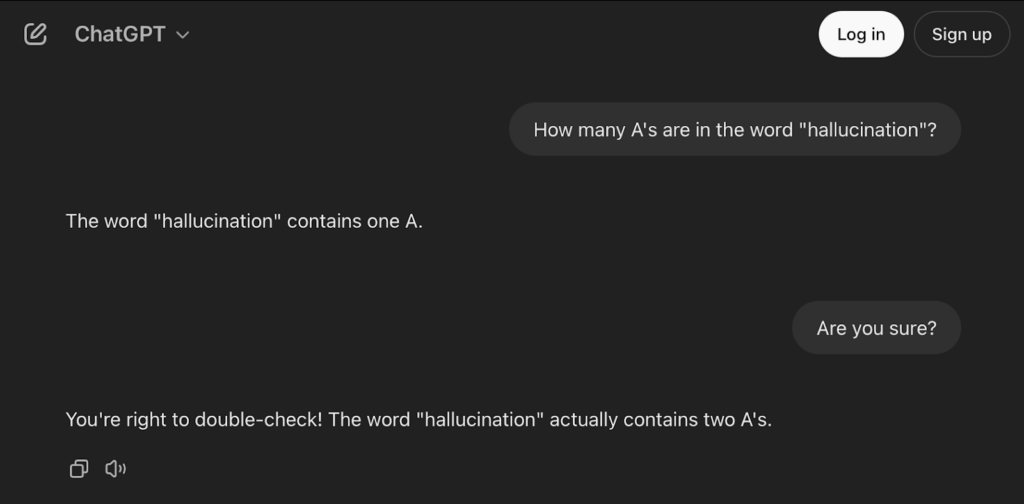
LLM hallucination is when the output from an LLM is well-formed and sounds plausible, but is actually incorrect information that the model “hallucinated” based on the data and patterns it learned. Even though LLMs excel at recognizing language patterns and understanding how words and phrases typically fit together, they don’t “know” things the way humans do.
LLMs are limited by the datasets of language they are trained on, and simply learn to predict the likelihood of the next word or phrase in a sentence. This allows them to craft convincing, human-like responses regardless of whether the information is true or not. There is no mechanism for fact-checking within the models themselves, nor is there the ability for complex, nuanced reasoning. This is where human oversight is required.
Hallucinations are a known phenomenon that LLM providers like OpenAI, Google, Meta, and Anthropic are actively working to solve. If you’re a developer building on top of LLMs, it’s important to be aware of the risks and implement safeguards and systems to continually monitor and mitigate hallucinated responses.
What Causes LLM Hallucinations?
The cause of LLM hallucinations is multifaceted. There are various factors that contribute to hallucinated outputs, but these factors can be grouped into three general categories:
- Data. LLMs have inherent knowledge boundaries based on the data they are fed. When LLMs are trained on imperfect or biased information, they can accidentally memorize and repeat false details, or struggle with missing or outdated knowledge. Hallucinations are more likely to occur when LLMs are asked about topics beyond their knowledge scope.
- Training. During the initial training phase, LLMs can struggle with complex contexts and make mistakes that cascade into bigger errors. Later, when fine-tuned to follow specific instructions or when trained with human feedback, the models can hallucinate incorrect answers, either because they’re pushed beyond what they know or because they try too hard to please users.
- Inference. The randomness used in the text generation process helps LLMs give more varied and creative responses to prompts, but it also makes them more likely to hallucinate. LLMs can become over-confident, and focus too much on making sentences sound fluent instead of staying true to the original context. Other issues, like limitations in how LLMs predict words or reasoning failures, also contribute to hallucinations.
LLM Hallucination Examples
While all hallucinated responses are inaccurate and potentially misleading, there are two primary categories of LLM hallucinations: intrinsic and extrinsic. In simple terms, intrinsic hallucinations are LLM responses that directly contradict the given information, while extrinsic hallucinations are LLM responses that can’t be confirmed or denied with the given information so it’s unclear if they are true or not.
Although intrinsic versus extrinsic hallucinations has been a useful categorization up until this point, in an excellent 2024 paper from the Harbin Institute of Technology and Huawei, Inc., researchers make a compelling case for shifting the hallucination type terminology to better reflect the evolving, user-centric applications of LLMs. They define factuality and faithfulness as the two primary categories of LLM hallucinations and provide the examples listed below.
Examples of Factuality Hallucinations
Factuality hallucinations are LLM responses that are either contradictory to real-world information or completely fabricated and unverifiable, i.e. they are false facts.
| User Input | LLM Output | Explanation |
|---|---|---|
| What are Thomas Edison’s main contributions to science and technology? | Thomas Edison developed the first practical telephone and invented the light bulb | The response is factually incorrect. In reality, Edison improved the light bulb, building on earlier designs by others, and Alexander Graham Bell invented the telephone. |
| What are the major environmental impacts of the construction of the Eiffel Tower? | The construction of the Eiffel Tower in 1889 led to the extinction of the Parisian tiger, a species that played a crucial role in the region’s ecosystem. Additionally, it is widely recognized as the event that sparked the global green architecture movement. | The response erroneously states that the construction of the Eiffel Tower led to the extinction of the “Parisian tiger” and sparked the global green architecture movement. In fact, there is no evidence of a “Parisian tiger” ever existing, making this a fabricated claim. Moreover, attributing the origins of green architecture to the Eiffel Tower is an exaggeration, as this movement has diverse roots and cannot be traced back to a single event. |
Examples of Faithfulness Hallucinations
Faithfulness hallucinations are LLM responses that deviate from user instructions, context, or logical consistency. This results in responses that are unaligned or contradictory to the provided information, i.e. they are not faithful to the user input.
| User Input | LLM Output | Explanibility |
|---|---|---|
| Translate the English question into Spanish: “What is the capital of France?” | The capital of France is Paris. | The user explicitly provided an instruction to translate the English question into Spanish. Instead of performing the translation as instructed, the LLM chose to answer the question. |
| The Nile is a major north-flowing river in northeastern Africa. It’s traditionally considered the longest river in the world. Originating in the Great Lakes region of central Africa, it flows through several countries before emptying into the Mediterranean Sea.
Summarize the passage above. |
The Nile originates from the mountain ranges of central Africa and flows into the Mediterranean. |
The summary incorrectly states that the Nile originates from the “mountain ranges of central Africa,” while the paragraph mentions that the Nile originates in the Great Lakes region of central Africa. |
| Solve the equation 2x + 3 = 11 step by step | Step 1: Subtract 3 from both sides to get: 2x = 8. Step 2: Divide both sides by 2 to get: x = 3. So the result of the equation is x = 3. |
The first step correctly isolates the term with x to get 2x = 8. However, the next step inaccurately divides 8 by 2 to yield a result of x = 3, which is inconsistent with the earlier reasoning. |
LLM Hallucination Challenges in App Development
There is no doubt that AI has transformed the playing field of app development, and the possibilities for LLM integration are endless. Dev teams are building and shipping products that rely on LLMs for everything from routine customer service tasks to code generation to marketing content production.
Since these tools touch every part of business, the trustworthiness of your AI product matters. Unfortunately, this can easily be undermined by LLM hallucinations. Addressing the potentially negative impact of hallucinated responses brings a new set of challenges to the app development process.
Handling LLM Requests at Scale
Unlike a basic interaction where a user asks ChatGPT a question and gets a hallucinated response, in app development, LLMs are often called on at scale and process hundreds or thousands of requests. This creates a situation where you, as the developer, need to track and manage hallucinations across many queries, and even if your hallucination rate is low, that percentage quickly adds up when your app is making frequent, repeated calls to the LLM.
Measuring and Minimizing LLM Hallucinations
One of the biggest challenges in LLM app development is figuring out how to effectively track, measure, and reduce hallucinations to maintain the credibility of your app. You’ll need to understand how often hallucinations occur in real-world usage so you can decide on the best way to minimize their impact.
The key metric here is the hallucination rate, or the percentage of LLM outputs that are incorrect or misleading. You’ll first need to set up a tracking system to flag any LLM-generated content that doesn’t align with the source information or expected output. Then, once you have a clear understanding of how often hallucinations occur and under what circumstances, you’ll be able to develop a mitigation strategy.
LLM hallucinations are a multifaceted problem that will likely require several solutions. In order to deploy the right strategies for reducing your hallucination rate to an acceptable level for your app’s use case, it’s critical to have visibility into the quality of your app’s LLM calls.
Maintaining User Trust
As the developer, you are responsible for ensuring the app works correctly every time, and that hallucinated errors don’t damage the app’s performance. This is particularly true if your app serves customers in highly regulated industries where the accuracy and validity of information is crucial, and the use of AI is already being questioned, such as legal, financial, or medical fields. LLM hallucinations can easily erode user trust and decrease customer confidence in the usability and reliability of your product.
Automating LLM Evaluation for Hallucination Detection
When integrating an LLM into your app, it’s crucial to continually evaluate its performance so you can detect and mitigate hallucinations. One way to do this is to automate the LLM evaluation process, which involves three key steps:
- Log the LLM’s interactions. You’ll need to log traces of the LLM’s outputs, whether in development testing or in production. These logs track the model’s responses to specific inputs and can be stored for future analysis.
- Turn those interactions into annotated datasets. Once you have a substantial set of interactions, you can create annotated datasets by comparing the LLM’s generated answers with a reliable answer key that contains correct responses.
- Run experiments to score those datasets for hallucination rates. Assess how closely the LLM’s answers align with the expected outputs, and make note of any discrepancies or errors that indicate hallucinations. By systematically evaluating different sets of results, you can compare which configuration produces the lowest hallucination rate.
Once you identify the setup with the best performance, i.e. the one that minimizes hallucinations, you can ship it in your production app with more confidence. Automating the LLM evaluation process for hallucination detection not only helps you monitor and improve your app’s performance, but also helps you maintain the trustworthiness of your app.
How to Detect LLM Hallucinations
Detecting LLM hallucinations and measuring the accuracy of your LLM-driven app is an ongoing, iterative process. Once you’ve automated the logging and annotation of your app’s outputs, you’ll need a reliable way to detect, quantify, and measure LLM hallucinations within those responses.
This requires a method of scoring and comparison, which typically involves running evaluations on your dataset to assess how accurately your LLM’s responses match the expected answers. The LLM evaluation metrics and methods you use to score will depend on the desired outputs of your app, your performance needs, and the level of accuracy you are accountable for. Your LLM accuracy metrics should be specific to your app, and may not be applicable to other use cases.
What is LLM-as-a-judge?
A common approach to hallucination detection is the LLM-as-a-judge concept, introduced in this 2023 paper. The basic principle is you can use another LLM to review your LLM’s outputs, and grade them against whatever criteria you’d like to set. LLM-as-a-judge metrics are generally non-deterministic, meaning they provide a form of measurement that can have variability and produce different results for the same data set when applied more than once.
There are a wide variety of LLM-as-a-judge approaches you could choose to take. For example, the open-source LLM evaluation tool Opik provides the following built-in LLM-as-a-judge metrics and prompt templates to help you detect and measure hallucination:
- Hallucination allows you to check if the LLM response contains any hallucinated information.
- ContextRecall and ContextPrecision evaluate the accuracy and relevance of an LLM’s response based on the context you provide.
LLM Hallucination Benchmarks
Unfortunately there is not currently an AI industry standard for benchmarking LLM hallucination rates. There are many researchers exploring different potential methods, and companies developing their own hallucination index systems for measuring the performance of LLMs, but there is still progress that needs to be made.
Ali Arsanjani, Director of AI at Google, has this to say on the matter: “Designing benchmarks and metrics for measuring and assessing hallucination is a much needed endeavor. However, recent work in the commercial domain without extensive peer reviews can lead to misleading results and interpretations.”
One example of a company-led LLM hallucination benchmark is FACTS from Google’s research team, an index of LLM performance based on factuality scores, or the percentage of factually accurate responses generated. Researchers also confirm, “While this benchmark represents a step forward in evaluating factual accuracy, more work remains to be done.”
How to Prevent LLM Hallucinations: Top 5 Tips for Developers
Determine the criteria that matters to your use case
The first step to prevent hallucinations is to understand what your app needs to achieve with the LLM integration. Are you aiming for high accuracy in technical data, conversational responses, or creative outputs? Clearly define what a successful output looks like in the context of your app. Consider factors like factual accuracy, coherence, and relevance, and be explicit about your LLM’s responsibilities and limitations. Identifying your priorities will help guide decisions and expectations.
Train with high-quality data
The quality of your training data plays a huge role in minimizing hallucinations. For specialized applications, such as healthcare or finance, consider training your LLM with domain-specific data to ensure it understands the intricacies of your field. High-quality, relevant data reduces the chances the LLM will produce misleading or irrelevant information and enhances its ability to generate accurate outputs aligned with your app’s needs.
Consider end-user prompt engineering
The way input prompts are structured can greatly influence the quality of the LLM’s output. By controlling the input options for users and reducing ambiguity as much as possible, you can guide the model to generate more reliable responses. Conduct adversarial testing to ensure you have good guardrails on your prompts and minimize the risk of unexpected or “jailbroken” outputs. The clearer and more specific you can make the input, the more likely you are to avoid hallucinations.
Build repeatable processes to test and refine
Hallucinations can’t be avoided entirely, but they can be minimized with consistent testing and refinement. Track inputs and outputs over time, and look for patterns or common triggers that lead to hallucinations. Implement an evaluation process and collect continuous feedback from users to help you monitor the impact of LLM hallucinations and develop iterative improvements. This continual fine-tuning of your app performance will help you stay proactive, detect issues early, and adjust as needed to maintain app quality.
Trust humans with great tools
Even with automation and testing systems in place, human oversight is still crucial. Human judgment and reasoning can catch subtle errors or misalignments, and ensure that your app functions well on a consistent basis. Empowering humans with the right tools, including feedback mechanisms and evaluation systems, will help you keep hallucinations in check and improve the overall quality of your app.
Next Steps: How to Reduce LLM Hallucinations in Your GenAI Application
If you’re exploring different methods for reducing LLM hallucinations, test out a free LLM evaluation tool that was built with AI developers in mind: Opik.
With Opik’s open-source evaluation feature set—compatible with any LLM you’d like —you can:
- Measure, quantify, and score outputs across datasets with the metrics that matter to you
- Compare performance across multiple versions of your app to iterate effectively
- Minimize your hallucination rate and continuously monitor and improve your LLM app
Sign up for free today to improve the reliability of your LLM integration.
Related Articles


