Large Language Models: Navigating Comet LLMOps Tools
Hey there! I’m so excited to talk to you about Language Models! They’re these incredible creations called Large Language Models (LLMs) that have the power to understand and generate human-like text. It’s like having a conversation with a machine that can understand what you’re saying and respond meaningfully. How cool is that?
LLMs are part of the GPT-3.5 family developed by OpenAI. They have been trained on massive text data, absorbing information from books, articles, websites, and more. But don’t worry; they are not just robotic encyclopedias. They’ve been designed to engage in dynamic and personal conversations; you can think of it as your friendly and knowledgeable digital companion, here to help answer your questions, spark interesting discussions, or even assist with creative tasks. It can provide information on various topics, share insights, and offer suggestions. Whether you’re curious about the latest news, want to dive into scientific concepts, or seek advice on everyday life.
One of the most fascinating aspects of LLMs is the ability to generate text that sounds remarkably human. It has been trained to understand context, infer meaning, and produce responses that align with the conversation. So, when you’re chatting with it, it’s like talking to someone well-informed and ready to engage in a genuine discussion.
Of course, it’s important to remember that while LLMs like me are pretty impressive, it is not flawless. It may occasionally generate responses that aren’t entirely accurate or misunderstand specific nuances. However, it constantly learns and improves through feedback, so the more you interact with it, the better it will understand your needs and provide valuable insights.
This article will discuss navigating the Comet LLMOps tool, the new LLM SDK, and much more. Let’s get started!
Comet LLMOps
Comet’s LLMOps tools allow users to leverage the latest advancements in Prompt Management and query models in Comet to iterate quicker, identify performance bottlenecks, and visualize the internal state of the Prompt Chains.
Comet’s LLMOps tools are focused on quicker iterations for the following:
- Prompt History: Keeping track of prompts, responses, and chains is critical to understanding and debugging the behavior of ML products based on Large Language Models. Comet’s LLMOps tool provides an intuitive and responsive view of our prompt history.
- Prompt Playground: With the LLMOps tool comes the new Prompt Playground, which allows Prompt Engineers to iterate quickly with different Prompt Templates and understand the impact on different contexts.
- Prompt Usage Tracker: Working and iterating on Large Language models may require us to use paid APIs. Comet’s LLMOps tool tracks usage based on a project and experiment level to help us understand our usage at a granular level.
Working with Comet LLM
To use this tool, we need to have an account with Comet — an MLOps platform designed to help data scientists and ML teams build better models faster! Comet provides tooling to track, explain, manage, and monitor our models in a single place.
After signing up, log in to your dashboard and create a new project.

We must fill in our project name and description and, most importantly, set the project type to large language models. Then, hit the create button.

We will use the LLM SDK, which is open-sourced and has really extensive LLMOps functionality. It can be installed using pip via terminal or Command line:
pip install comet-llm
Note: It is very important to note that the LLM SDK is under active development.
Using the LLM SDK to Log Prompts and Responses
The LLM SDK supports logging prompts with its associated response and any associated metadata like token usage. This can be achieved through the function log_prompt:
Let’s log our first and simple prompt and responses:
import comet_llm
comet_llm.log_prompt(
prompt="What is your name?",
output=" My name is Leo, and I your customer assistant!",
api_key="<API Key>",
project="mboxs",
workspace="zenunicorn",
)
The prompt and response get logged into our Comet dashboard:

Args:
- prompt: str (required) input prompt to LLM.
- output: str (required), output from LLM.
- api_key: str (optional) comet API key.
- project: str (optional) project name to create in the Comet workspace.
- workspace: str (optional) Comet workspace to use for logging.
Other arguments that can be used include:
- tags: List[str] (optional), user-defined tags attached to a prompt call.
- prompt_template: str (optional) user-defined template used for creating a prompt.
- prompt_template_variables: Dict[str, str] (optional) dictionary with data used in prompt_template to build a prompt.
- metadata: Dict[str, Union[str, bool, float, None]] (optional) user-defined dictionary with additional metadata to the call.
- timestamp: float (optional) timestamp of prompt call in seconds.
- duration: float (optional) duration of prompt call.
Full details can be found here.
Now, let’s log a full prompt and response with most of the args above.
# Log a full prompt and response
comet_llm.log_prompt(
prompt="Answer the question and if the question can't be answered, say \"I don't know\"\n\n---\n\nQuestion: What is your name?\nAnswer:",
prompt_template="Answer the question and if the question can't be answered, say \"I don't know\"\n\n---\n\nQuestion: {{question}}?\nAnswer:",
prompt_template_variables={"question": "What is your name?"},
metadata= {
"usage.prompt_tokens": 7,
"usage.completion_tokens": 5,
"usage.total_tokens": 12,
"output.index": 0,
"output.logprobs": None,
"output.finish_reason": "length",
"input.type": "completions",
"input.model": "text-davinci-003",
"input.provider": "openai",
},
output="My name is Leo. How can I help you today?",
duration=16.598,
api_key="<API KEY>",
project="mboxs",
workspace="zenunicorn",
)
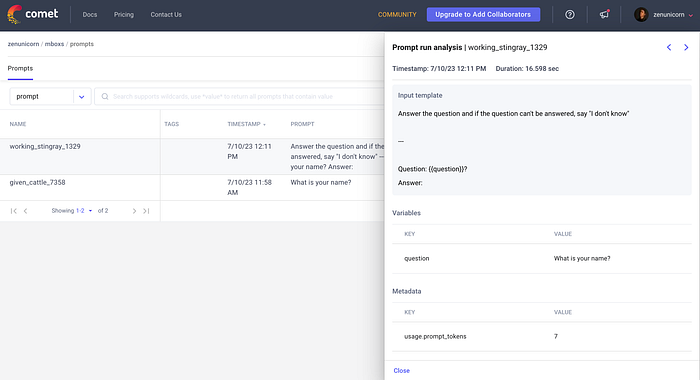
All the information, such as the prompt, response, metadata, duration, etc., has been logged and can be viewed in a table sidebar by clicking on the specific row.

Conclusion
In conclusion, LLMs (Language Model Models) significantly advance NLP (natural language processing). These models have demonstrated remarkable capabilities in understanding and generating human-like text, offering tremendous potential for various applications and industries.
The Comet LLM SDK is under active development, and the Comet team is currently planning on implementing support for logging LLM chains, viewing and diffing of chains, logging prompt and response embeddings, tracking user feedback, grouping of prompts, and so much more.
For more tutorials on how to integrate with Leading Large Language Models and Libraries, check out:
As LLMs continue to evolve and improve, coupled with the innovative features provided by Comet LLMops, we can anticipate even more significant strides in NLP, opening up new possibilities for communication, creativity, and problem-solving.
Feel free to reach out on GitHub with any and all feature requests!
Related Articles


