And An Assessment of How They Impact Your ragas Metrics

If you’ve ever wondered how the quality of information sourced by language models affects their outputs, you’re in the right place. I’m trying to unpack how different document loaders in LangChain impact a Retrieval Augmented Generation (RAG) system.
Why is this important?
RAG is a game-changer. It cleverly combines retrieving information from external documents with the generative capabilities of language models. However, the effectiveness of this system hinges on one critical aspect — the method used to retrieve documents.
This blog is about exploring and understanding this pivotal element.
We’ll focus on three key players in LangChain:
- WebBaseLoader
- SeleniumURLLoader,
- NewsURLLoader.
Each has its approach to fetching information, and we will find out how these methods shape the final output of RAG models.
I invite you to join this exploration — it’s not just an exploration of code and algorithms but a journey to enhance the intelligence and responsiveness of AI systems.
🧑🏽💻 Let’s write some code!
Start with some preliminaries and setting the environment.
%%capture
!pip install langchain openai unstructured selenium newspaper3k textstat tiktoken faiss-cpu
import os
import getpass
from langchain.document_loaders import WebBaseLoader, UnstructuredURLLoader, NewsURLLoader, SeleniumURLLoader
import tiktoken
import matplotlib.pyplot as plt
import pandas as pd
import nltk
from nltk.tokenize import sent_tokenize, word_tokenize
from nltk.corpus import stopwords
from textstat import flesch_reading_ease
from collections import Counter
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
from langchain.text_splitter import RecursiveCharacterTextSplitter
os.environ['OPENAI_API_KEY'] = getpass.getpass("Input your Open AI Key:")
For this demonstration, we’ll use this website.
website = "https://phys.org/news/2023-11-qa-dont-blame-chatbots.html"
The function below will load the website into a LangChain document object:
def load_document(loader_class, website_url):
"""
Load a document using the specified loader class and website URL.
Args:
loader_class (class): The class of the loader to be used.
website_url (str): The URL of the website from which to load the document.
Returns:
str: The loaded document.
"""
loader = loader_class([website_url])
return loader.load()
Understanding the WebBaseLoader

When extracting text from websites, the WebBaseLoader in LangChain is a tool you need to know about.
It’s like a skilled miner adept at digging through the layers of a website to retrieve the valuable textual content beneath. Let’s explain exactly how it works and what this means for embedding documents into a vector database.
Want to learn how to build modern software with LLMs using the newest tools and techniques in the field? Check out this free LLMOps course from industry expert Elvis Saravia of DAIR.AI!
How WebBaseLoader Retrieves Text
The WebBaseLoader uses HTTP requests, a basic yet powerful way to communicate with web servers. Think of it as sending a letter to a website asking for its content. Once the website replies, WebBaseLoader takes over, sifting through the HTML — the foundational code of web pages.
This is where BeautifulSoup, a Python library, comes into play. WebBaseLoader uses BeautifulSoup to parse the HTML, effectively reading and extracting the text. It’s like having a translator who can interpret the complex language of HTML and present you with just the readable text.
Impact on Document Embedding and Vector Databases
When this extracted text is embedded into a vector database, there are a few implications:
- Quality of Extracted Text: WebBaseLoader relies on HTML structure and excels with well-structured websites. However, it might struggle with JavaScript-generated dynamic content, which is increasingly common in modern web design. This means the text it retrieves is as good as the HTML it interprets.
- Efficiency: WebBaseLoader is efficient and fast, handling multiple requests seamlessly. This efficiency translates into quicker embedding of documents into your vector database, which is crucial for large-scale applications.
- Relevance: The relevance of the extracted text can vary. In cases where websites are loaded with ads or unrelated content alongside the main text, WebBaseLoader might fetch some noise and valuable data. This could impact the precision of your RAG system’s outputs.
While it’s efficient and effective for static content, its performance can be limited by dynamic web elements. Remember the content you’re targeting as we dive into document embedding and vector databases.
If you focus on static, well-structured websites, WebBaseLoader could be your workhorse in the RAG pipeline.
wb_loader_doc = load_document(WebBaseLoader, website)
You can examine the extracted content from any of the loaders with the following pattern:
wb_loader_doc[0].page_content
Grasping the SeleniumURLLoader

Imagine a scenario where you need to extract text from a website as dynamic as a bustling city street — changing every moment, filled with interactive elements and content that loads as you scroll.
The SeleniumURLLoader steps in, bringing a different skill set than the WebBaseLoader.
How SeleniumURLLoader Retrieves Text
The SeleniumURLLoader is like an undercover agent in the world of web browsers.
It doesn’t just send a request to a website; it navigates the web as a user would. Using Selenium, a powerful tool for browser automation, it opens an actual browser window (in headless mode, meaning without a graphical interface) and interacts with the webpage. This ability to simulate user interactions is crucial for websites where content is rendered through JavaScript — a common scenario in modern web development.
Before extracting the text, the loader waits for the page to load, including any dynamic content.
Impact on Document Embedding and Vector Databases
- Comprehensive Text Retrieval: Since it interacts with web pages like a human user, SeleniumURLLoader can retrieve text that other methods might miss. This includes content that appears due to user interactions or is dynamically loaded by JavaScript.
- Performance Considerations: The thoroughness of SeleniumURLLoader comes at a cost. It’s slower and more resource-intensive than more straightforward HTTP request methods. When embedding documents into a vector database, this could mean longer processing times, especially for large volumes of data.
- Accuracy and Relevance: The text retrieved by SeleniumURLLoader tends to be highly accurate and reflective of the user’s experience on the website. This can lead to more relevant and context-rich embeddings in your vector database, potentially enhancing the quality of your RAG system’s outputs.
The SeleniumURLLoader is your toolkit’s Swiss army knife for dealing with dynamic, JavaScript-heavy websites. It offers a depth of text retrieval unmatched by more straightforward methods but requires more resources and time.
A RAG pipeline is the ideal choice when your focus is on comprehensively capturing the essence of modern, interactive web pages.
selenium_loader_doc = load_document(SeleniumURLLoader, website)
With the WebBaseLoader and SeleniumURLLoader covered, we’ll next explore the NewsURLLoader, a specialized tool for news content.
Unveiling the NewsURLLoader in LangChain
NewsURLLoader is designed specifically for news articles.
How NewsURLLoader Retrieves Text
The NewsURLLoader doesn’t just fetch text; it’s adept at navigating through the unique structure of news articles.
Using the newspaper library, a Python package tailored for news extraction, performs a more refined retrieval. This loader not only fetches the article but also understands the typical layout of news websites, effectively separating the main content from the clutter of ads and sidebars. Moreover, the NewsURLLoader can perform light NLP (Natural Language Processing) tasks.
This means it doesn’t just hand you the text; it can also provide summaries and extract keywords, offering a more concise and focused insight into the content.
Impact on Document Embedding and Vector Databases
- Targeted and Clean Extraction: The NewsURLLoader is designed explicitly for news content, which means it can efficiently extract clean and relevant text from news articles. This leads to high-quality document embeddings, especially valuable for news-related queries in an RAG system.
- NLP Enhancements: The optional NLP features of the NewsURLLoader add an extra layer of value. By embedding summarized content and key terms, your vector database can become more efficient, focusing on the essence rather than the bulk of news articles.
- Scope Limitation: While it’s a powerhouse for news content, the NewsURLLoader’s specialization is also its limitation. It’s different than the tool for general-purpose web scraping or for handling dynamic, interactive content like the SeleniumURLLoader.
The NewsURLLoader shines in its domain, making it an excellent choice for RAG systems focused on current events, journalism, or news analysis. It offers clean, concise, and relevant text extraction, with the bonus of NLP processing.
Analyzing the content from each loader
In this analysis, you’ll dive deep into the text extracted by the three document loaders: WebBaseLoader, SeleniumURLLoader, and NewsURLLoader.
You’ll compare their outputs based on specific metrics: the total number of characters, the count of alphanumeric characters, the number of newline characters, and the total number of tokens as determined by GPT-4 encoding.
The goal is to quantitatively assess the nature and quality of text each loader extracts. This technical analysis will provide clear insights into the efficiency and accuracy of these loaders, helping us understand their impact on a Retrieval Augmented Generation system.
You’ll present our findings through concise bar plots, comparing each loader’s performance straightforwardly.
def count_alphanumeric(text):
"""
Count the number of alphanumeric characters in a given text.
Args:
text (str): The text to be analyzed.
Returns:
int: The total number of alphanumeric characters in the text.
"""
return sum(char.isalnum() for char in text)
def num_tokens_from_string(string: str) -> int:
"""Returns the number of tokens in a text string."""
encoding = tiktoken.encoding_for_model("gpt-4-1106-preview")
num_tokens = len(encoding.encode(string))
return num_tokens
def analyze_texts(texts):
"""
Analyze the given texts to count total, alphanumeric, and newline characters.
Args:
texts (dict): A dictionary where keys are identifiers (e.g., loader names) and
values are the corresponding text strings.
Returns:
tuple of dicts: A tuple containing three dictionaries, each with counts of
total characters, alphanumeric characters, and newline characters respectively.
"""
total_characters = {loader: len(text) for loader, text in texts.items()}
alphanumeric_characters = {loader: count_alphanumeric(text) for loader, text in texts.items()}
newline_characters = {loader: text.count('\n') for loader, text in texts.items()}
token_count = {loader: num_tokens_from_string(text) for loader, text in texts.items()}
return total_characters, alphanumeric_characters, newline_characters, token_count
def plot_data(data, title):
"""
Create a bar plot for the given data.
Args:
data (dict): A dictionary containing the data to be plotted. Keys are considered as labels
and values as the corresponding data points.
title (str): The title of the plot.
Note:
The bars in the plot are colored blue, green, and red, in the order of the dictionary keys.
"""
plt.bar(data.keys(), data.values(), color=['blue', 'green', 'red'])
plt.title(title)
plt.ylabel('Count')
plt.xticks(rotation=45)
plt.show()
total_chars, alphanumeric_chars, newline_chars, token_count = analyze_texts(texts)
Analyzing the Extracted Text
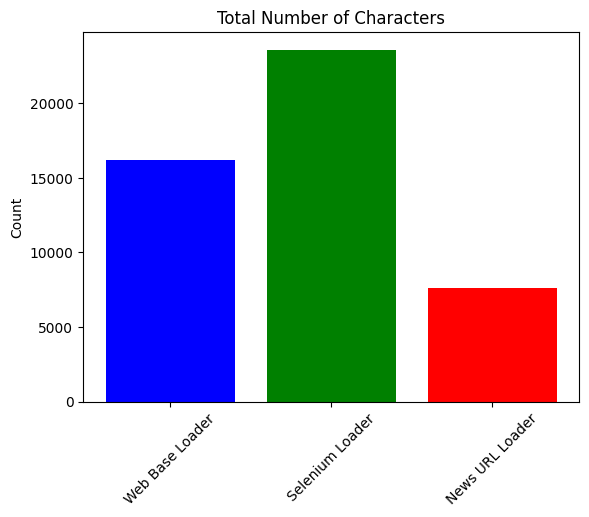
WebBaseLoader (16,191 Characters)
The text includes a mix of the main article content, website navigation elements, metadata, and other peripheral information. This indicates that WebBaseLoader extracts all text from the HTML without differentiating between the main content and other page elements.
Potential Challenges for RAG System
- Noise in Data: The presence of non-relevant text (e.g., menu items, footer information) can introduce noise, potentially impacting the accuracy and relevance of the RAG system’s outputs.
- Need for Post-Processing: To enhance the quality of embeddings, you might need to post-process this text to filter out irrelevant parts and focus on the main content.
SeleniumURLLoader (23,598 Characters)
The highest character count comes from the SeleniumURLLoader. This can be attributed to its method of loading pages as a browser would, capturing the primary content and potentially more of the surrounding elements and dynamically loaded content.
This text, similar to the WebBaseLoader’s output, includes the main article content and additional elements like website headers, footers, and navigation links. However, it’s more focused on the article, suggesting a better capture of the intended content.
Potential Challenges for RAG System
- Reduced Noise, But Still Present: While there’s less irrelevant text compared to the WebBaseLoader output, the presence of some non-article elements can still introduce noise.
- Post-Processing Consideration: Like with the WebBaseLoader, filtering out irrelevant parts will enhance the quality of embeddings.
NewsURLLoader (7,580 Characters)
The NewsURLLoader shows the lowest character count.
The text appears more focused and streamlined than WebBaseLoader and SeleniumURLLoader’s outputs. It mainly consists of the main article content, with minimal peripheral information. This indicates that the NewsURLLoader is effectively targeting and extracting the core content of the news article.
Potential Challenges for RAG System
- High Relevance and Quality: The content’s higher relevance and focused nature mean it’s more likely to produce accurate and contextually relevant embeddings in a vector database.
- Limited Need for Post-Processing: Unlike the other two loaders, the NewsURLLoader requires minimal post-processing to filter out noise, as it already provides a clean extraction of the news content.
Implications
- WebBaseLoader: Offers a balance between breadth and depth, suitable for general-purpose web scraping where capturing a wide range of content is necessary.
- SeleniumURLLoader: Ideal for scenarios where comprehensive text capture, including dynamic content, is crucial. However, this can lead to a larger volume of data, potentially increasing processing time and resource usage.
- NewsURLLoader: Best suited for applications where focused and relevant content extraction is key, such as news aggregation and analysis, providing clean and concise outputs.
These insights help in understanding how each loader functions and in choosing the right tool depending on the specific requirements of your application, especially in an RAG pipeline.
More analysis
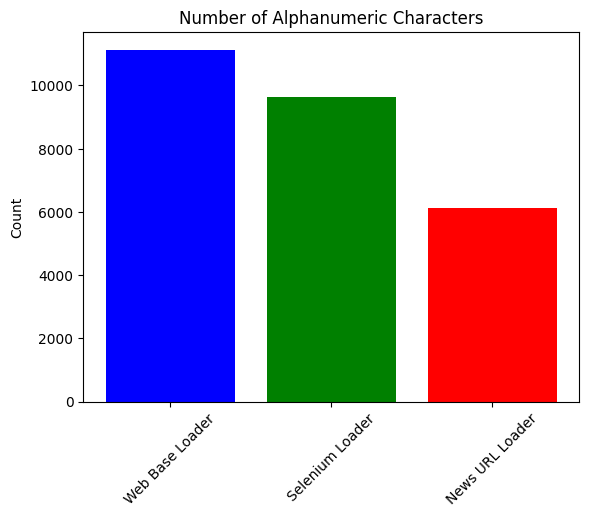
You can do a similar analysis as above across different axes:
plot_data(alphanumeric_chars, 'Number of Alphanumeric Characters')
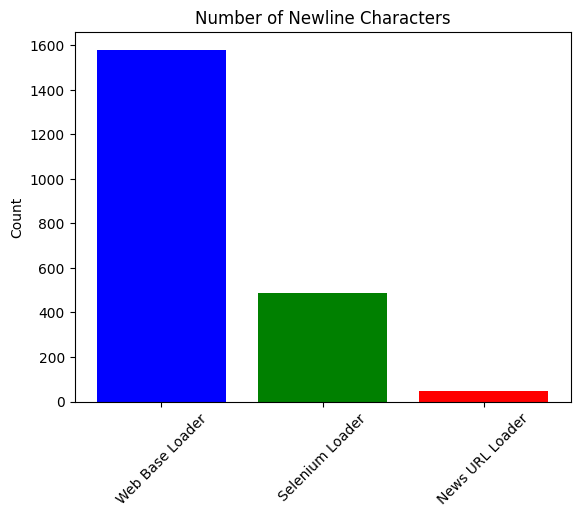
plot_data(newline_chars, 'Number of Newline Characters')
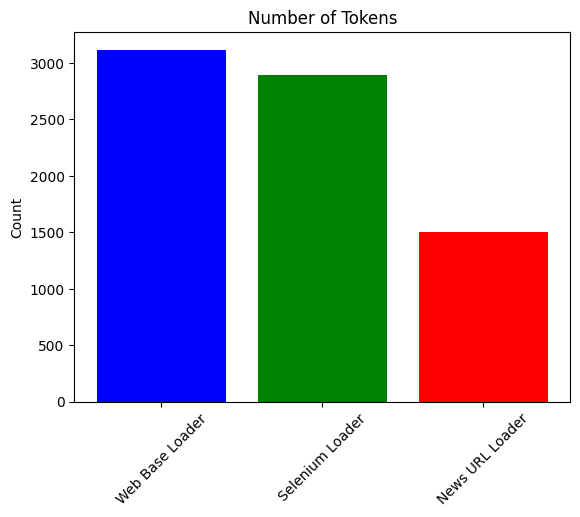
plot_data(token_count, 'Number of Tokens')
Why do we see this difference?
The discrepancy in the number of characters each loader extracted can be attributed to their distinct methodologies and the source code that drives their functionality.
Here’s a breakdown based on the source code and operational differences:
WebBaseLoader
- Methodology: It performs direct HTML fetching using HTTP requests and parses the HTML content with BeautifulSoup.
- Why the Difference: This loader extracts all text content from the HTML, including main content, navigation elements, headers, footers, and possibly some script elements. However, it does not execute JavaScript, so any content loaded dynamically (which is common in modern web pages) is not captured. This can lead to a moderate character count — substantial but not exhaustive.
SeleniumURLLoader
- Methodology: Uses Selenium for browser automation, which launches a browser instance (often in headless mode) and interacts with the page like a human user. It can execute JavaScript and capture dynamically loaded content.
- Why the Difference: The higher character count is likely due to this loader’s ability to capture more comprehensive content, including dynamic elements that only load upon user interaction or as a part of JavaScript execution. This method fetches the static HTML content and the additional text that becomes available as the page fully renders in a browser environment. This thorough approach results in capturing a larger volume of text.
NewsURLLoader
- Methodology: Utilizes the
newspaperlibrary designed explicitly for scraping and curating news articles. It is optimized for extracting article content while excluding unrelated material. - Why the Difference: The lower character count reflects its focused extraction. The
newspaperlibrary targets the core article text and is adept at ignoring extraneous content like ads, sidebars, or site navigation elements. This results in a cleaner and more concise text extraction, focusing primarily on the main news content.
Summary
- WebBaseLoader: Provides a broad capture of HTML content but misses dynamic content, leading to a moderate character count.
- SeleniumURLLoader: Captures a complete picture of the webpage, including dynamic content, which results in the highest character count.
- NewsURLLoader: Highly specialized and focused on news content, leading to the lowest character count due to its targeted extraction.
Splitting text for retrieval using RecursiveCharacterTextSplitter
RecursiveCharacterTextSplitter is designed to split text into chunks based on a list of separators, which can be tailored for different programming languages or text formats.
The class employs a recursive approach to splitting, ensuring that if one separator doesn’t result in a split, it falls back to the next one in the list.
Here’s a breakdown of the key components and functionalities of this class:
- Separators: The class takes a list of separators (
separators) which are used to split the text. The default list includes common separators like new lines and spaces. The separators can be regular expressions ifis_separator_regexis set toTrue. - Recursive Splitting: The method
_split_textattempts to split the text using the provided separators. If a separator doesn’t successfully split the text, or if the resulting chunks are too large (exceed the specified chunk size), the method recursively tries with the next separator in the list. - Language-Specific Separators: The class can adapt its separators based on the programming language of the text, as indicated by the
get_separators_for_languagemethod. This method returns a list of separators appropriate for programming languages like Python, Java, C++, etc. - Chunk Size and Merging: The class ensures that the resulting chunks are within a certain size limit (
_chunk_size). If smaller chunks are created, they can be merged back together to ensure that each chunk is of a reasonable size.
To use this class effectively:
- Instantiate the Class: Create an instance of
RecursiveCharacterTextSplitter, specify the separators if the default ones are unsuitable for your text. - Split Texts: Use the
split_textmethod to split the texts from each of your loaders. - Post-Processing: After splitting, you may need to post-process the chunks, especially if the splitting results in broken sentences or contexts.
- Further Analysis: Once the text is split into manageable chunks, you can proceed with your analysis by creating embeddings or pushing them to a vector database.
This class is handy when dealing with large text files or texts where a simple split by a single character (like a newline) is insufficient. It allows for a more nuanced and flexible approach to text splitting, catering to the specific structural nuances of different text types.
text_splitter = RecursiveCharacterTextSplitter(
# Set a really small chunk size, just to show.
chunk_size = 250,
chunk_overlap = 5,
length_function = len
)
texts = {
'Web Base Loader': wb_loader_doc[0].page_content,
'Selenium Loader': selenium_loader_doc[0].page_content,
'News URL Loader': newsurl_docs[0].page_content
}
def create_chunks(document):
return text_splitter.split_documents(document)
# Creating chunks for each document
wb_chunks = create_chunks(wb_loader_doc)
selenium_chunks = create_chunks(selenium_loader_doc)
newsurl_chunks = create_chunks(newsurl_docs)
chunk_counts = {
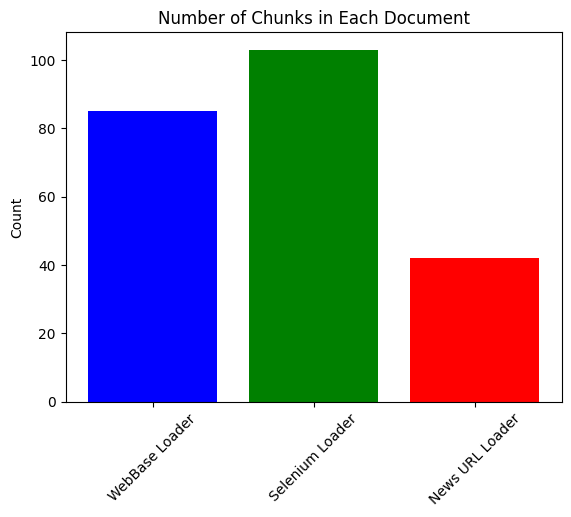
'WebBase Loader': len(wb_chunks),
'Selenium Loader': len(selenium_chunks),
'News URL Loader': len(newsurl_chunks)
}
plot_data(chunk_counts, 'Number of Chunks in Each Document')
RAG Pipeline
To set up your RAG pipeline, you must create vector store retrievers. The following code will do that for you:
def create_index_and_retriever(chunks, embeddings):
"""
Create an index and retriever for the given chunks using the specified embeddings.
Args:
chunks (list): List of text chunks to be indexed.
embeddings (Embeddings object): Embedding model used for creating the index.
Returns:
retriever (Retriever object): The retriever object for the created index.
"""
index = FAISS.from_documents(chunks, embeddings)
retriever = index.as_retriever()
return retriever
# Embedding and Language Model setup
embeddings = OpenAIEmbeddings(show_progress_bar=True)
llm = ChatOpenAI(model="gpt-4-1106-preview")
# Creating indexes and retrievers
wb_retriever = create_index_and_retriever(wb_chunks, embeddings)
selenium_retriever = create_index_and_retriever(selenium_chunks, embeddings)
news_url_retriever = create_index_and_retriever(newsurl_chunks, embeddings)
The following are the questions (queries )and ground truth answers (answers) that you’ll use to assess the performance of each retriever.
queries = [
"What are educators' main concerns regarding using AI chatbots like ChatGPT by students?",
"Why do the Stanford researchers believe that concerns about AI chatbots leading to increased student cheating are misdirected?",
"What findings have the Stanford researchers gathered about the prevalence of cheating among U.S. high school students in the context of AI chatbots?",
"What alternative reasons might explain why students cheat, according to the article?",
"What recommendations or strategies do the article or researchers suggest for addressing academic dishonesty in schools?"
]
answers = [
"Educators are concerned about students using AI chatbots like ChatGPT to cheat by passing off AI-generated writing as their own.",
"Stanford researchers believe concerns about AI chatbots leading to increased cheating are misdirected because cheating predates these technologies, and when students cheat, it's typically for reasons unrelated to technology access.",
"Their research shows that 60% to 70% of students admitted to cheating before the advent of AI chatbots, and this rate has remained constant or even slightly decreased in 2023.",
"Alternative reasons for cheating include struggling with material, excessive homework, assignments feeling like busywork, and overwhelming pressure to achieve.",
"Recommended strategies include helping students feel more engaged and valued, addressing deeper systemic problems, and promoting a sense of belonging, purpose, and connection in the educational environment."
]
The QAChainRunner is a pivotal component designed to streamline the querying and retrieving answers using a RetrievalQA chain.
This class, engineered for flexibility and efficiency, is a centralized conduit between the user’s queries and the complex machinery of language model-based retrieval systems. Upon initialization, it accepts a pre-defined language model (LLM), setting the stage for sophisticated query-processing operations.
In action, the QAChainRunner takes a retriever object and a query as input.
It then dynamically constructs a RetrievalQA chain, leveraging the power of the provided language model to interpret and process the query. The real strength of this class lies in its ability to handle multiple queries seamlessly, returning a structured and comprehensive set of results. Each result includes the original query, the generated answer, and the source documents that informed the response, offering an insightful peek into the retrieval process.
In essence, QAChainRunner acts as an intelligent intermediary, transforming simple queries into insightful answers, making it an indispensable tool for any application or system focused on advanced information retrieval and question-answering tasks.
from typing import List, Dict, Any
from datasets import Dataset
class QAChainRunner:
"""
Class to handle running queries through a RetrievalQA chain.
"""
def __init__(self, llm):
self.llm = llm
def run_retrieval_qa(self, retriever, query):
"""
Run a query through the RetrievalQA chain.
Args:
retriever (Retriever object): The retriever to use.
query (str): The query to process.
Returns:
dict: The response including the query, result, and source documents.
"""
try:
qa_chain = RetrievalQA.from_chain_type(llm=self.llm,
retriever=retriever,
verbose=True,
return_source_documents=True)
return qa_chain.invoke(query)
except Exception as e:
print(f"Error in running RetrievalQA: {e}")
return {"query": query, "result": None, "source_documents": []}
def run_queries(self, retriever, queries: List[str]) -> List[Dict[str, Any]]:
"""
Run multiple queries through the RetrievalQA chain.
Args:
retriever (Retriever object): The retriever to use.
queries (List[str]): List of queries to process.
Returns:
List[Dict[str, Any]]: List of responses for each query.
"""
return [self.run_retrieval_qa(retriever, query) for query in queries]
def parse_retrieval_qa_results(results, ground_truths):
"""
Parse the results from the RetrievalQA pipeline into a structured format.
Args:
results (List[Dict[str, Any]]): Results from the RetrievalQA pipeline.
ground_truths (List[str]): Ground truth answers.
Returns:
Dict[str, List[Any]]: Parsed results including questions, answers, contexts, and ground truths.
"""
parsed_results = {'question': [], 'answer': [], 'contexts': [], 'ground_truths': []}
for i, result in enumerate(results):
query = result.get('query')
answer = result.get('result')
source_documents = result.get('source_documents', [])
# Transform Document objects into a compatible format (e.g., string or dict)
contexts = []
for doc in source_documents:
if hasattr(doc, 'page_content'):
# Assuming doc is a Document object with a 'page_content' attribute
contexts.append(doc.page_content)
elif isinstance(doc, dict):
# If doc is already a dictionary, use as is or convert to string
contexts.append(str(doc))
else:
# Fallback for other types
contexts.append(str(doc))
parsed_results['question'].append(query)
parsed_results['answer'].append(answer)
parsed_results['contexts'].append(contexts)
parsed_results['ground_truths'].append(ground_truths[i] if i < len(ground_truths) else [])
return parsed_results
def create_hf_dataset_from_dict(parsed_results: Dict[str, List[Any]]) -> Dataset:
"""
Convert parsed results into a Hugging Face Dataset object.
Args:
parsed_results (Dict[str, List[Any]]): Parsed results from the RetrievalQA pipeline.
Returns:
Dataset: A Hugging Face Dataset object.
"""
try:
return Dataset.from_dict(parsed_results)
except Exception as e:
print(f"Error in creating dataset: {e}")
return None
Context Recall and Context Precision in ragas
Context Recall is a metric for information retrieval and natural language processing, particularly in systems like Retrieval-Augmented Generation (RAG). It measures the effectiveness of a retrieval system in fetching relevant information or documents that contribute meaningfully to generating accurate and contextually appropriate answers to queries.
Context Precision, similar to Context Recall, is a vital metric for evaluating information retrieval systems, particularly in contexts like Retrieval-Augmented Generation (RAG) models. While Context Recall focuses on the proportion of relevant documents retrieved from the total ground truths, Context Precision measures the relevance of the retrieved documents against all the documents retrieved.
How Context Recall Works
- Information Retrieval: In RAG systems, when a query is posed, the model retrieves a set of documents or contexts that it believes are relevant to the query.
- Answer Generation: The model then uses these contexts and language understanding capabilities to generate an answer.
What Context Recall Measures
- Relevance of Retrieved Contexts: Context Recall assesses how many retrieved documents are relevant or helpful in answering the query.
- Effectiveness of the Retrieval Component: It evaluates the retrieval component of the model, which is crucial for the overall quality of the answer.
How Context Recall is Measured
- Comparison With Ground Truths: Typically, for each query, there is a set of ground truth documents known to contain relevant information. Context Recall measures how many of these ground truth documents were retrieved by the model.
- Calculation: It can be calculated as the proportion or count of relevant documents retrieved out of the total ground truth documents. This is often represented as a percentage or a ratio.
Importance in AI Models
- Improves Answer Quality: High Context Recall indicates that the model effectively fetches relevant information, which is crucial for generating accurate and comprehensive answers.
- Model Optimization: By measuring Context Recall, developers can fine-tune the retrieval component of the model for better performance.
How Context Precision Works
- Information Retrieval: When a query is posed in a RAG system, the system retrieves a set of documents or contexts.
- Relevance Assessment: Context Precision assesses how many of these retrieved documents are relevant to the query.
What Context Precision Measures
- Accuracy of Retrieved Contexts: It measures the proportion of the retrieved documents relevant to the query.
- Efficiency of the Retrieval Component: High Context Precision indicates that the model’s retrieval component is active and accurate, fetching more relevant documents than irrelevant ones.
How Context Precision is Measured
- Comparison With Relevant Documents: Context Precision is calculated by dividing the number of relevant documents retrieved by the total number of documents retrieved for each query.
- Calculation: Often expressed as a percentage, it indicates the retrieval system’s accuracy.
Importance in AI Models
- Enhances the Quality of Generated Answers: Context Precision helps generate more accurate and contextually correct answers by ensuring that the retrieved documents are primarily relevant.
- Model Optimization and Balancing: Alongside Context Recall, Context Precision helps fine-tune RAG models’ retrieval components. A balance between Context Recall and Precision is often sought for optimal performance.
from ragas import evaluate
from ragas.metrics import context_recall, context_precision
wb_result = evaluate(wb_dataset, metrics=[context_precision, context_recall])
selenium_result = evaluate(selenium_dataset, metrics=[context_precision, context_recall])
newsurl_result = evaluate(newsurl_dataset, metrics=[context_precision, context_recall])
Interpretation of Results
I’m not gonna lie: I am pretty surprised by the results. I was expecting to see the NewsURLLoader win across all metrics.
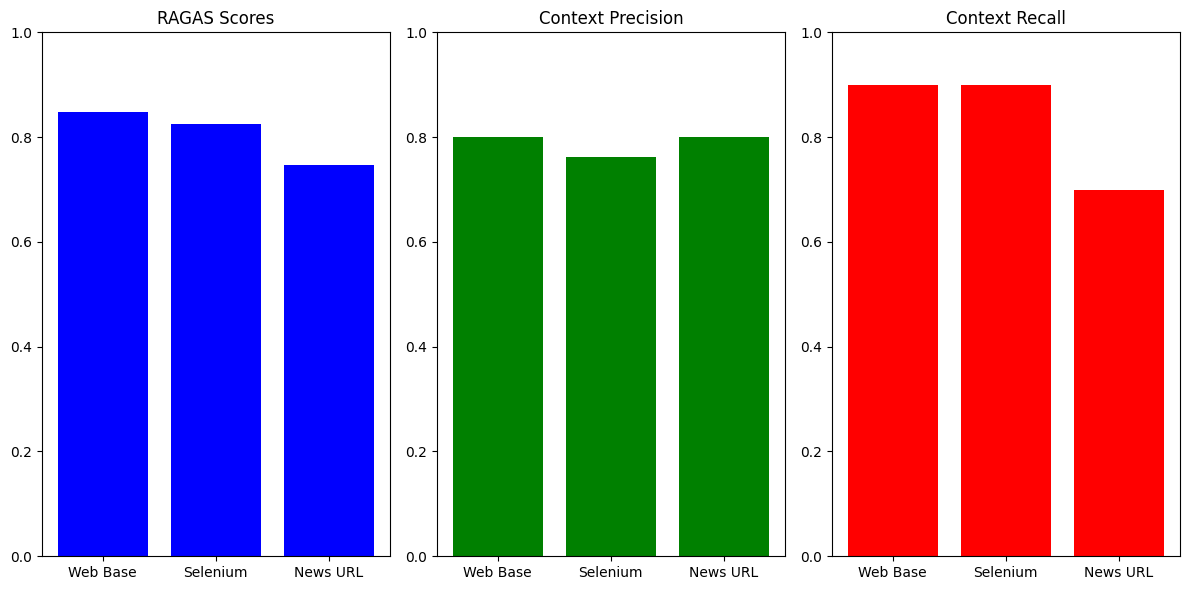
Web Base Loader’s Superiority: The Web Base loader has the highest RAGAS score, indicating it’s the most effective overall in Retrieval Augmented Generation. Its high context precision and recall suggest it’s adept at retrieving relevant documents without missing many important ones.
Selenium Loader’s Balanced Performance: The Selenium loader shows a slightly lower RAGAS score but maintains a high context recall, equal to the Web Base loader. Its context precision is lower, though, which might suggest it retrieves more documents, but a slightly larger proportion of them are less relevant.
News URL Loader’s Lower Recall: While matching the Web Base loader in precision, the News URL loader falls behind in context recall and RAGAS score. This could indicate that while it’s good at finding relevant documents, it misses many relevant ones compared to the other loaders.
The observation that the NewsURLLoader extracts cleaner text yet performs lower in terms of the overall RAGAS score and context recall is quite intriguing and points to a few potential reasons:
Precision vs. Quality of Content: While the NewsURLLoader might be retrieving cleaner, more precise text, the effectiveness of a retrieval system in a Retrieval-Augmented Generation (RAG) setup is not solely determined by text cleanliness. The key is to retrieve content that is not just clean but also highly relevant and comprehensive in answering the query. If the cleaner text is less comprehensive or slightly off-topic, it might contribute less effectively to the answer generation, impacting the RAGAS score.
Nature of Source Documents: The NewsURLLoader might be optimized for extracting text from news websites, which often have cleaner and more structured content. However, if the content from these sources is less diverse and rich in answering a wide array of queries compared to other sources, it might lead to lower recall and RAGAS scores.
Context Recall Challenge: The lower context recall score suggests that the NewsURLLoader, despite retrieving high-quality text, might be missing out on a significant number of relevant documents. This could be due to stricter or more conservative retrieval algorithms, which prefer precision over the breadth of retrieval.
Matching Query with Context: The effectiveness of a RAG system also depends on how well the retrieved context aligns with the nuances of the query. If the NewsURLLoader’s algorithm is tuned to favour text cleanliness over nuanced matching, it might retrieve text that, while clean, is not as aligned with the specific needs of the query.
Integration with the RAG System: The overall architecture and integration of the NewsURLLoader with the RAG system could also play a role. Even if the text is cleaner, other aspects, like how the loader interfaces with the language model, the handling of metadata, and the overall synergy with the RAG process, are crucial.
