Thousands of data scientists use Comet panels, histograms, and reports to visualize data from experiments every day. While we’re proud of those tools and excited to see teams using them, we’ve consistently heard one piece of feedback, particularly from computer vision researchers:
Visualization is still painful in exploratory data analysis.
Over the last several months, the Comet research team has been working on addressing this problem, developing a tool for visualizing multimedia data that is performant, intuitive, and interoperable. Today, we are excited to open source this library, Kangas, and release it for its initial beta.
Introducing Kangas V1: Open Source EDA for Computer Vision
In these early days of Kangas (like “kangaroos” without the “roo”), we’ve set out to solve three specific problems in exploratory data analysis:
1. Large datasets are painful to process. While pandas is a fantastic tool, it stores its DataFrames in memory, crippling performance as your dataset grows. Supplementing with 3rd party tools, like Dask, works in a complex pipeline ahead of production, but slows you down in research.
This is where we started with Kangas. We thought “What if instead of storing a DataFrame-like object in memory, we stored it in an actual database?” Which then transformed into “What if DataFrames were actual databases?”
The base class of Kangas is the DataGrid, which you define using a familiar Python syntax:
from kangas import DataGrid dg = DataGrid(name="Images", columns=["Image", "Score"]) dg.append([image_1, score_1]) dg.show()
Note: There are actually several different ways of constructing a DataGrid. For more, see here.
A Kangas DataGrid is an actual SQLite database, giving it the ability to store vast amounts of data and perform complex queries quickly. It also allows DataGrids to be saved and distributed, even served remotely.
2. Visualizing data takes hours. To explore a CV dataset, you need to see the images themselves, as well as the relevant metadata and transformations. You need to be able to compare images across views, chart aggregate statistics, and ideally, do it all inside a single UI. Your typical mishmash of libraries results in output best described as “functional,” not beautiful.
Visualizations in Kangas needed to be easy, fast, and slick. Instead of relying on a Python library, we built the Kangas UI as an actual web application. Server side rendering (using React Server Components), allows Kangas to render visualizations quickly while performing a variety of queries, including filtering, sorting, grouping, and reordering columns.
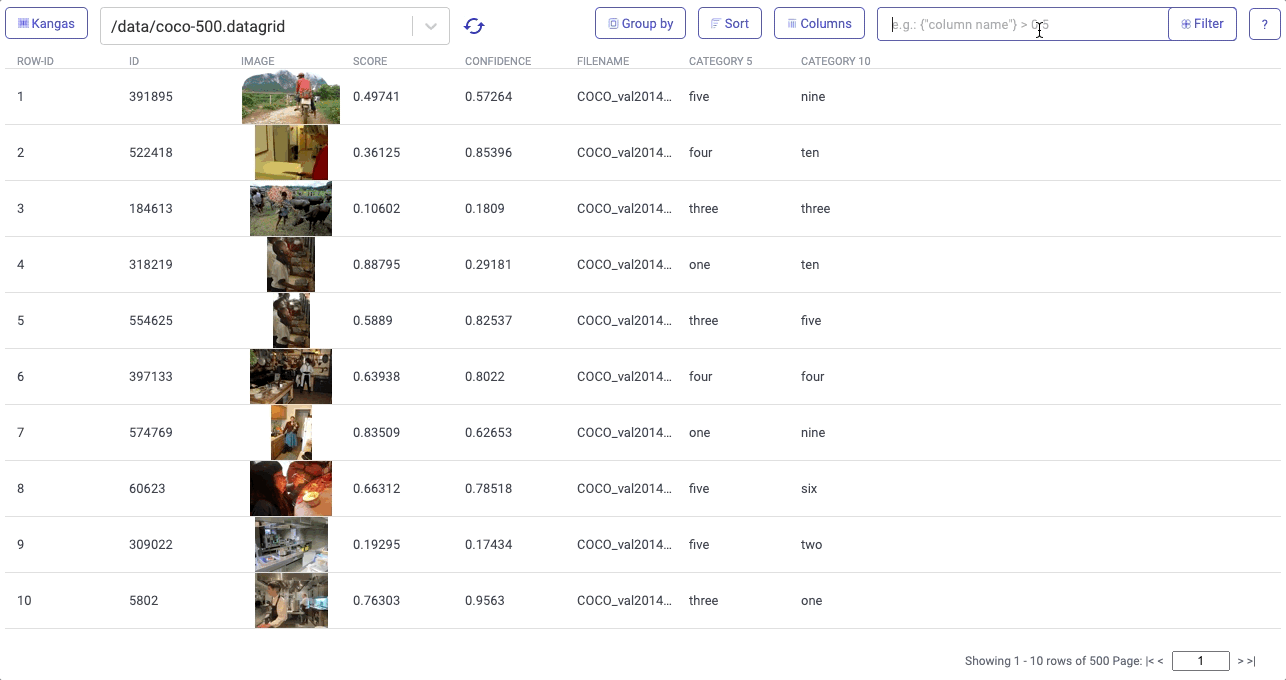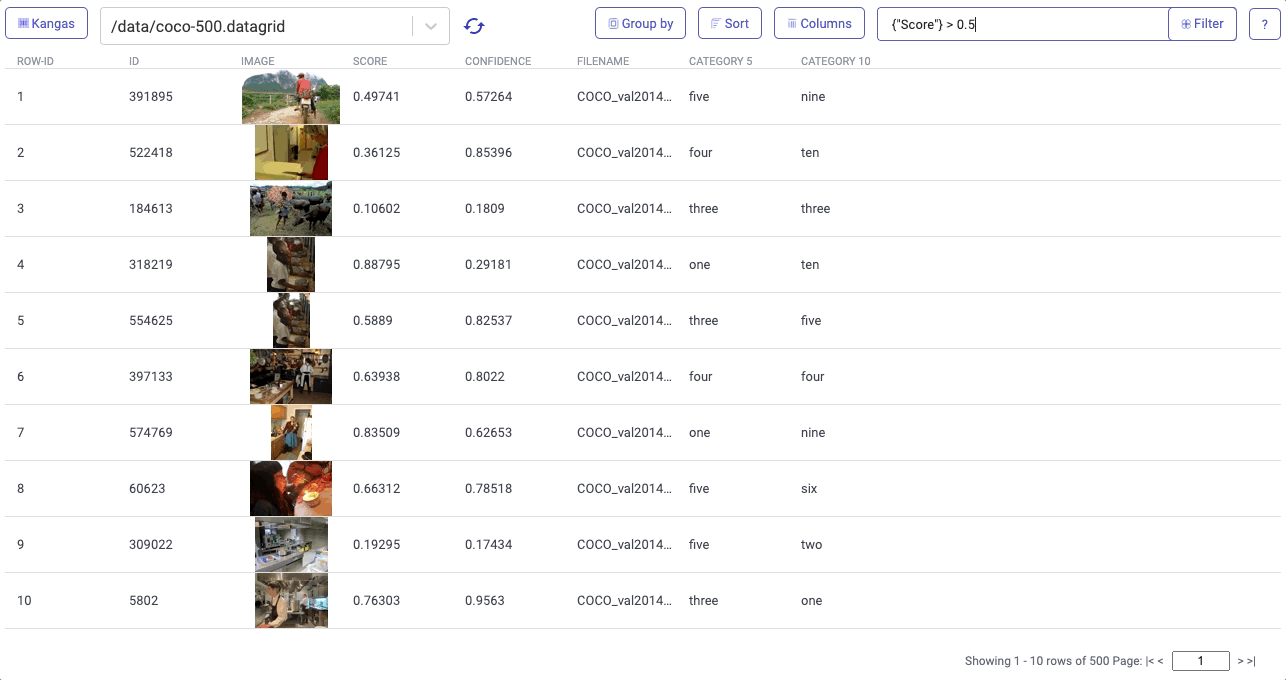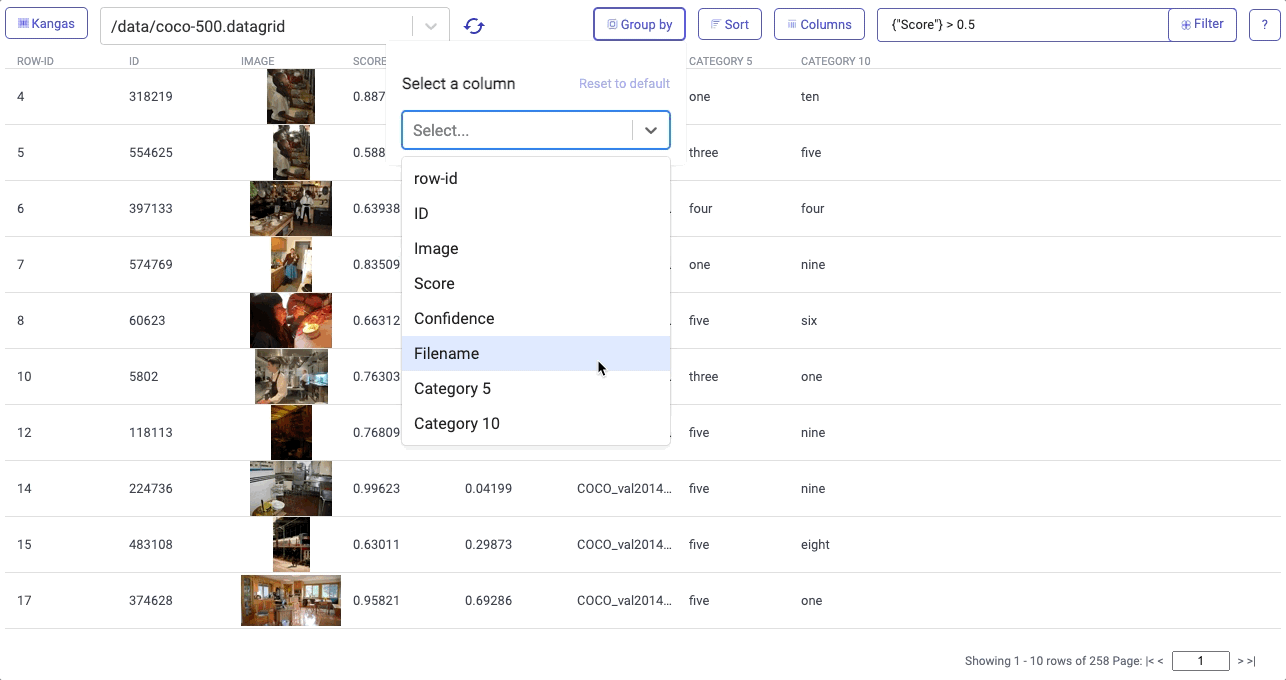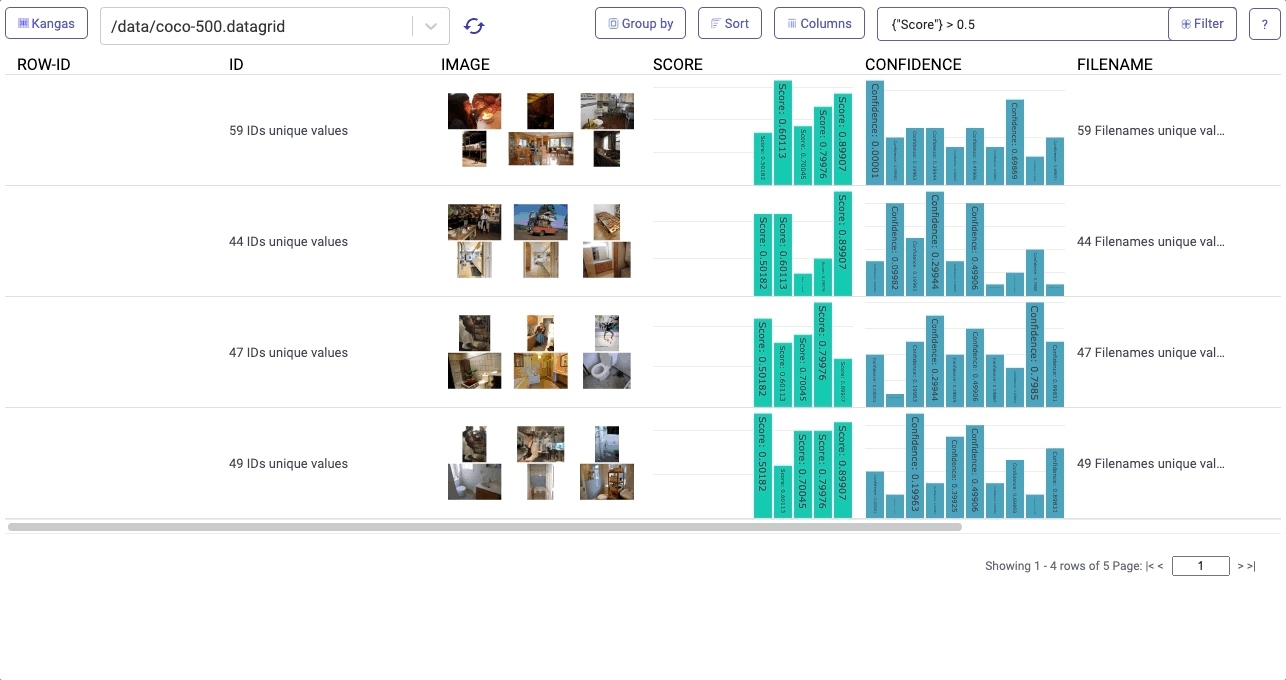
On top of this, Kangas provides built-in metadata parsing for things like labels, scores, and bounding boxes:
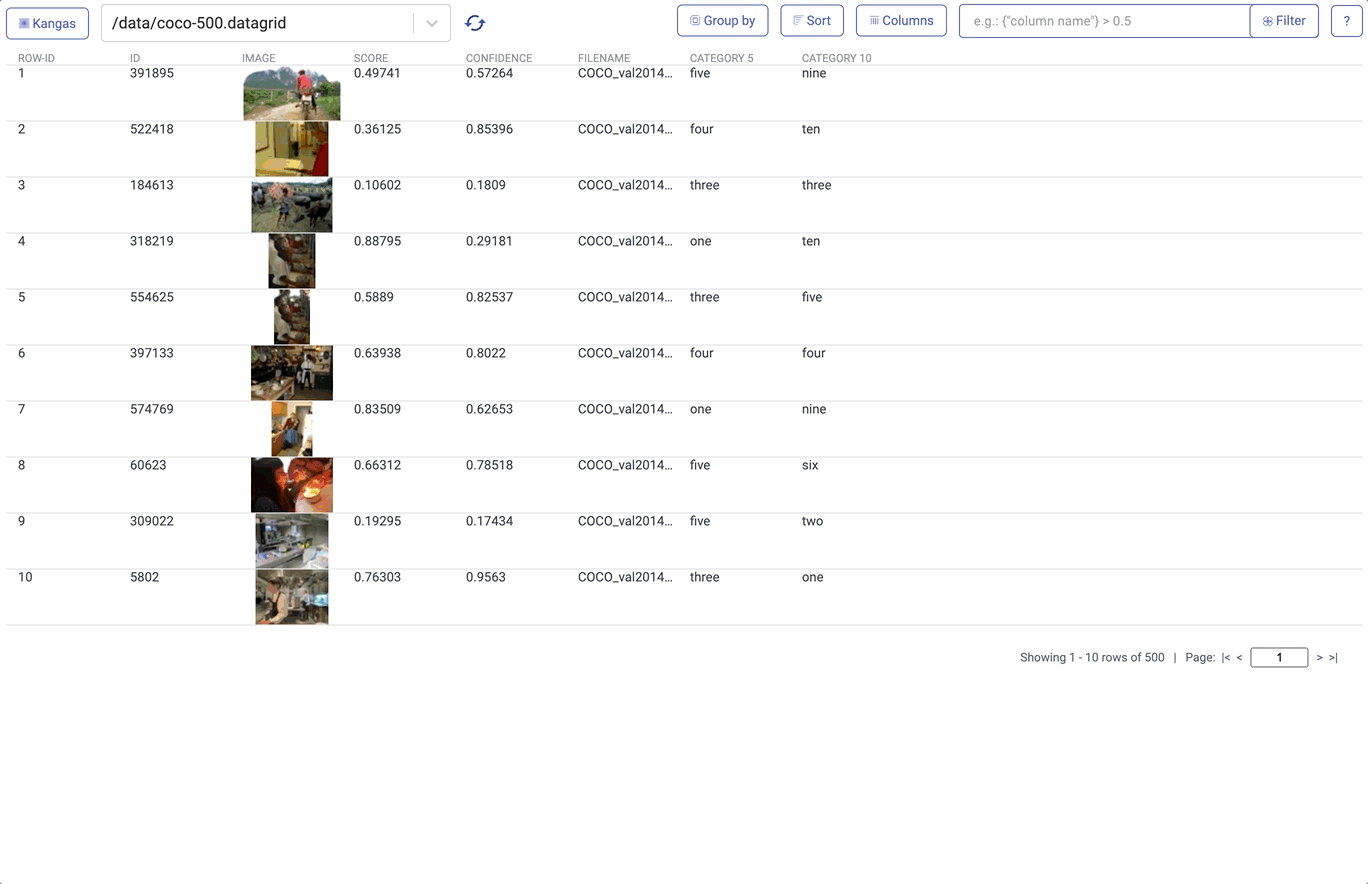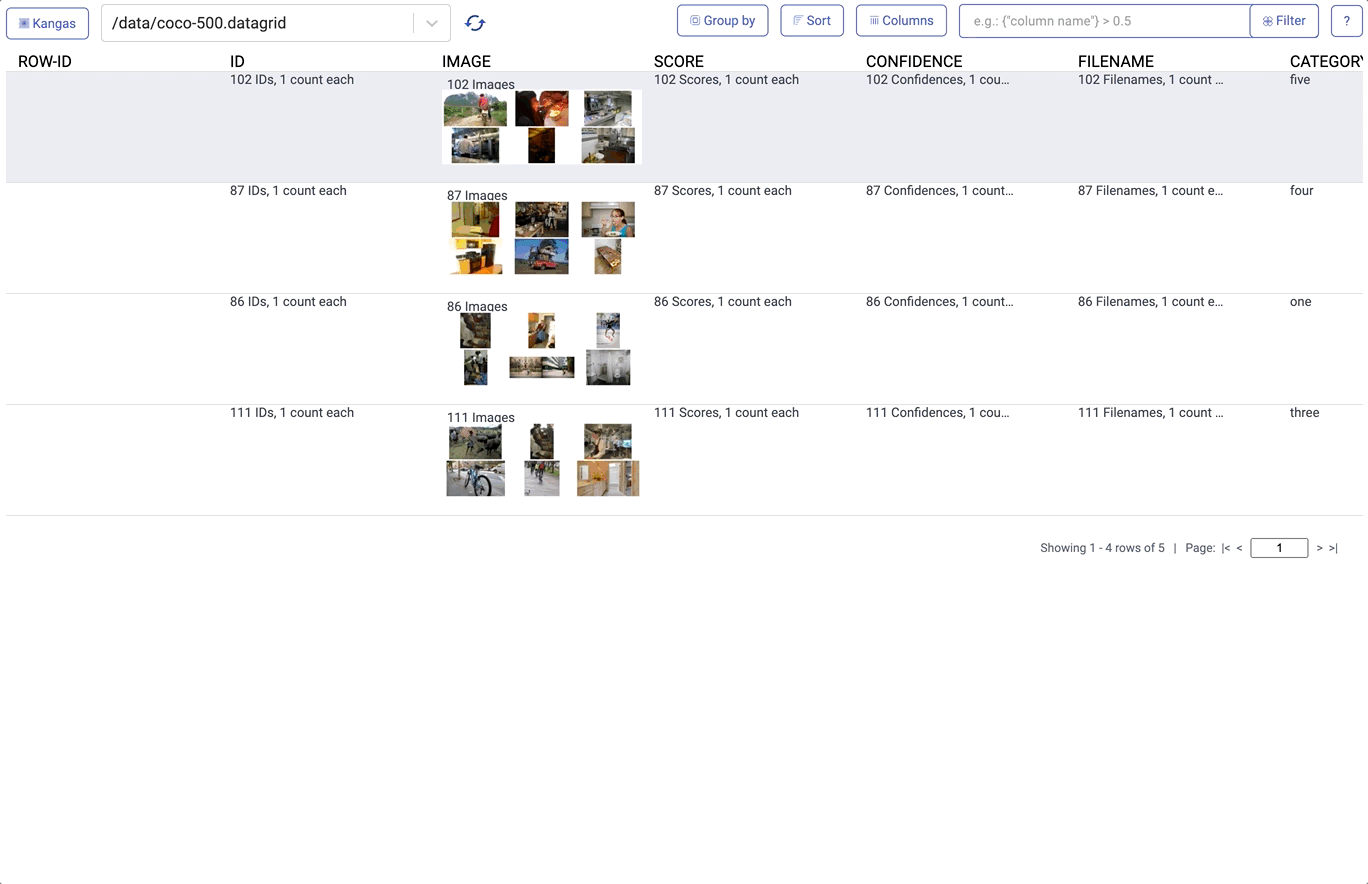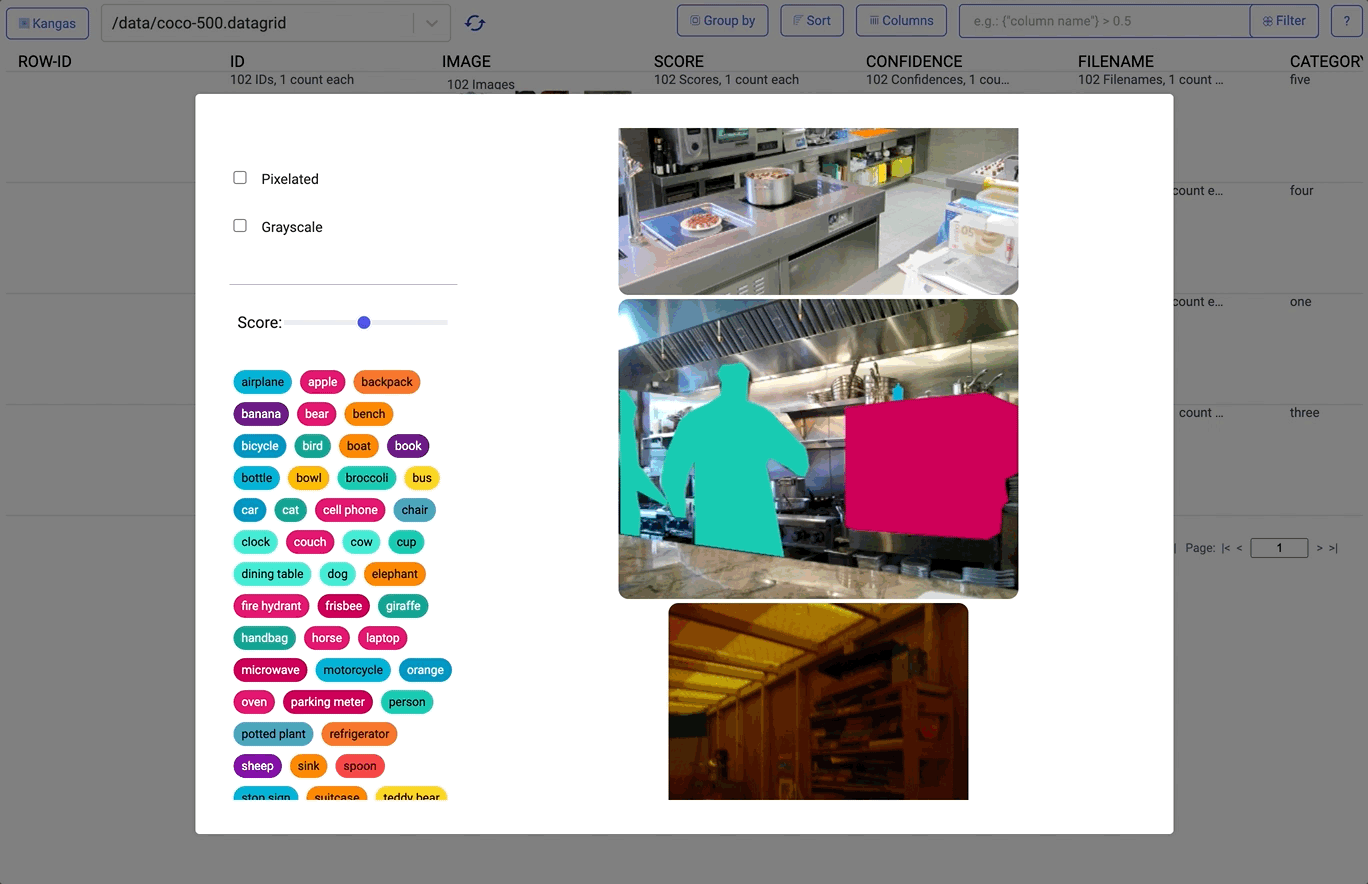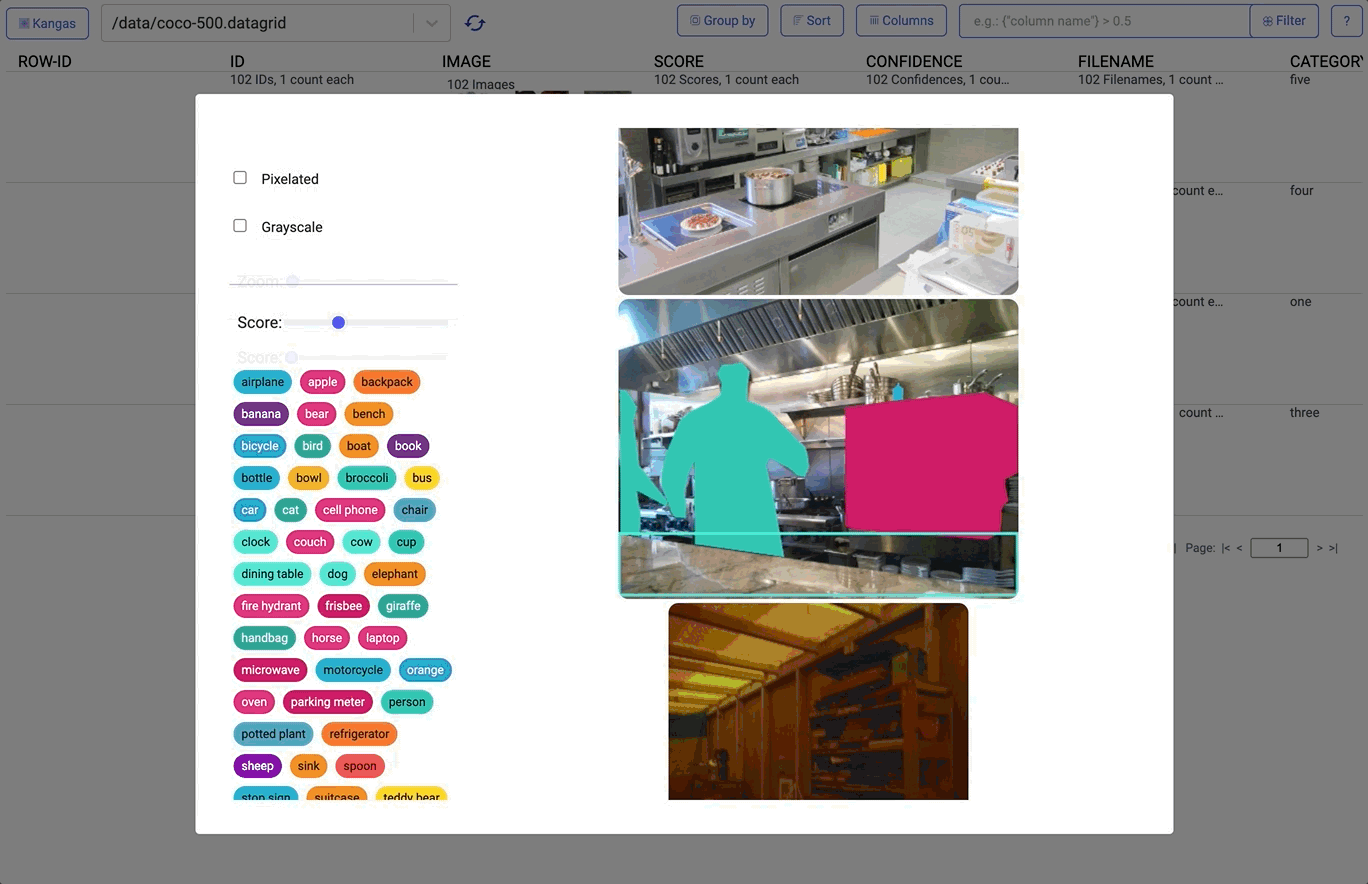
3. EDA solutions are rarely interoperable. One of the challenges of EDA is that data is often messy and unpredictable. Your colleague’s “eccentric” preference in tooling often changes your data in the least intuitive way. In an ideal world, you wouldn’t need to change your workflow to contend with this variability—it would all just work. To achieve this in Kangas, we had to do several things.
First, we wanted to make sure that any type of data could be loaded into Kangas. To this end, Kangas is largely unopinionated about what you store inside a DataGrid. Kangas additionally provides several constructor methods for ingesting data from different sources, including pandas DataFrames, CSV files, and existing DataGrids.
import kangas as kg
# Load an existing DataGrid
dg = kg.read_datagrid("https://github.com/caleb-kaiser/kangas_examples/raw/master/coco-500.datagrid")
# Build a DataGrid from a CSV
dg = kg.read_csv("/path/to/your.csv")
# Build a DataGrid from a Pandas DataFrame
dg = kg.read_dataframe(your_dataframe)
# Construct a DataGrid manually
dg = kg.DataGrid(name="Example 1", columns=["Category", "Loss", "Fitness", "Timestamp"])
Secondly, we wanted to be sure that Kangas could run in any environment without major setup. Once you’ve run `pip install kangas`, you can run it as a standalone app on your local machine, from within a notebook environment, or even deployed on its own server (as we’ve done at kangas.comet.com.)
Finally, the fact that Kangas is open source means it is by definition interoperable. If your particular needs are so specific and extreme that nothing on the Kangas roadmap will ever satisfy them, you are able to fork the repo and implement whatever you need. And if you do that, please let us know! We’d love to take a look.
What’s on the roadmap for Kangas?
It’s still early days for Kangas. Right now, there are only a handful of beta users testing it, and large portions of the codebase are still under active development. With that in mind, what happens next is largely up to you. Kangas is and always will be a free and open source project, and what we choose to prioritize over the next months and years will come down to what members of the community want the most.
If you have time to spare and a burning need for better exploratory data analysis, consider stopping by the Kangas repo and taking it for a spin. We’re open to community contributions of all kinds, and if you star/follow the repository, you’ll get updated whenever there is a new major release.
