Investing in AI: Unlocking Profitable Machine Learning with Experiment Management
This post was originally published as a sponsored post by Dell Technologies and Intel on CIO.com.
We live in an age of rapid AI innovation and progress. Yet even as academics and researchers make astonishing advancements, demonstrating real business value and positive return on investment is challenging. Developing cutting edge AI applications based on machine learning models integrated with existing business software is a common challenge. This article discusses a few of the core pain points and strategies to address them.
The first challenge most organizations encounter is the increased complexity of preparing data and dataset management. Companies may be sitting on troves of valuable data that is unstructured and disorganized and therefore unusable for machine learning modeling. The second common challenge is a lack of infrastructure and tooling necessary for data scientists to record data transformation and model development while moving quickly through alternative designs. Machine learning is an inherently iterative science (as opposed to the determinism of software engineering). Without tools that natively support design iteration, teams struggle to advance their research. The final pain point is productionization: even if a team develops a good model, how do they deploy it outside the lab in a business setting? Also, how do they monitor its performance and accuracy in production?
All of these problems together constitute an unfortunate truth: that for many enterprises, AI application development has become a DevOps challenge rather than a data science challenge. Research Scientists with gleaming PhDs are often found wrestling with infrastructure, job schedulers and compute sources rather than building and training valuable models for their unique business cases.
Moving from DevOps to MLOps
Data science and machine learning model development need not drown in DevOps. Over the last several years, a wide range of tools have been introduced by everyone from startups to new divisions within large technology companies that are built specifically to address these core challenges. (Disclaimer: I work as a Data Scientist at one of these companies, Comet).These products and technologies have introduced to the market the nascent notions of ‘ML best practices’ and ‘ML tooling.’ Adoption of the right tooling can be the difference between driving a successful machine learning organization and trudging through a broken DevOps quagmire in perpetuity.
In remainder of this post, I will highlight three broad decisions that AI leaders can make to enable their teams to focus on what they do best. I will focus on ways to address the second pain point mentioned above: experimentation and research, ignoring the very real challenges around data and productionization. At Comet we work with some of the biggest Fortune 100 companies in the world, and I can say from direct experience that these tips can immediately speed up research cycles, enable your team to build better models, and drive real business value from your investments in AI.
Invest in a Digital Laboratory for your Research Team
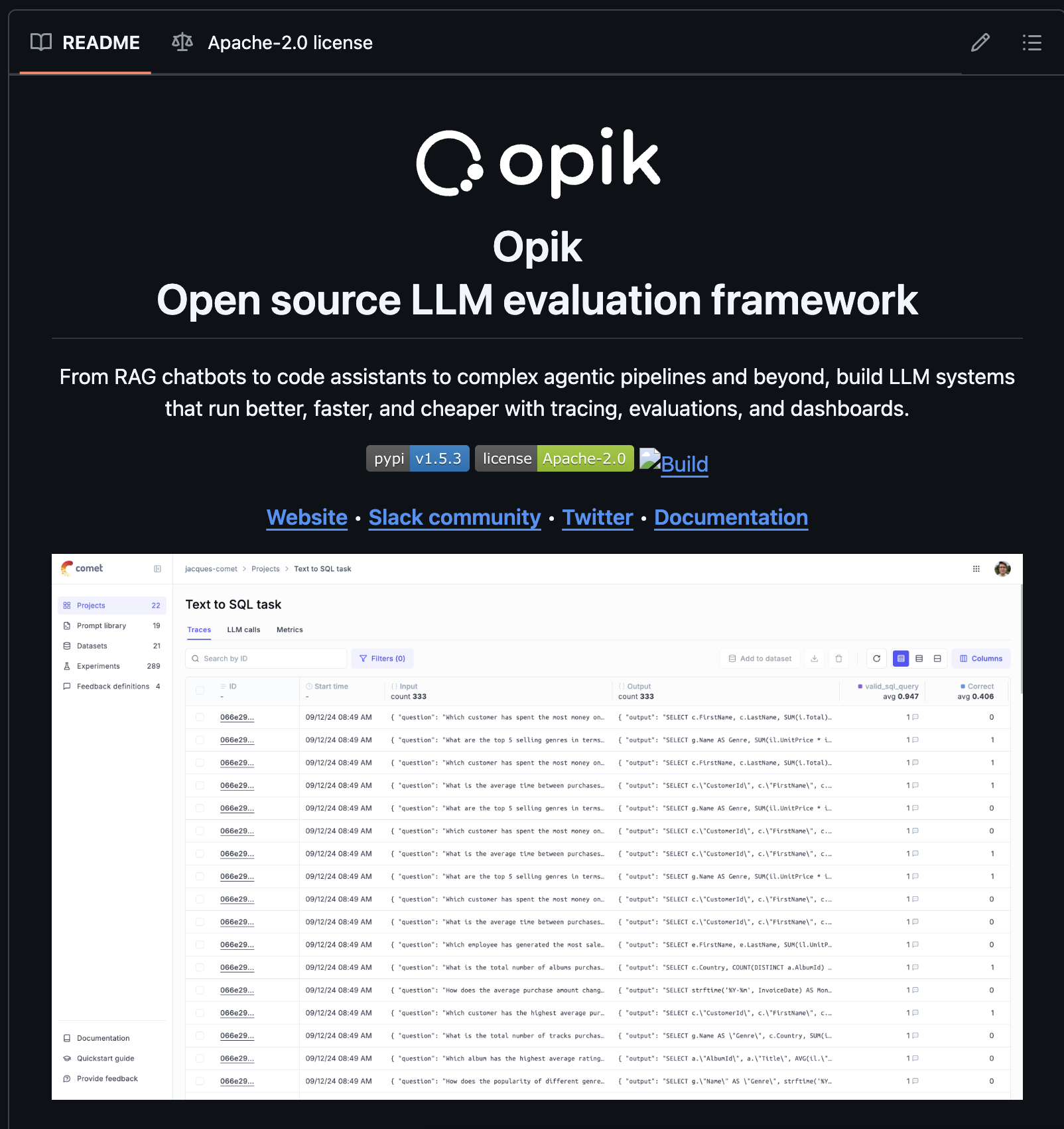
Biologists, chemists and many other scientists benefit from more than just laboratories to do their best research. Rooms full of beakers, computers, and lab rats alone don’t allow them to record their work, visualize results and iterate quickly onto the next avenue of research. Their labs are also equipped with recording and documentation tools. In order to provide a digital laboratory for the data scientist, the paradigm of work is shifting from the modularity and sub-tasking of software engineering to logging, visualization and iteration. New tools, both open source and paid, treat every script executed by an engineer or data scientist as an ‘Experiment,’ with artifacts, metadata, dataset samples, visualizations, models, hyperparameters and more, logged and stored for future comparison. Data Science teams need to know (and be able to recall) the history of where they’ve been to decide where to go next.
Standardize the Experiment of the Enterprise
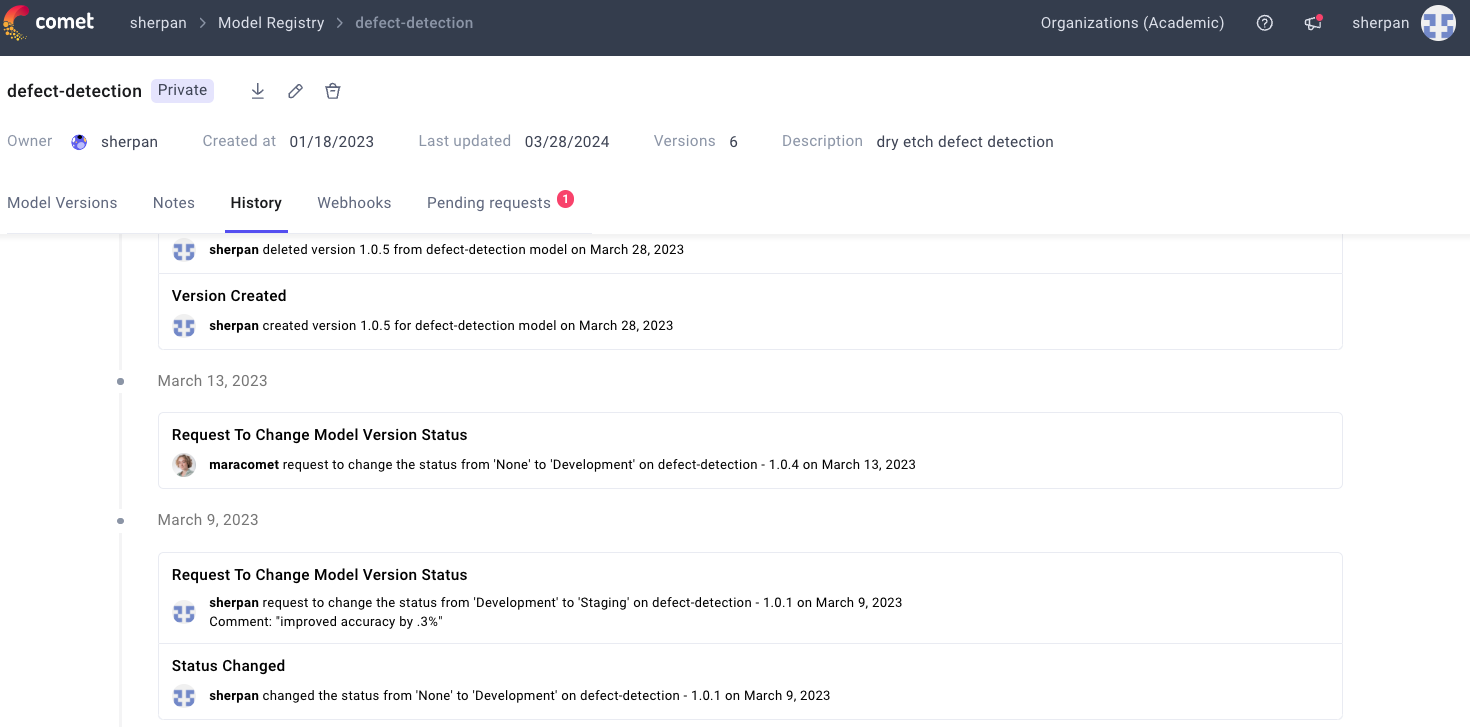
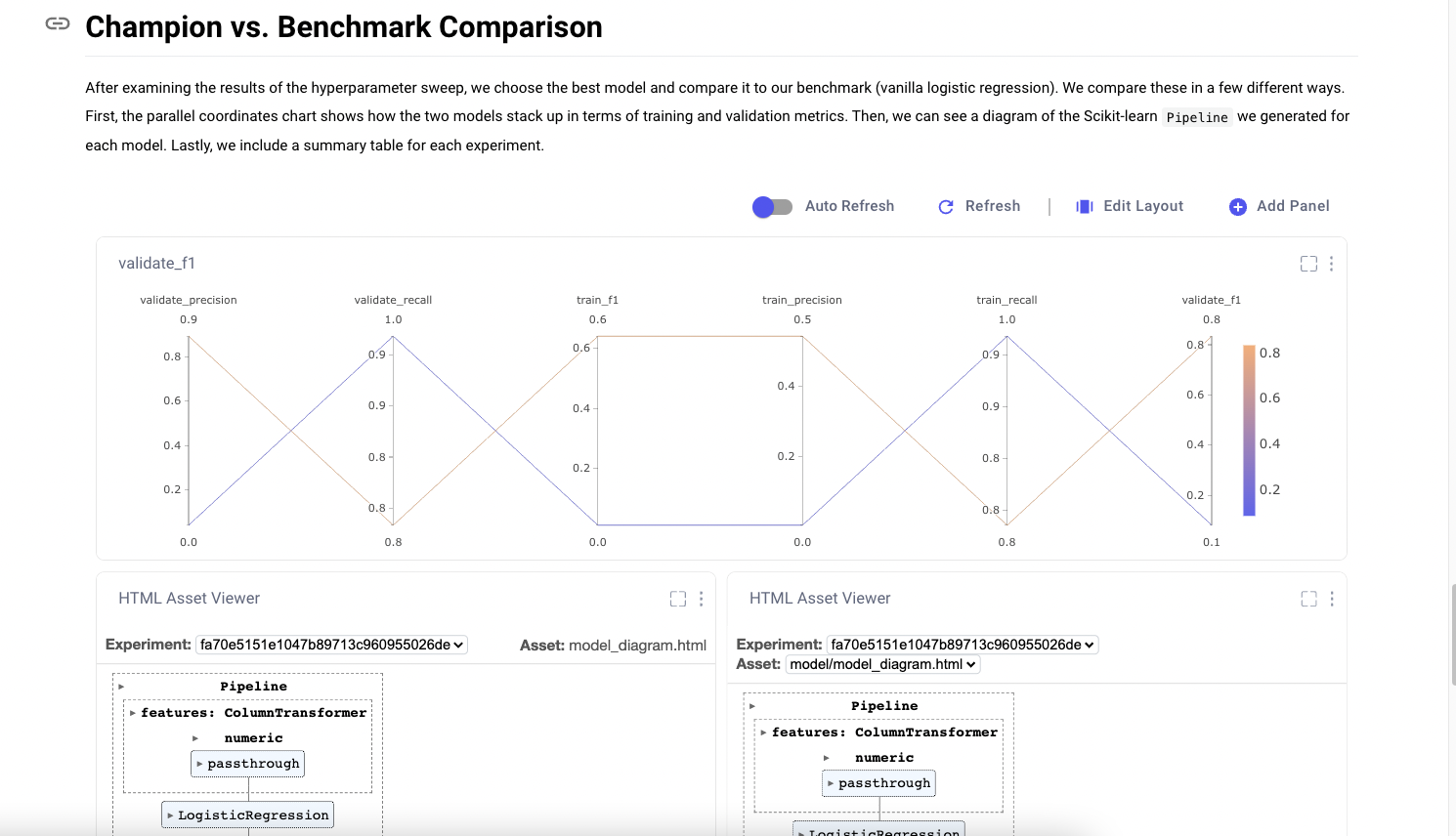
Building an expensive laboratory won’t help much if your researchers aren’t versed in how to structure, run, and keep track of experiments. Data Science leaders must ensure their teams can manage a standard set of artifacts, metrics, datasets, hyperparameters, compute sources, and much more that are recorded for each of their experiments. This has beneficial outcomes in two senses. First, the inculcation of these best practices will drive home the need for your data scientists to be focused on much more than their target metric, unlocking holistic research and creative approaches to modeling. Second, a standard experiment format enables comparative analysis of experiments over time, something good data scientists cannot afford to do without.
Adopt an ML-friendly Workflow practice
Unlike software development, where products and features can be broken apart and modularized into subtasks with predictable delivery dates and action items, data scientists don’t know exactly what they’re looking for when they start building a model. Their workflow practices should reflect that. During a keynote address at Amazon re:MARS in 2019, Andrew Ng shared that his team at Landing.ai does one-day sprints: write code and build models during the day, run experiments overnight, come back the next day to analyze results and build new models. Teams looking to minimize time to market for their models should think about adopting workflow schedules that hew to the nature of a data scientist’s work.
Conclusion
The tips in this article taken together can be summarized succinctly: data science is not software engineering, so act and invest accordingly. Accepting the iterative, incremental and uncertain nature of your data science team’s projects, and investing in tools to support them, will enable your company, research lab or startup to make good on the seemingly limitless promise of AI. Translating this into business value may be easier than you think.
Learn More
To learn more about experimental machine learning, management and adopting a digital laboratory for your research team, check out this whitepaper co-written by Comet and Dell EMC.
Thanks to Phil Hummel for his review and edits to improve the blog.
Want to stay in the loop? Subscribe to the Comet Newsletter for weekly insights and perspective on the latest ML news, projects, and more.
Related Articles