Introducing Comet MPM: Model Production Monitoring
For many of us, it’s already a struggle to take a seemingly successful ML model live, but deployment is only half the battle. There are factors we can’t foresee that make our “best” models fall short of expectations. Maybe we haven’t seen what production data looks like or our model needs to be updated more frequently than we expected. Regardless of reason, it’s not enough to track hyperparameters and metrics, we also have to monitor how our models work after they’ve been deployed to production.
Without tools to understand how your model is running in a production environment, it can be difficult to compare to expected model results – much less be able to iterate on those models after they’ve hit production.
That’s where production model monitoring comes in. It’s the starting point for understanding how your production models are performing in real time, which enables you to do things like check for accuracy drift, the phenomena of model accuracy slowly drifting away from expected results.
That’s why we’re excited to announce Comet MPM (Model Production Monitoring) – a new product that will enable you to get visibility into your model performance in real time.
What is Comet MPM?
As data scientists, our work doesn’t stop when you’ve built and chosen some candidate models. Active production models deserve the same care and attention, because machine learning projects can fail at any step of each model’s life cycle.
This is where Comet MPM comes in – it helps to answer questions like:
- What happens when we deploy those models?
- If something goes wrong, how do we debug our models and discover what’s causing it?
- And how do we move to an iterative process of constant improvement of our models?
Even if candidate models are successfully deployed to production, they can still struggle to meet business KPIs once they’re live. Models in production are a huge part of the ML development lifecycle and without production monitoring, most teams are missing out on a key step of the feedback loop to learn and iterate from. There is significant value to be gained by combining the knowledge of both training and production environments.
Why do you need production monitoring?
Data Skew
It’s not uncommon that after we train and deploy a model, we find that aspects of the data and environment tend to skew from what we initially expected. This can happen because of data dependencies, like our mode ingesting variables that are created by other systems. We could also have built a model with a feature not available in production. This can even happen if the distributions of the variables in our training data don’t match the live data’s distribution. This can be incredibly costly.
Model Staleness
We can end up with stale models when our environment shifts. This often happens when we must anticipate production data populations when we’ve trained models on historical data. It’s also possible that consumer behavior shifts drastically. This is a particularly common problem with recommender systems and is hard to detect without proper monitoring.
Negative Feedback Loops
In some cases we end up training models based on data collected in our production environment. Depending on the kind of model we’re building, we can accidentally create negative feedback loops that corrupt our training data quality. This ensures that subsequent models will perform poorly.
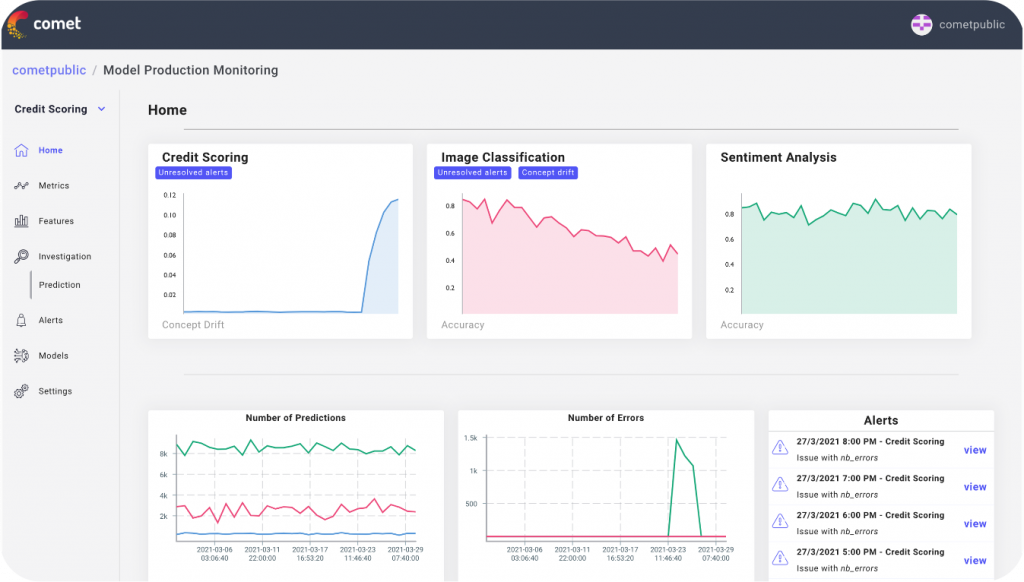
Comet MPM is currently available to existing Comet customers – let us know if you’d like a demo.
Related Articles