
In the machine learning (ML) and artificial intelligence (AI) domain, managing, tracking, and visualizing model training processes, especially at scale, is a significant challenge.
Union, an optimized and more performant version of the open-source solution Flyte, provides scalability, declarative infrastructure, and data lineage, allowing AI developers to iterate and productionize AI or ML workflows quickly. Comet’s machine learning platform enables seamless tracking, visualization, and management of model training processes, enhancing productivity and insight for data scientists and ML engineers.
Union and Comet are best-of-breed solutions that, when integrated, further enhance the user experience. Without an integration, users must manually set up and manage connectivity, which can be cumbersome and error-prone. Additionally, users would be challenged with manual tracking, which could hinder their overall productivity and effectiveness.
The new Comet Flyte plugin enables you to use Comet’s machine-learning platform to manage, track, and visualize models during training. In this blog post, you’ll learn how to use the Comet plugin on Union.
Flytekit’s Comet Plugin
In Union, data and compute are fundamental building blocks for developing all workflows. You can train models using machine learning or AI libraries such as PyTorch Lightning or LightGBM. Union is built on Flyte, which uses declarative orchestration to scale any computation easily.
We start with flytekit’s comet_ml_login decorator, which initializes Comet’s platform with your credentials during a Flyte execution. After decorating your function, the body consists of code you’ll find in Comet’s documentation:
from flytekit import task from flytekit.extras.accelerators import L4 from flytekitplugins.comet_ml import comet_ml_login comet_ml_secret = Secret(key="comet-ml-api-key") @task( container_image=image, secret_requests=[comet_ml_secret], requests=Resources(cpu="8", gpu="1"), accelerator=L4 ) @comet_ml_login( project_name=COMET_PROJECT, workspace=COMET_WORKSPACE, secret=comet_ml_secret, ) def train_lightning(dataset: FlyteDirectory, hidden_layer_size: int): from pytorch_lightning.loggers import CometLogger comet_logger = CometLogger() trainer = Trainer(..., logger=comet_logger) trainer.fit(...)
The above example uses Flyte’s declarative syntax to run a training script with PyTorch Lightning on a NVIDIA L4 GPU. With Comet’s Lightning integration, the training process is tracked and logged on Comet’s platform. The comet_ml_login decorator will start the run and configure Union’s UI to show a link to Comet:
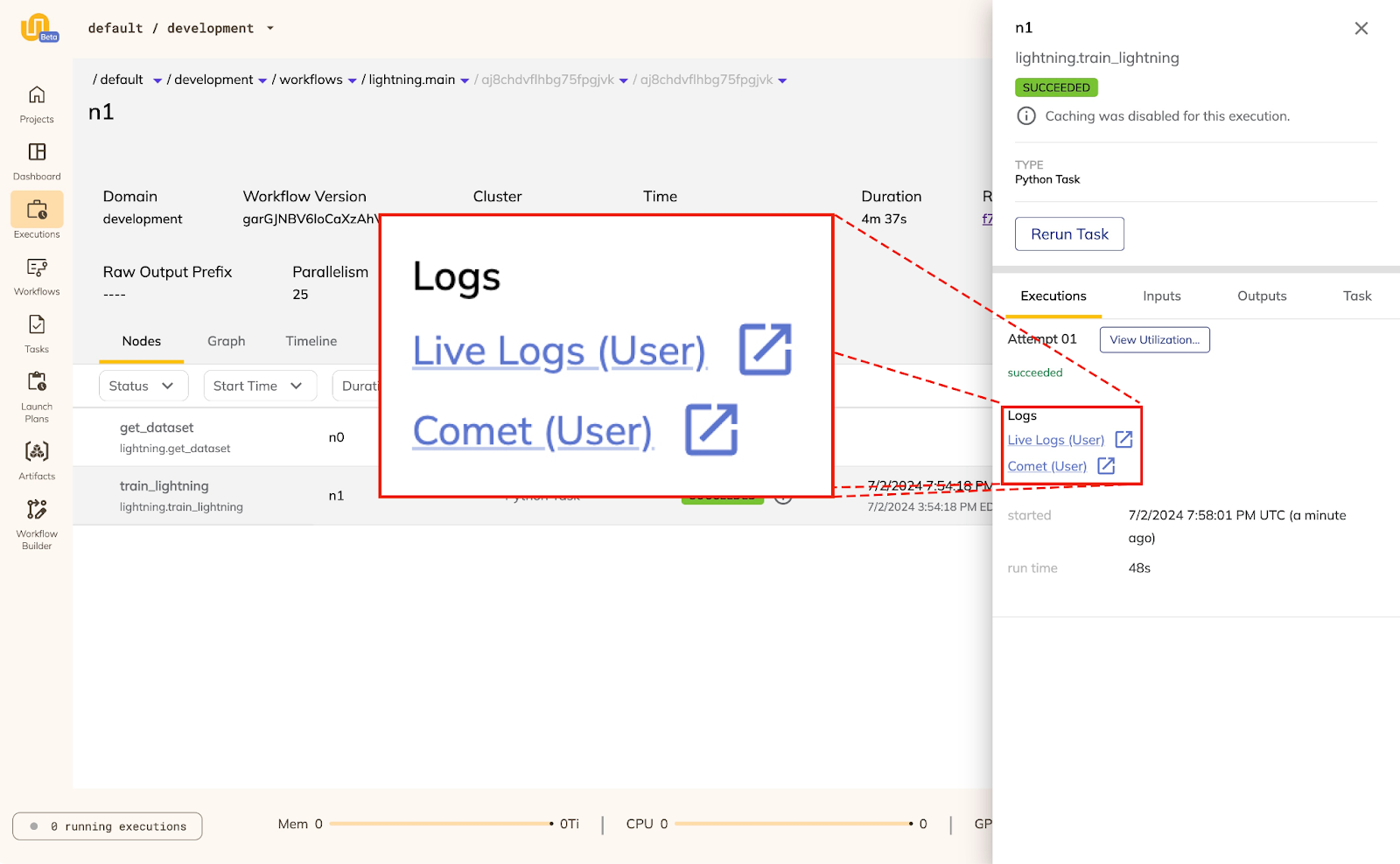
Elastic GPUs
With Flyte’s PyTorch Distributed plugin, flytekitplugins-kfpytorch, training jobs can scale to multiple nodes and GPUs with a simple configuration. Together with PyTorch Lightning, you can scale your training jobs:
from flytekitplugins.kfpytorch import Elastic @task( task_config=Elastic( nnodes=NUM_NODES, nproc_per_node=NUM_DEVICES, ), accelerator=A100, requests=Resources( mem="32Gi", cpu="48", gpu="2", ephemeral_storage="100Gi"), ... ) @comet_ml_login( project_name=COMET_PROJECT, workspace=COMET_WORKSPACE, secret=comet_ml_secret, ) def train_lightning(dataset: FlyteDirectory, hidden_layer_size: int): comet_logger = CometLogger() trainer = Trainer(..., logger=comet_logger)
With the comet_ml_login decorator, the scaled up training jobs are tracked on Comet’s platform.
Scaling with Dynamic Workflows
With Flyte’s dynamic workflows, you can quickly launch multiple experiments and track them all on Comet. In this example, you see how to use Flyte’s declarative infrastructure to train multiple models:
@task(...) @comet_ml_login( project_name=COMET_PROJECT, workspace=COMET_WORKSPACE, secret=comet_ml_secret, ) def train_lightning_model(data: FlyteDirectory, hidden_layer_size: int): comet_logger = CometLogger() trainer = Trainer(..., logger=comet_logger) @dynamic(container_image=image) def main(hidden_layer_sizes: list[int]): dataset = get_dataset() for hidden_layer_size in hidden_layer_sizes: train_lightning_model( dataset=dataset, hidden_layer_size=hidden_layer_size)
In the Union UI, the workflow dynamically scales out to 5 GPU-powered tasks:
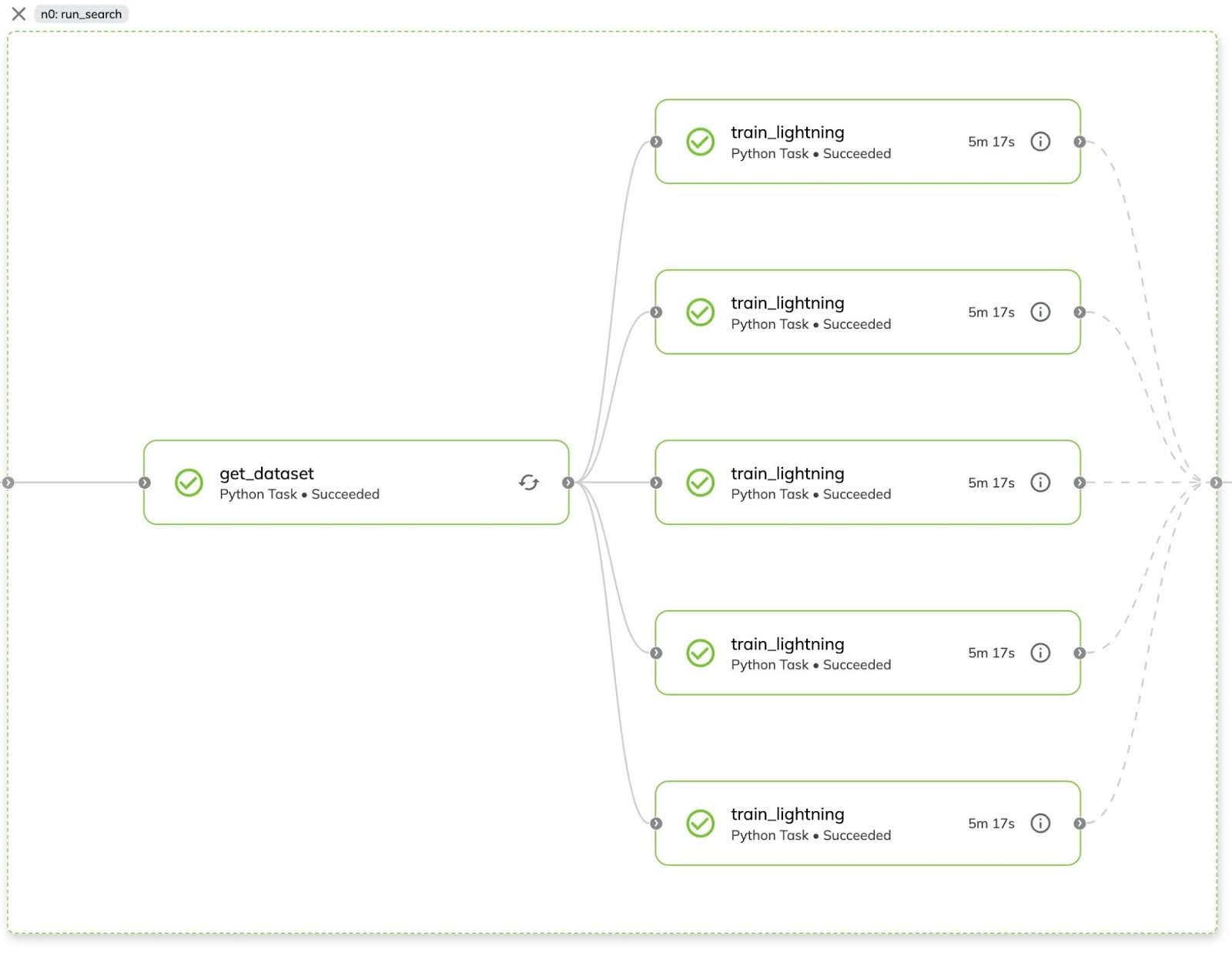
PyTorch Lightning’s CometLogger automatically logs the metrics, hyperparameters, and checkpoints during training. In Comet, you can compare the different runs and evaluate the model’s performance.
Conclusion
Union’s declarative infrastructure and scalable orchestration platform makes it simple to scale up your machine learning or AI workflows and put them in production. With flytekit’s Comet plugin, you can easily track experiments, visualize results, and debug models. To use the plugin, install it with pip install flytekitplugins-comet-ml.
Union and Comet offer powerful features independently. This integration significantly enhances their combined capabilities, reducing manual effort, improving efficiency, and ensuring more comprehensive tracking and visualization of AI workflows.
To learn more about Union, contact us at www.union.ai/demo.
To learn more about Comet, contact us at https://www.comet.com/site/about-us/contact-us.

