In this blog post we will leverage Comet’s Model Production Monitoring tool to monitor one of the most popular types of model deployed today: fraud detection. Not only will we monitor our for performance, but we will also inspect if our Model free from any bias!
One of the best ways to improve a machine learning model’s performance is to monitor it the moment it’s deployed to production. Models are trained rigorously on a training dataset. However, in the real world, models can start to infer on data which is different from the data it was trained on. This phenomenon is denoted as “model drift” and is a signal to a Data Scientist that their model needs to be re-trained.
Continuing to Serve a Drifted Model can have significant negative business and monetary impact. Machine Learning Models today are making recommendations, driving our cars, estimating loans, and detecting diseases. Given the growing responsibility of AI in our society, detecting Model Drift as soon as possible should be top of mind for every ML organization.
No Labels No Problem
Having access to ground truth labels isn’t a necessary requirement to start monitoring your models. In fact, most teams cite that it takes them weeks to get access labels for their Fraud Detection Models. In that amount of time it is possible your model would have already drifted. We’ll first cover strategies some strategies that will help team’s detect model drift as early as possible.
Observe Model Output Distribution
Fraud Detection Models are binary classification models that output whether a transaction should be flagged as fraud or not. Like other Anomaly Detection use cases, the distribution of the model’s output will skew heavily to “No fraud” rather than “Fraud”. Based on previous data, data scientists are aware of the “normal” range of frauds (ie, fraud happens 3–5% of the time). If a model starts predicting frauds at a more frequent rate or conversely a significantly less rate, it’s a sign for a ML team that their model might be starting to drift.
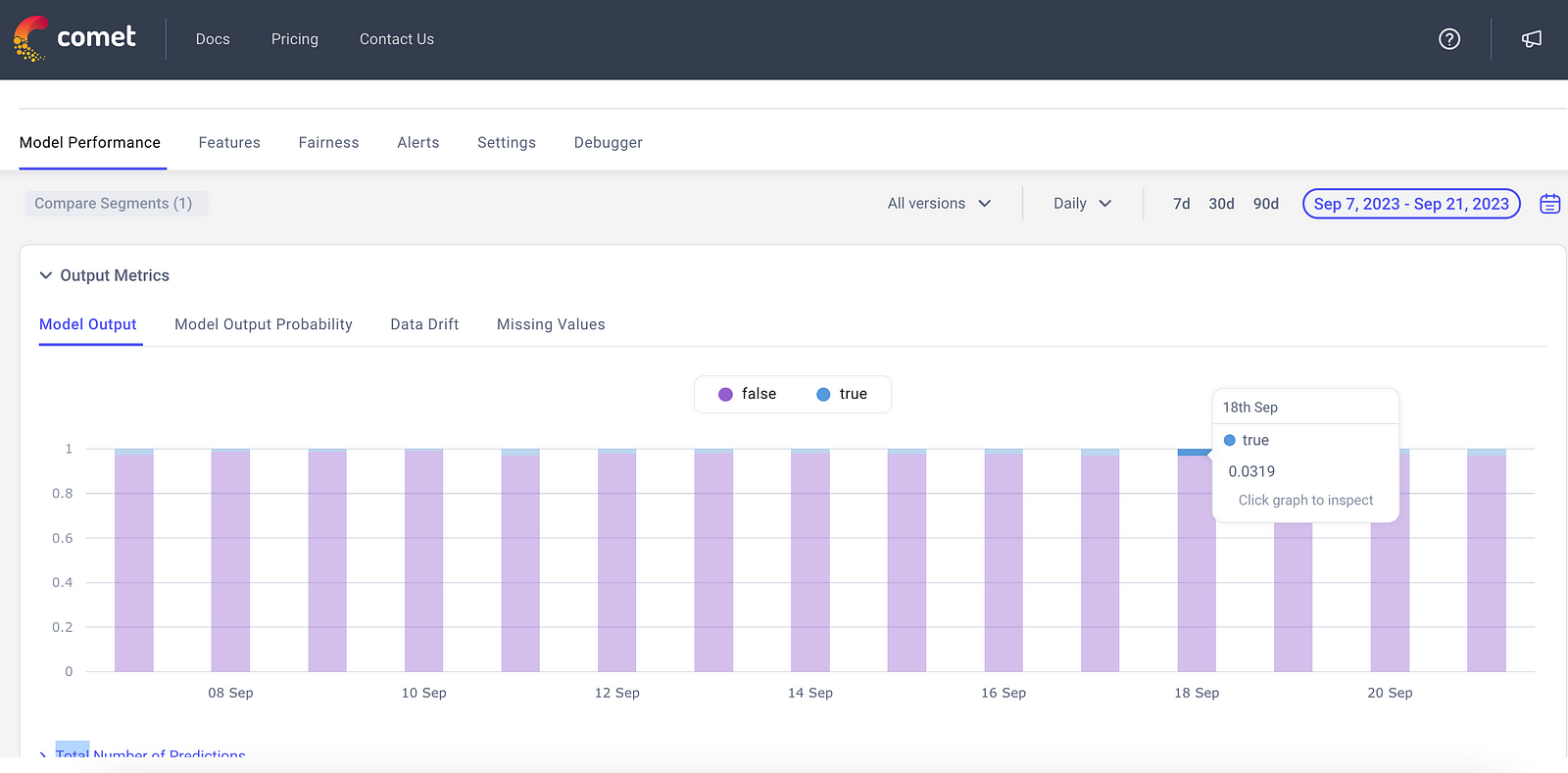
Track Input Feature Drift
Data drift refers to the phenomenon where the statistical properties of a dataset change over time in a way that can negatively impact the performance of machine learning models or data analytics. By tracking data drift on input features, ML teams can pinpoint exactly where and why a model is failing.
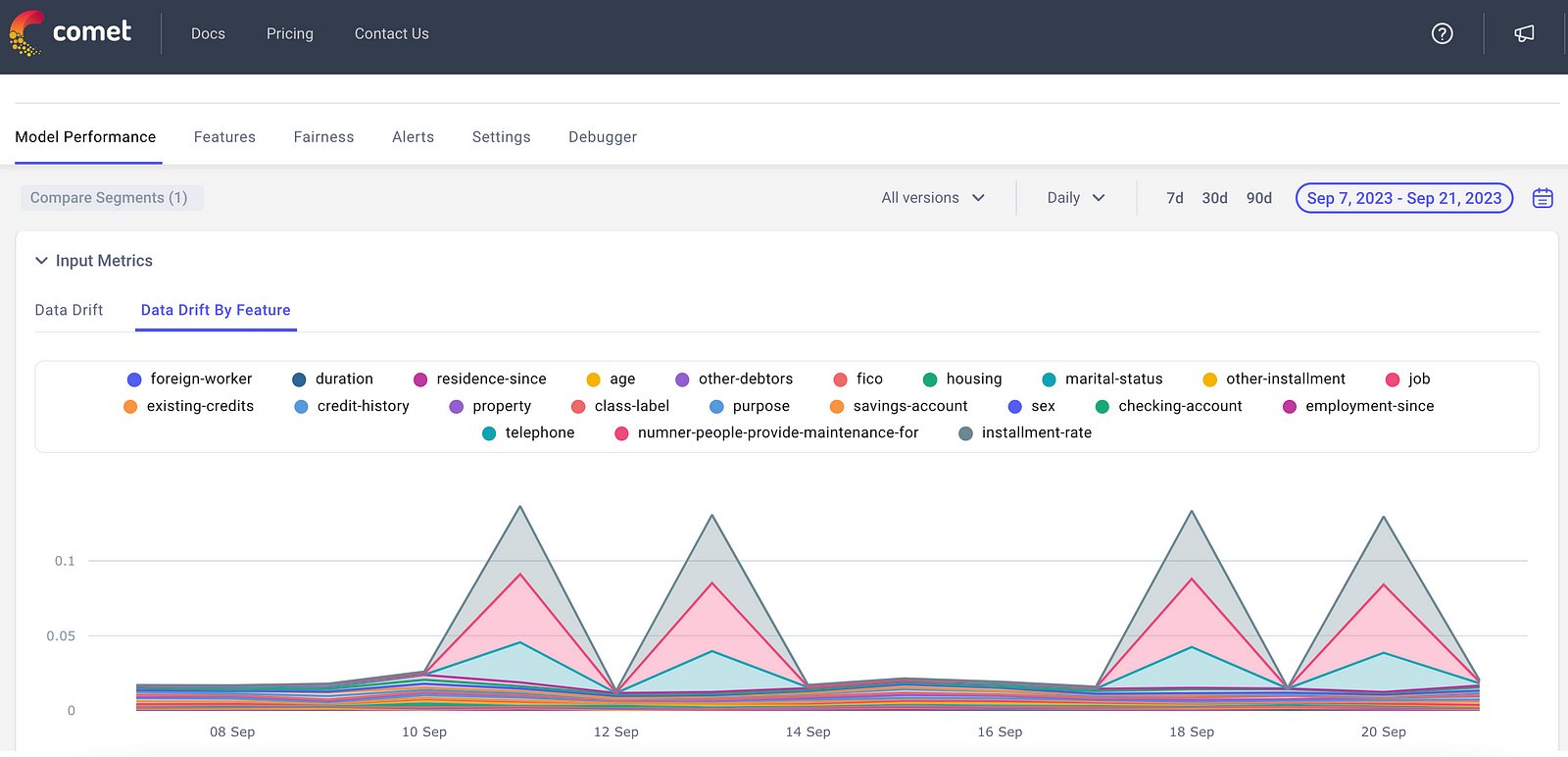
To calculate Input Feature Data Drift, teams need to align on which baseline distribution to calculate data drift from. One option is to use the the training dataset distribution as a reference. The other option is to a use prior input data your model saw in prediction at a specified time window.
Regulate Model Fairness
Model Fairness refers to the ethical and equitable treatment of individuals and groups by an AI or machine learning model. A fair model means that its predictions, decisions, or outcomes are not biased or discriminatory against any particular demographic group or characteristic, such as race, gender, age, or other sensitive attributes.
Engineers want to avoid scenarios in which their Model is disproportionally flagging fraud on a segment of their data. Practitioners quantify fairness by using a metric called disparate impact.
Disparate Impact = (% Positive Outcomes for Sensitive Group) / (% Positive Outcomes for Reference Group)
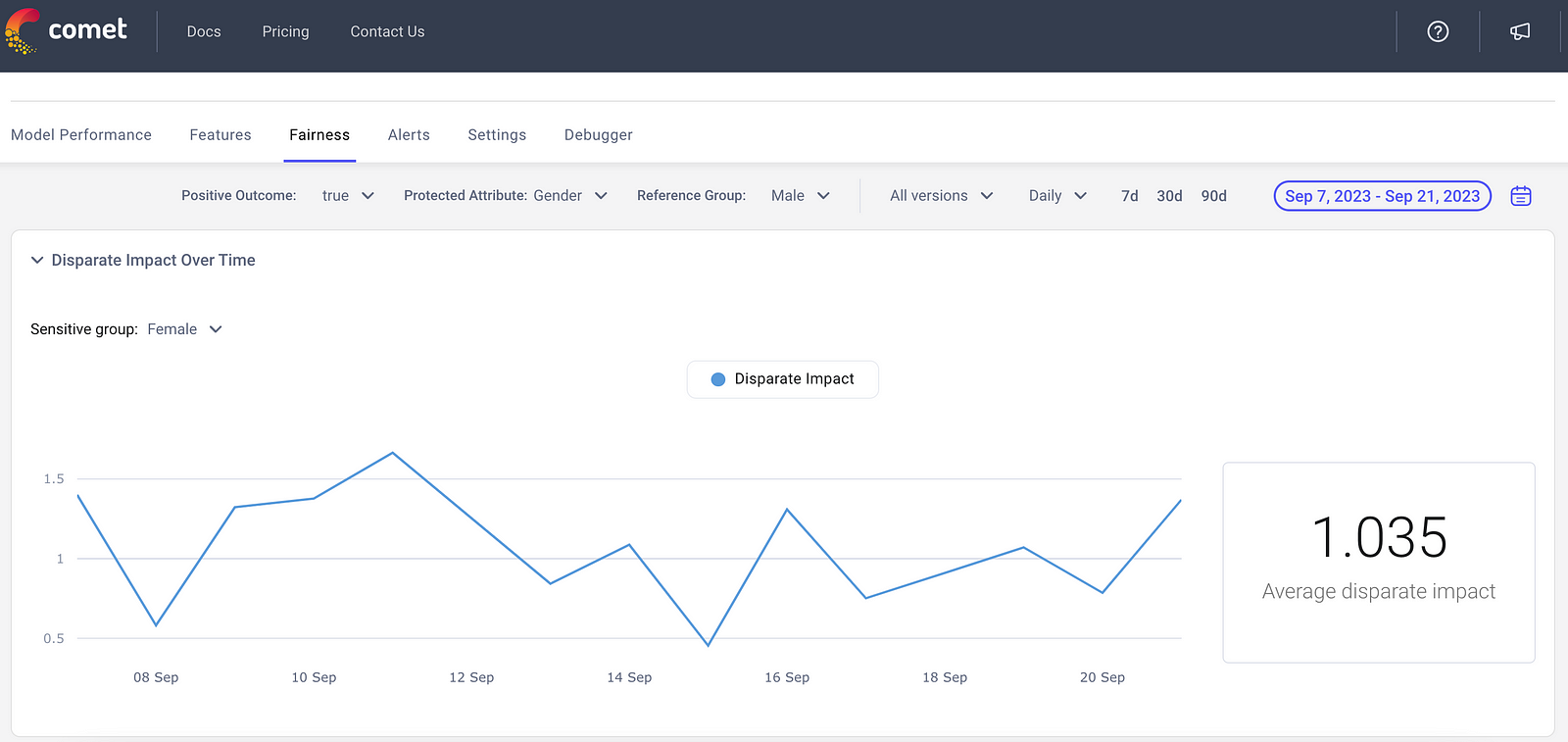
The accepted values for Disparate Impact ranges from 0.8–1.25.
Calculate Accuracy of Fraud Detection Models
Once a team gets access to ground truth labels they can upload them to Comet’s MPM and calculate Accuracy Metrics. Accuracy itself is often not the best metric to evaluate Fraud Detection Models. For example, let’s say fraudulent transactions only occur 3% of the time. A model that’s consistently predicts “no fraud ever” would be 97% accurate. Hence, metrics like precision, recall, and F1 score are often better metrics to pay attention to.
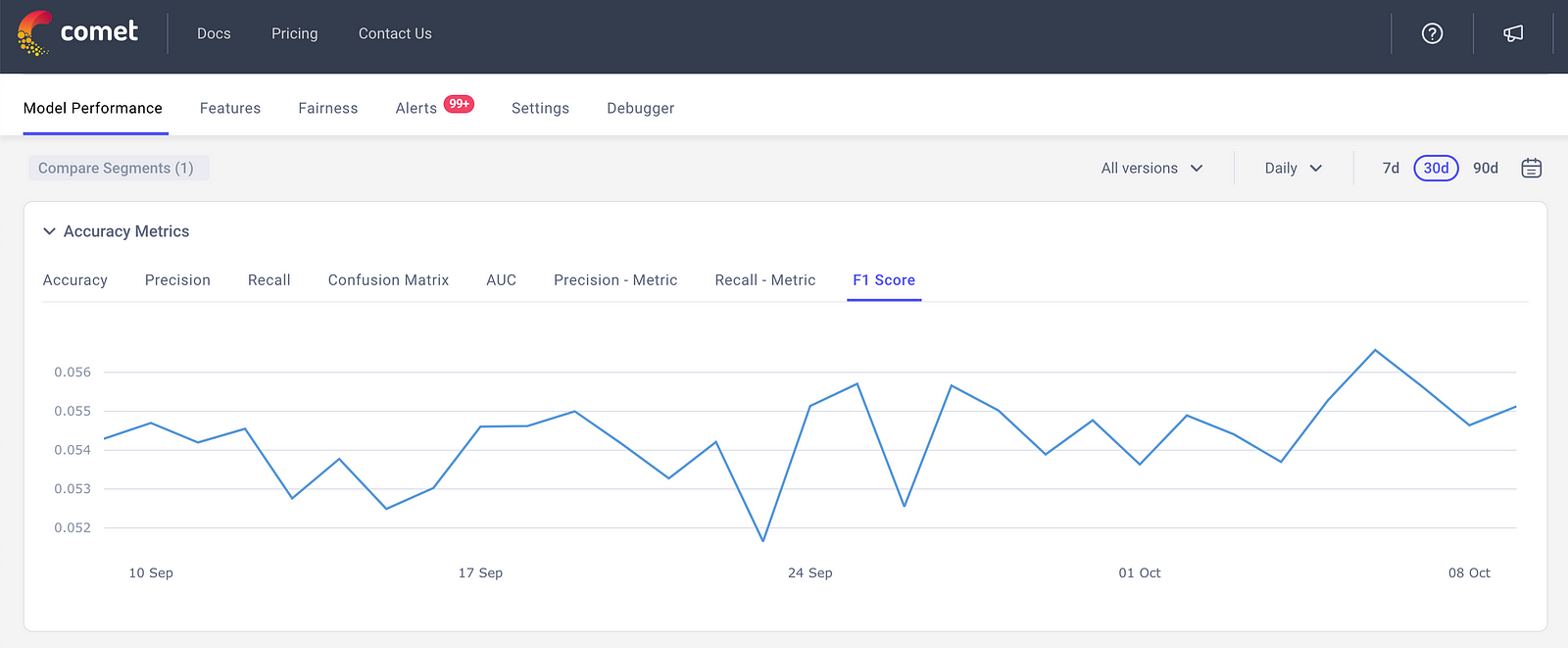
For instances where false negatives need to be minimized (the model predicts no fraud when there is fraud), teams should monitor Recall. If a team finds it unacceptable to mis-classify non-fraudulent transactions as fraud, then it makes more sense to pay attention to Precision. A Weighted F1 Score allows team factor both metrics.
Try Comet Today
Whether you want to send your predictions real-time or in batch, logging data to Comet MPM is extremely straight forward! Comet also provides the ability to track the exact code and training data used to train a particular model. Having immediate access to the training lineage makes debugging failing models much more efficient! If you want to learn more about how you can bridge the gap between training and production today with Comet, fill out this form!
