Introduction
In an era where developers and engineers are constantly evaluating and adopting cloud tools, one of the most important goals for any SaaS engineering team is to minimize production downtime.
Comet is a tool that helps Data Scientists track all the relevant information for their model training runs (including code, performance metrics, hyper-parameters, and cpu/data drift) and then monitor those models performance in production. Comet Cloud has over 100,000 end users and powers some of the most advanced ML teams at companies like Etsy, Assembly AI, and Affirm. Any downtime on Comet Cloud can have significant negative impacts:
1. Disrupted Workflows: Many Data Scientists rely on Comet to inform them on their model training run progress. If the current training run is performing worse than the previous ones, Data Scientists often stop training runs early to save costs.
2. Loss of Productivity: Comet improves ML team efficiency by 30%. Teams use Comet to determine which models are the latest and greatest. They then use Webhooks to update their downstream production systems.
3. Delayed Failure Detection Comet Cloud serves as an observability tool for Machine Learning Models. Today these models are making important decisions in self-driving cars, recommendations systems, and financial services. A drifted financial model can have significant monetary impact for a business and therefore must be caught immediately.
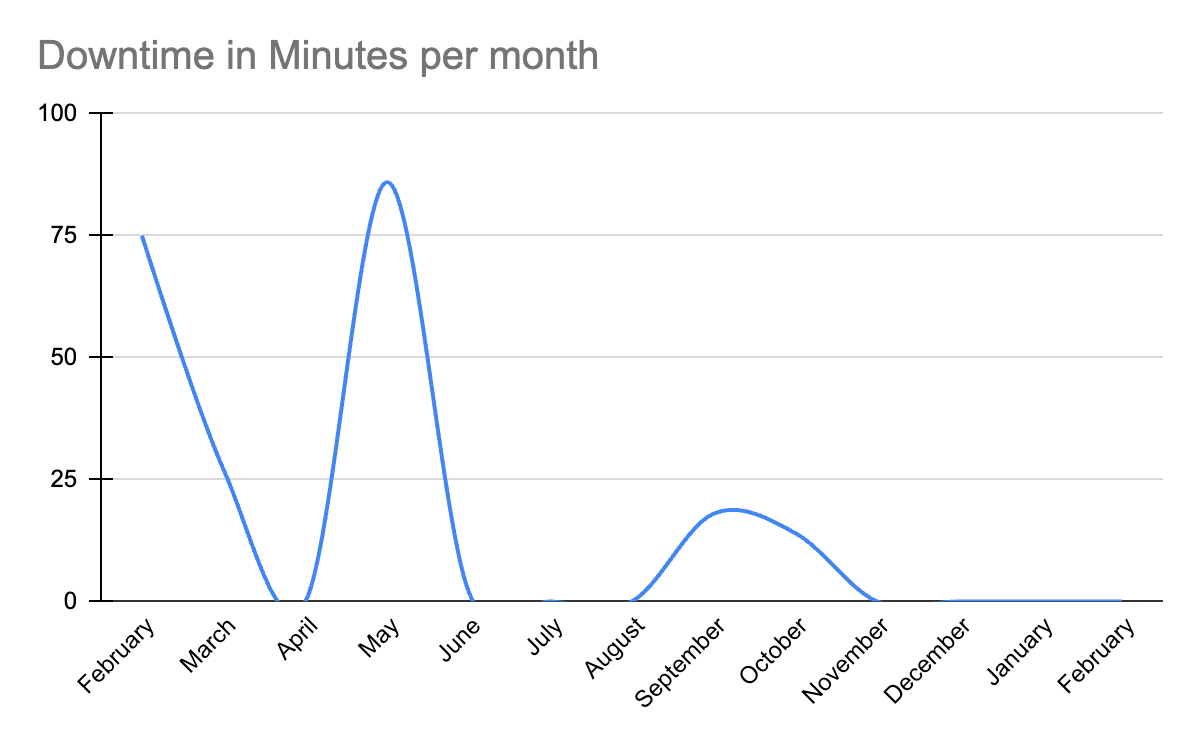
In 2022, Comet Cloud encountered several instances of service interruptions. For 2023, the Comet’s Engineering and set an aggressive goal to maintain 99.97% uptime.
Root Cause Analysis
The first step the Engineering team took was to examine the reasons why production downtime incidents were occuring. Taking a look back at their 2022 reports, they grouped the incidents into 3 separate categories
- Incidents caused by the Infrastructure
- Incidents caused by the Application
- Incidents caused by Human Error
To achieve their goals, the engineering team had to leave no stone unturned and make sure they addressed all 3 facets of their environment.
Infrastructure Migration from EC2 to Kubernetes
Comet’s Cloud Infrastructure was initially built upon EC2. However, the team needed something that was more scalable, efficient, and reliable. They decided to transition their infrastructure to Kubernetes. Kubernetes facilitates seamless updates, load balancing, and a declarative configuration approach; fostering a dynamic and resilient cloud infrastructure.
The migration didn’t happen overnight. The team spent the entire Q1 quarter 2023 meticulously planning and executing the transition. They used a phase approach of sending half of their data traffic to their Kubernetes to thoroughly stress test the system and iron out any kinks before making the complete switch.
In the initial phase, traffic splitting involved the addition of a dedicated HTTP header named “Routing-Traffic”. This header was incorporated into all HTTP requests coming in from our clients (Comet-ML SDK or Comet-UI). When the header’s value was set to “EKS”, the AWS ALB Ingress Controller recognized it and directed the traffic to the Kubernetes instances, otherwise, EC2 instances were utilized. As the migration progressed, the team later implemented a 50/50 random traffic split in subsequent stages.
To achieve a 50/50 random allocation between a Kubernetes pod and EC2 instances, the team utilized header-based routing and random weighted traffic switching between targets while simultaneously monitoring the system to identify errors.
- Use two target groups: one for the Kubernetes pod(s) created automatically by Kubernetes and another created with terraform for EC2 instances.
- Update Ingress Configuration as per the below flow diagram :
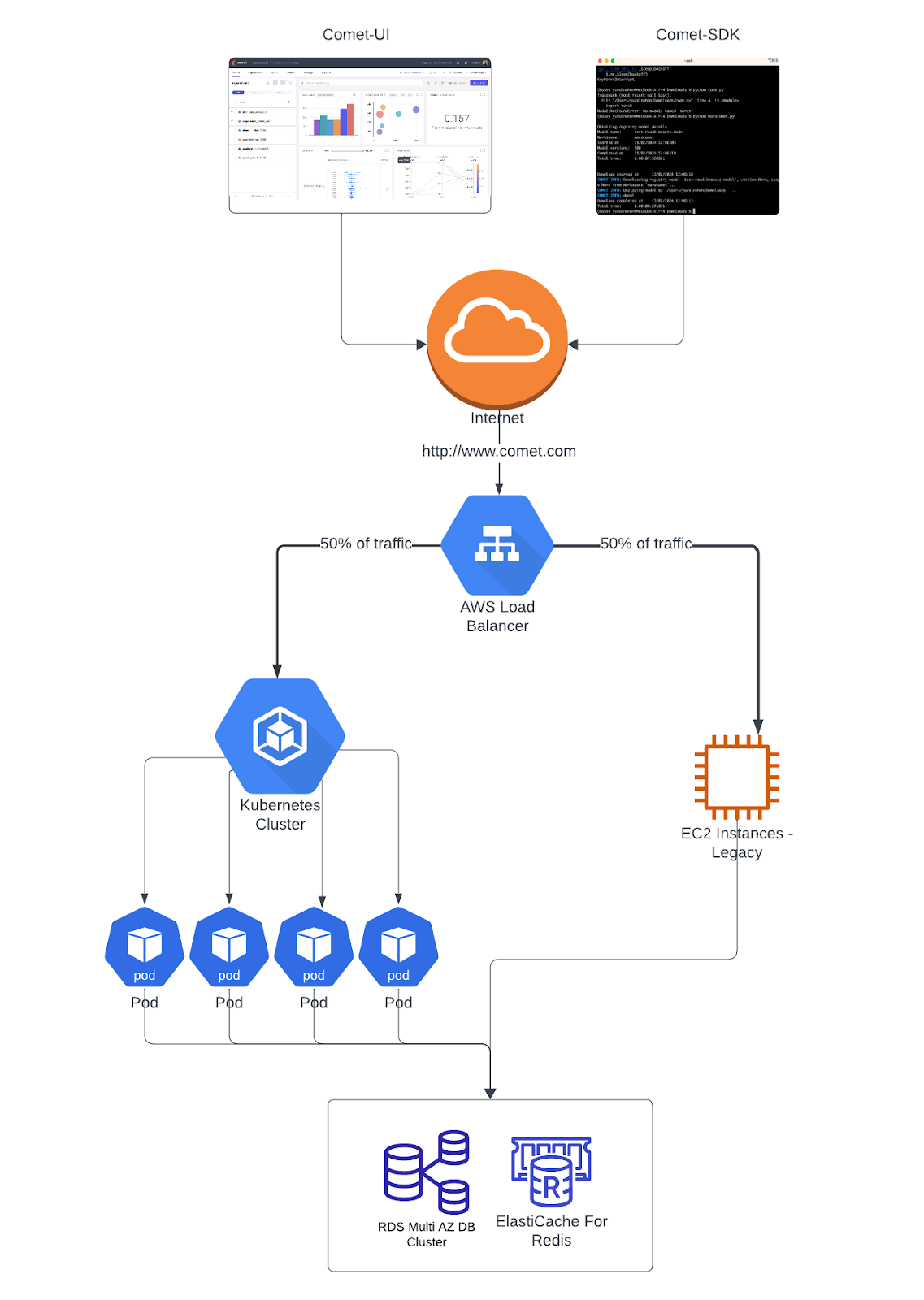
- Modify Ingress resource configuration to include header-based routing and random weighted traffic switching between target groups.
ingress: hosts: - paths: - path: / pathType: Prefix action: rule-header # switch traffic according to header - path: / pathType: Prefix action: rule-weighted # weighted random traffic switching annotations: kubernetes.io/ingress.class: 'alb' alb.ingress.kubernetes.io/listen-ports: '[{"HTTP":***},{"HTTPS":***}]' alb.ingress.kubernetes.io/load-balancer-attributes: 'idle_timeout.timeout_seconds=90' alb.ingress.kubernetes.io/scheme: 'internet-facing' alb.ingress.kubernetes.io/ssl-redirect: '***' alb.ingress.kubernetes.io/success-codes: '200-399' alb.ingress.kubernetes.io/target-group-attributes: 'stickiness.enabled=true,stickiness.lb_cookie.duration_seconds=3600' alb.ingress.kubernetes.io/target-type: 'ip' # switching on the header alb.ingress.kubernetes.io/conditions.rule-header: '[{"field":"http-header","httpHeaderConfig":{"httpHeaderName":"Routing-Traffic","values":["EKS"]}}]' alb.ingress.kubernetes.io/actions.rule-eks: >- {"type":"forward","targetGroupARN":"arn:aws:elasticloadbalancing:us-east-1:your-targetgroup-arn"} # weighted random switching alb.ingress.kubernetes.io/actions.rule-api: >- { "type":"forward", "forwardConfig":{ "targetGroups":[ { "targetGroupARN":"arn:aws:elasticloadbalancing:us-east-1:your-targetgroup-arn", "servicePort":****, "weight":50 },{ "targetGroupARN":"arn:aws:elasticloadbalancing:us-east-1:your-targetgroup-arn", "servicePort":****, "weight":50 }], "targetGroupStickinessConfig":{"enabled":true,"durationSeconds":300} } }
Regulating and Optimizing System Data Ingestion
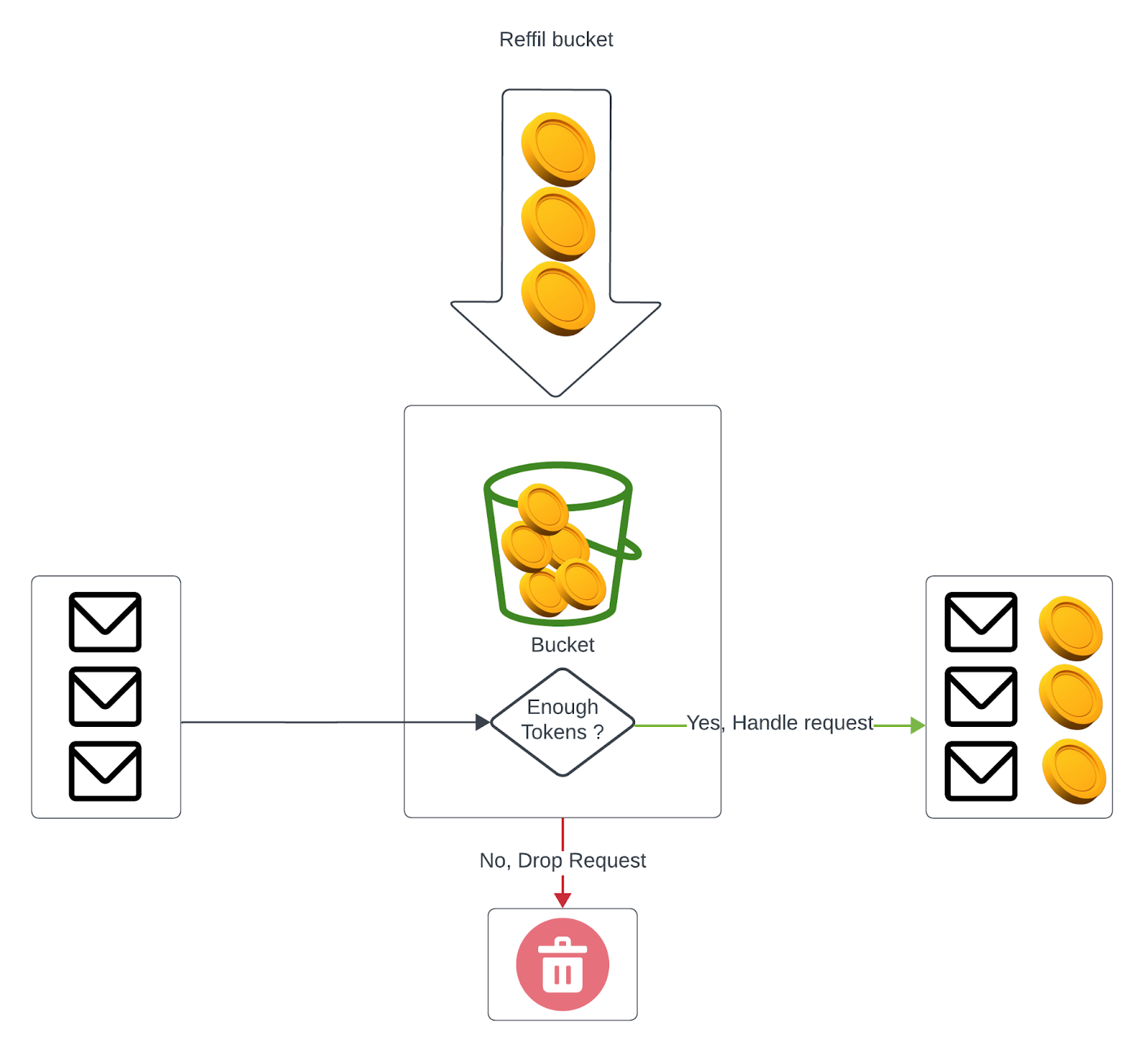
Data Scientists are large amounts of data when they are using Comet Cloud to track their model training runs. Not only do practitioners log scalar items like hyper-parameters and metrics, but also large files containing the training data and the actual model weights. For these high utilization jobs, the team implemented a throttling mechanism to regulate usage.
In order to control the data traffic that goes into Comet Cloud, the team selected to use the Token Bucket algorithm (See the diagram below). The Token Bucket Algorithm is a method used for rate limiting and traffic shaping in computer networks and telecommunications systems. It controls the rate at which units of data (or tokens) a transmitted or processed over a network.
Implementing the Token Bucket Algorithm within the system effectively prevented network congestion and resource exhaustion, enabling the team to enhance the overall quality of our service and system stability.
Building a Culture of Reviewing and Testing
Human errors caused a series of downtime issues for Comet Cloud. To mitigate these instances in the future, the team mandated approvals to modify any changes to the production environment. This policy aligns with a broader organizational strategy focused on prioritizing stability, reliability, and the overall integrity of the production environment
Conclusion
By combining all these efforts, the engineering team not only met their goal of keeping Comet Cloud uptime for at least 99.97% of the time, but exceeded it by having 0 minutes of downtime (100% uptime) in Q4 of 2023. Comet Cloud’s Uptime/Downtime metrics can be viewed by anyone at https://status.comet.com/.