Object detection is a field of computer vision used to identify and position objects within an image. Examples of object detection applications include detecting abnormal movement from security cameras, obstacle detection in autonomous driving, and character detection from within a document.
How do Object Detection Algorithms Work?
There are two main categories of object detection algorithms.
- Two-Stage Algorithms:
Two-stage object detection algorithms consist of two different stages. In the first step, potential object areas in the image are determined. In the second step, these potential fields are classified and corrected by the neural network model. Two-stage methods are more accurate than single-stage methods, but they work more slowly. R-CNN (Regions with Convolutional Neural Networks) and similar two-stage object detection algorithms are the most widely used in this regard. - Single-Stage Algorithms:
Single-stage object detection algorithms identify potential regions directly from within the image and then objects. Single-stage object detection algorithms do the whole process through a single neural network model. These algorithms aim to predict the objects in the image all at once and therefore the processing speed is very high. However, the accuracy rates of the single-stage methods are lower than the two-stage methods. Single-stage object detection algorithms such as YOLO (You Only Look Once) and SSD (Single Shot MultiBox Detector) are the most widely used algorithms in this regard. We will also examine these algorithms in the following stages of the article.
This blog lists the workings of different object detection algorithms and compares them with similar algorithms.
R-CNN (Regions with CNNs)
R-CNN (Regions with CNN or Region-based CNN) is an object detection algorithm that uses a CNN (Convolutional Neural Network) to identify objects within an image.

The R-CNN algorithm divides an image into parts that likely contain objects of interest and examines each of these parts separately. It then detects which objects are in these regions. The R-CNN algorithm can make sensitive detections and has a high accuracy rate. However, this algorithm is slower than other algorithms.
Mask R-CNN
Mask R-CNN (Masked Region-based Convolutional Neural Network) is an object detection and sample separation algorithm. This is an extension of the Faster R-CNN architecture, that is, a two-stage object detection algorithm.
Mask R-CNN is more powerful than other object recognition models because it also supports object segmentation. This is a useful feature for pinpointing the exact location of the object in the image and is also used in image analysis applications.
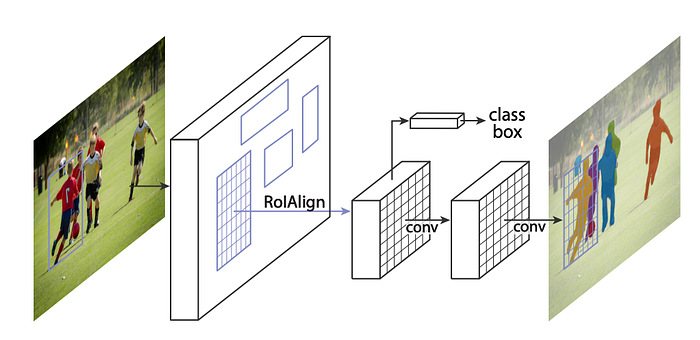
- First step: attributes of the input image (for example, object positions, dimensions, etc.) are extracted. This is done by the “backbone network” part of the model and is designed to extract the features of the image primarily by a customized CNN.
- Second Step: objects are defined and segmented using attributes. At this stage, its position, size, and segmentation mask (determining the exact area of the object in the image) are determined for each object.
The Mask R-CNN model is trained with a combination of directed learning and relearning techniques. The model is trained with a large dataset of marked images, where objects of interest and their respective masks are labeled. During training, the model is presented with an image with its own real labels and learns to predict the class and position of each object in the image, as well as the corresponding mask.
When you’re working on an enterprise scale, managing your ML models can be tricky. Learn how the team at Uber created a solution for their experiment management needs.
Faster R-CNN:
The Faster R-CNN algorithm is trained on datasets during the learning process. These datasets consist of pre-labeled images and the positions of the objects contained in each image have been labeled. After the algorithm is trained on the datasets, it scans the input images and identifies the objects.
- Faster R-CNN has a two-stage pipeline structure and feature extraction is performed in the first stage, and object recognition and positioning are performed in the second stage. This structure increases the efficiency and accuracy of the model and allows it to produce a faster result.
- Faster R-CNN uses a Region Proposal Network (RPN) in the object definition step. This mesh helps identify potential object regions in the image and reduces unnecessary work for the object recognition step.
- Multi-task learning: Faster R-CNN learns on multiple tasks simultaneously. The model simultaneously performs tasks such as object recognition and positioning, which increases the model’s efficiency and accuracy.
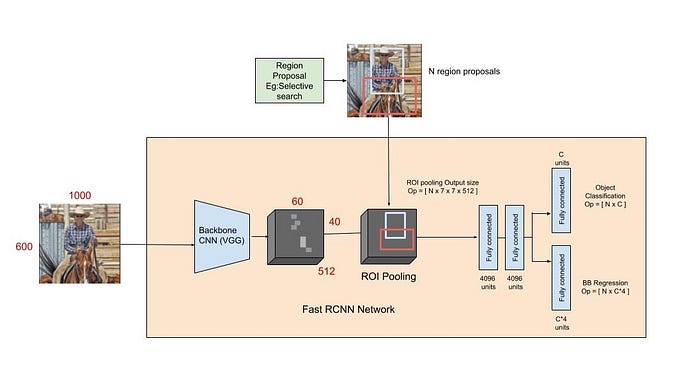
The Faster R-CNN algorithm works similarly to the R-CNN algorithm, but works faster and makes more precise detections.
SSD (Single Shot Detector)
Single Shot MultiBox Detector (SSD) is for object recognition and localization. This model aims to identify and localize multiple objects in a single run.
SSD analyzes the input image at multiple different scales at the same time and uses multiple object identification frames (anchors) at each scale. Each anchor is designed based on the expected dimensions of objects in the image and is used to estimate the position of the object in the image.
Another feature of SSD that differs from other object recognition models is that it performs a single classification step. In other models, object recognition and localization are done separately with the region proposal network (RPN), while SSD does a single classification step for each object.
Other advantages of SSD include speed and efficiency. The model works faster than other object recognition models and also has a higher success rate in image analytics applications.
YOLO (You Only Look Once)
The YOLO algorithm scans the given image in one go and divides it into parts. The goal is to identify potential regions and then objects. In each of these parts, it detects whether there are objects and detects the position of the object. It is an algorithm that is famous for its speed and high accuracy rate.
- Image Partitions: The image is divided into squares of certain sizes and object recognition is performed for each frame.
- Object Predictions: For each frame, object predictions are made by the neural network, and the region of the object is determined.
- Class Predictions: Class estimates are made for each region and what the object is is determined.
- Object Classification and Regional Positioning: Object recognition is completed by combining class and regional location data for each object.

YOLOv3 (You Only Look Once version 3)
YOLOv3 (YOLO version 3) is an object detection algorithm for detecting and classifying objects in images or video frames. The main difference between YOLO and YOLOv3 is that YOLOv3 is more accurate and efficient than YOLO. YOLOv3 is a newer version of YOLO and was released in 2018. It has been developed in many ways, including:
- YOLOv3 uses anchor boxes, which are predefined boxes, to detect objects. These anchor boxes help YOLOv3 handle objects of different shapes and sizes more effectively.
- YOLOv3 uses a stronger convolutional neural network (CNN) architecture, allowing it to learn more complex patterns and perform better on tasks such as object detection.
- YOLOv3 also uses a multi-scale training and prediction approach, allowing it to detect objects at different scales in the input image.
Overall, YOLOv3 is a more advanced object detection algorithm than YOLO and has the ability to achieve higher accuracy and efficiency.
DSSD (Deconvolutional Single Shot Detector)
DSSD (Deconvolutional Single Shot Detector) is a single-stage object detection algorithm developed to improve its speed and accuracy of object detection. It is based on Single Shot Detector (SSD) architecture, which is a fast and effective object detection algorithm widely used in various applications.
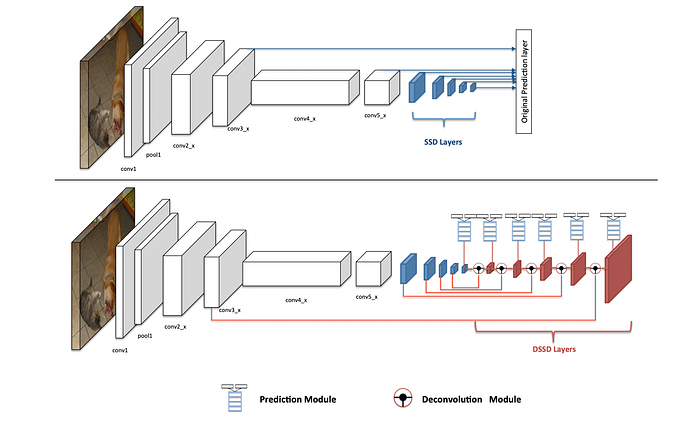
Like SSD, DSSD uses a convolutional neural network (CNN) to process the input image and predict the position and class of objects in the image. However, DSSD brings several improvements to improve the performance of SSD architecture.
A major improvement in DSSD is the use of deconvolutional layers that upscale CNN-generated feature maps. These layers improve the spatial resolution of feature maps, which is important for the accurate positioning and identification of small objects in an image.
Conclusion
We’ve gotten acquainted with object detection and understood its basic logic. We’ve also looked at the R-CNN, SSD, YOLO, Mask R-CNN, Faster R-CNN, YOLOv3, and DSSD algorithms.
You can follow my Medium account, and if you like the article, you can present your appreciation with claps.
You can also follow and communicate with me on social media. Thanks!
https://iremkomurcu.com/
