BERT — Bidirectional Encoder Representations from Transformers — is a pre-trained language model for natural language processing tasks such as text classification and question and answering. This article will look at fine-tuning the BERT for text classification. In the end, the BERT model will learn to label if a review from the imdb dataset is positive or negative.
To understand how the model is learning, we need to visualize histograms of the weights and biases, the activations and gradients. To achieve that, we use Comet to track the project. Comet automatically tracks these and other items such as:
- Optimizer Parameters
- Code
- Optimizer Parameters
- Metrics
- Weight histograms
Getting started
When using Comet, these items are logged by default, but you can manually configure what will be logged.
import comet_ml
experiment = comet_ml.Experiment(
api_key="YOUR_API_KEY",
project_name="HF", log_code=True,
auto_metric_logging=True,
auto_param_logging=True,
auto_histogram_weight_logging=True,
auto_histogram_gradient_logging=True,
auto_histogram_activation_logging=True,
)
Log parameters
Logging various parameters makes it easy to update them and compare how they affect the model’s performance. You can easily change a parameter when all parameters are saved in one dictionary. The log_parametersfunction is used for logging a dictionary of parameters in Comet.
# these will all get logged
params = {
"bert": "bert-base-uncased",
"num_labels": 2,
"return_tensors": "tf",
"batch_size": 8,
"epochs": 3,
"padding":"max_length",
"truncation": True,
"dataset": "imdb",
}
experiment.log_parameters(params)
Tokenize text data
We’ll use the imdb dataset to fine-tune BERT. Create a numerical representation of the data because it’s in text form. Use the BertTokenizersince you are fine-tuning a BERT model. This ensures that the data is in the form that the BERT requires. Next, we define a function that will tokenize the data and apply a maximum length and truncation to ensure that all sentences are the same length. Tokenizing the data converts it to a numerical representation that’s acceptable by the machine learning model. You can’t pass the raw sentences to the model.
def tokenize_function(examples):
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained(params['bert'])
return tokenizer(examples["text"], padding=params["padding"], truncation=params["truncation"])
Next, apply the function to the dataset. The map function applies the tokenization function to all the sentences. Next, shuffle the data and select the number of data points you would like to use.
from datasets import load_dataset dataset = load_dataset(params['dataset']) tokenizer = AutoTokenizer.from_pretrained(params['bert']) tokenized_datasets = dataset.map(tokenize_function, batched=True) small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000)) small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
Create TensorFlow dataset
We’ll fine-tune the BERT model in TensorFlow. Let’s convert the dataset to a TensorFlow dataset format. Hugging Face provides the DefaultDataCollator function to batch the dataset and perform data augmentation. After that, use the to_tf_dataset function to convert the dataset to TensorFlow format.
The to_tf_dataset method allows you to define the columns and labels included in the dataset. Converting the data to TensorFlow makes it possible to train the model using the fit method and later evaluate it using the evaluate method.
from transformers import DefaultDataCollator
data_collator = DefaultDataCollator(return_tensors=params['return_tensors'])
tf_train_dataset = small_train_dataset.to_tf_dataset(
columns=["attention_mask", "input_ids", "token_type_ids"],
label_cols=["labels"],
shuffle=True,
collate_fn=data_collator,
batch_size=params['batch_size'],)
tf_validation_dataset = small_eval_dataset.to_tf_dataset(
columns=["attention_mask", "input_ids", "token_type_ids"],
label_cols=["labels"],
shuffle=False,
collate_fn=data_collator,
batch_size=params['batch_size'],)
Train BERT model
The TFAutoModelForSequenceClassification is a model class with a sequence classification head. We can use it to initialize a pre-trained BERT classification model. Next, compile the model under a low learning rate and fit it to the data. Using a low learning rate is important in transfer learning to ensure that we don’t overfit the model.
import tensorflow as tf from transformers import TFAutoModelForSequenceClassification bert = TFAutoModelForSequenceClassification.from_pretrained(params['bert'], num_labels=params['num_labels']) bert.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=5e-5),loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),metrics=tf.metrics.SparseCategoricalAccuracy(),) bert.fit(tf_train_dataset, validation_data=tf_validation_dataset, epochs=params['epochs'])
Innovation and academia go hand-in-hand. Listen to our own CEO Gideon Mendels chat with the Stanford MLSys Seminar Series team about the future of MLOps and give the Comet platform a try for free!
Evaluate model performance
Since auto-logging is active, you will see live results of the model training on Comet. On the charts panel, you will see graphs for the:
- Loss
- Accuracy
- Epoch duration
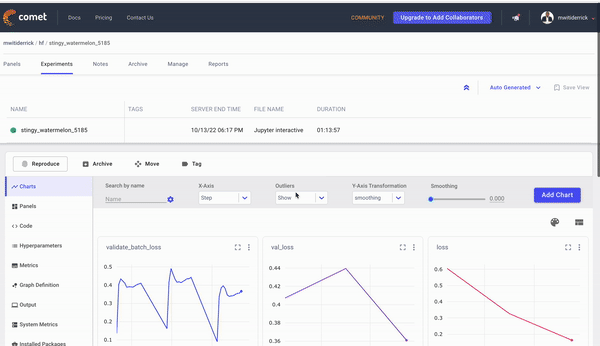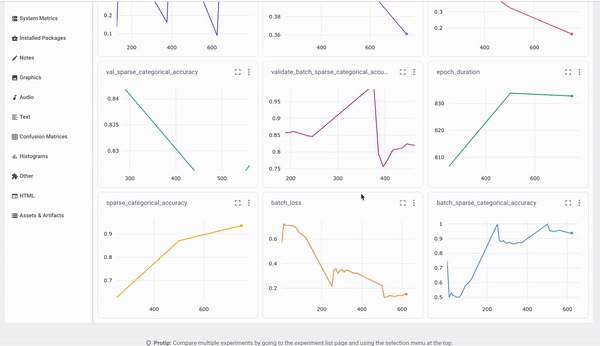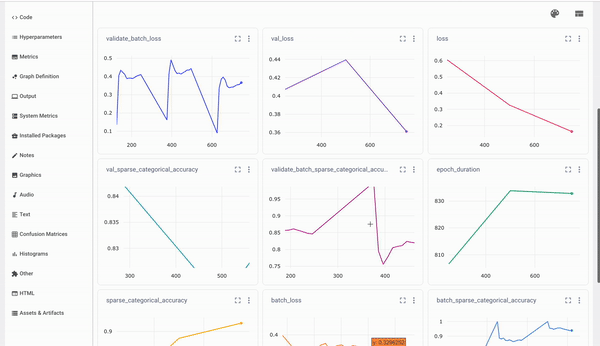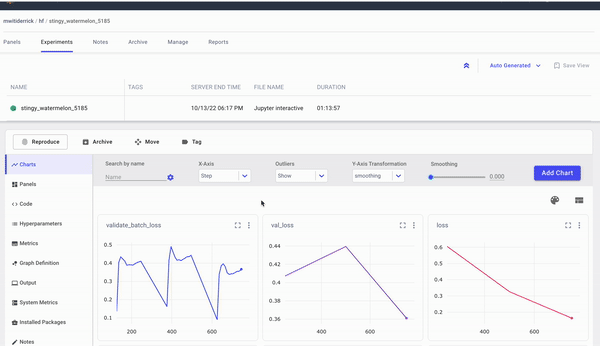
The Code tab will show the code used in this experiment. On the hyperparameters tab, you will see all the logged parameters.
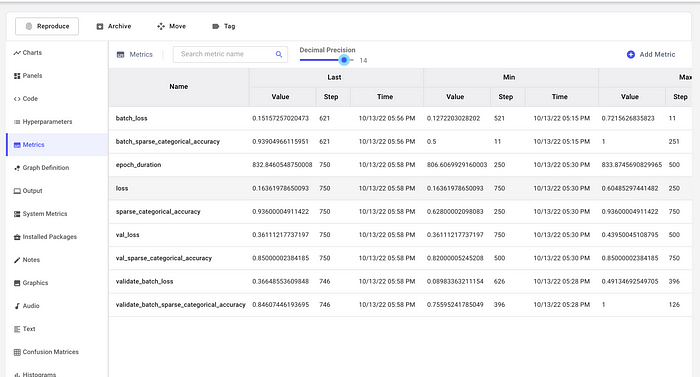
All model metrics can be viewed from the Metrics tab.
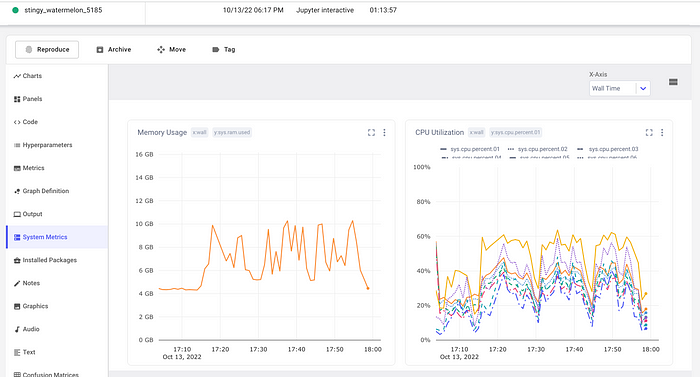
Click the System Metrics tab to see the Memory Usage and CPU Utilization for the model training process.
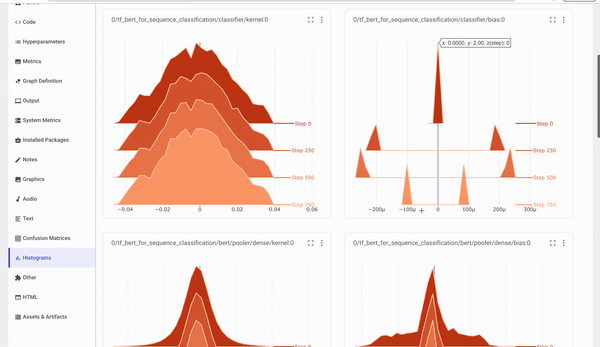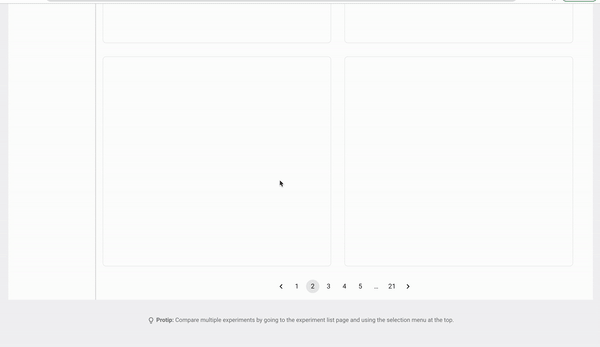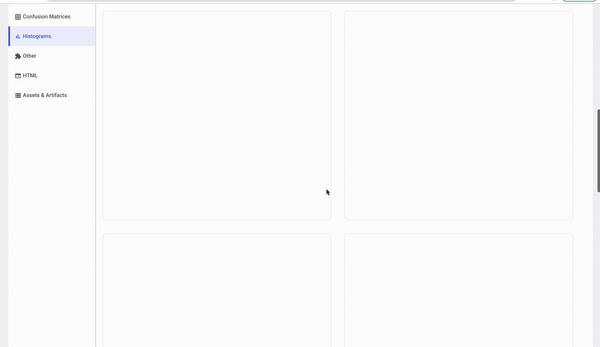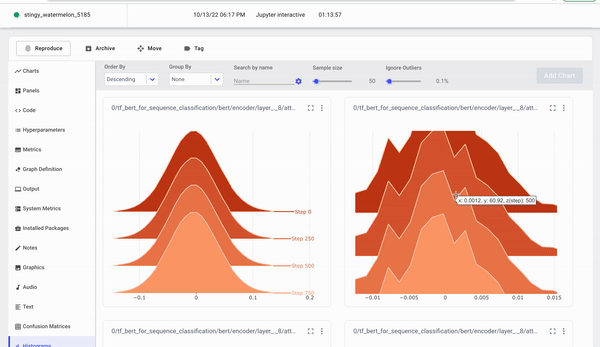
Click the Histograms tab to see histograms for the weights and biases, activations, and gradients.
Test model on new data
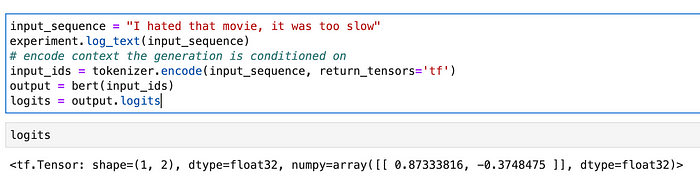
Check how the BERT model performs on new data. You can also log the test sentence to Comet. First, tokenize the input data, then pass it to the BERT model. It will output logits which you will need to decode.
input_sequence = "I hated that movie, it was too slow" experiment.log_text(input_sequence) # encode context the generation is conditioned on input_ids = tokenizer.encode(input_sequence, return_tensors='tf') output = bert(input_ids) logits = output.logits
Let’s interpret the prediction and log it as well. You can get the predicted class by passing the logits to tf.math.argmax. Passing the predicted class to bert.config.id2label will give you the predicted label.
predicted_class_id = int(tf.math.argmax(logits, axis=-1)[0]) prediction = bert.config.id2label[predicted_class_id] experiment.log_text(prediction) prediction

End the experiment to make sure all items are logged as expected.
experiment.end()
Final thoughts
This article has shown you how to fine-tune a BERT model for text classification while tracking the model using Comet. You can improve this model by increasing the amount of training data. You can also swap the BERT model with another Hugging Face transformer model and compare the performance.
Follow me on LinkedIn for more technical resources.
