Suppose you are working on a machine learning classification problem in which you have to predict whether a person is Covid positive or negative. You have a good dataset and you have applied classification algorithms and successfully built your classification model.
Now what should you do? How do you evaluate the performance of your classification model? How do you know how good the model is and whether the predictions are correct or not? The simple answer to this question is evaluation metrics.
Evaluation metrics are used to measure the performance of the machine learning model. Evaluating a machine learning model is an essential part of the data science pipeline. There are different types of evaluation metrics available to test the efficiency of the model such as confusion matrix, classification accuracy, loss, and others.
These evaluation metrics play an important role in ensuring that the machine learning model is working optimally and correctly. This series will discuss various evaluation metrics and how and when we should use them.
Confusion Matrix
In machine learning, a confusion matrix is a technique to visualize the performance of a classification model on the set of our test data. Calculating a confusion matrix gives us a proper idea of how many values are being predicted correctly and how many are being predicted incorrectly by our classification model. This matrix also lets us know what types of errors the classification model makes.
This is a confusion matrix:
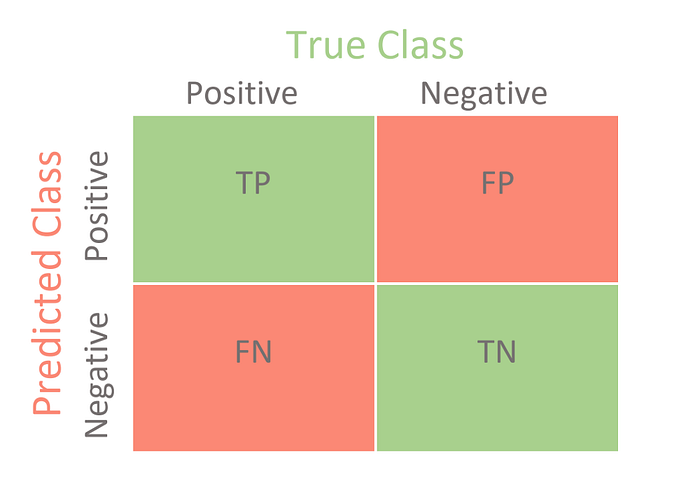
The confusion matrix contains four types of outcomes. These outcomes are:
1. True Positive (TP):
A true positive is an outcome where the model correctly predicts the positive class. In our Covid example, a person who is classified as Covid-positive by the model and is actually positive is the true positive outcome.
2. True Negative (TN):
A true negative is an outcome where the model correctly predicts the negative class. In our Covid example, a person who is classified as Covid-negative by the model and is actually covid negative, which is a true negative outcome.
3. False Positive (FP):
A false positive is an outcome where the model incorrectly predicts the positive class. In this outcome, the model classifies the outcome as positive but it actually belongs to the negative class.
In our Covid example, a person who is classified as Covid-positive (positive class) by the model but is actually Covid-negative is a false positive outcome.
4. False Negative (FN):
A false negative is an outcome where the model incorrectly predicts the negative class. In this outcome, the model classifies the outcome as negative but it actually belongs to the positive class.
In our example, a person who is classified as Covid-negative (negative class) by the model but is actually Covid-positive is a false negative outcome.
Join 16,000 of your colleagues at Deep Learning Weekly for the latest products, acquisitions, technologies, deep-dives and more.
Accuracy
In machine learning, accuracy is one of the metrics for evaluating classification models. It is the fraction of predictions that our model classified correctly. Accuracy is calculated as the number of correct predictions divided by the total number of observations in the dataset. It has the following definition:

For binary classification we can calculate accuracy in terms of positive and negative outcomes in the following way:
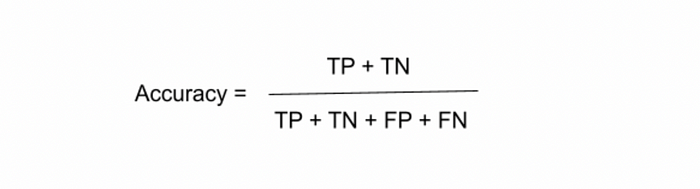
Accuracy is a good choice for the evaluation of classification models where the dataset is well balanced and there is no class imbalance in the data and the dataset is not skewed as well.
Precision
This evaluation metric is used to tell what fraction of positive predictions were actually positive. In simple terms, precision is the ratio between true positive (TP) and all the positive predictions.
It attempts to answer the following question:
What proportion of positive identifications was actually correct?
It is calculated as the number of correct positive predictions divided by the total number of positive predictions. It has the following definition:
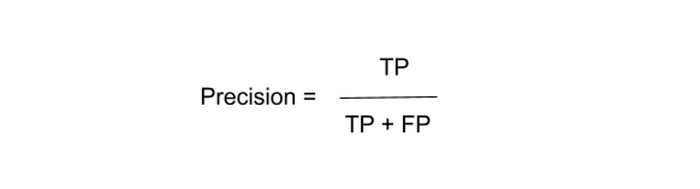
Precision is a good choice for the evaluation of classification models when we want to be very sure of our prediction. We need to use precision in such cases where we do not care about false negatives but our focus is mainly on true positive and false-positive outcomes.
For example, in spam email detection, the use of this precision metric is recommended. It is acceptable if the spam mail is identified as not spam and comes into the inbox folder, but any important mail should not go into the spam folder.
Recall
Recall, also known as Sensitivity or True Positive Rate, is used to tell what fraction of all positive observations were correctly predicted as positive by the classifier.
It attempts to answer the following question:
What proportion of actual positives was identified correctly?
It is calculated as the number of correct positive predictions (TP) divided by the total number of positives. It has the following definition:
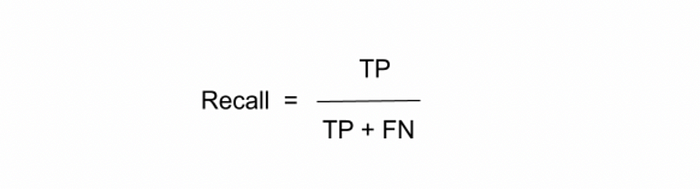
Recall is a good choice for the evaluation of classification models when we need output-sensitive predictions and high cost is associated with false negatives. For example, when predicting whether a person has cancer or not, we need to cover both true positive and false negatives. If a person with cancer (Actual Positive) goes for the tests and the result is predicted as no cancer (Predicted Negative), this is a false negative outcome. The cost associated with false negative is high as it may be hazardous for a patient’s life.
Conclusion
Now we know what evaluation metrics are and which evaluation metric is used in what kind of scenario. In the next part we will discuss what kind of evaluation metrics are used for multi-class classification problems.
Thanks for reading!
