
As a data professional, switching machine learning tracking tools happens. It ends up being time consuming work rewriting the code into the new tool. Data scientists are no exception: we often have to rework previous code that was used in experiment tracking.
This was the problem I faced in 2021, when I switched from MLflow workflows to Comet. I was worried that I would have to translate the code and face the process of retesting and retraining. Fortunately, this wasn’t the case.
One of the less known features of Comet is that it can be used with MLflow. This means that experiment tracking can be used with your existing code.
This article is directed towards people with familiarity with experiment tracking, as well as the Comet and MLflow user interface.
In this article, I will discuss:
- Differences between MLflow and Comet.
- The advantages of using Comet to enhance your existing MLflow experiments.
- How to set up your existing MLflow experiment workflow and integrate it with Comet
- Limitations of MLflow experiment workflow.
Let’s get started.
MLflow vs. Comet

Before I get into how to use Comet with MLflow, it’s important to compare the two.
What is MLflow?
MLflow is an open source platform to manage the different stages of machine learning operations: experimentation, reproducibility, deployment, and a central model registry. For MLflow, this consists of:
- Experiment Tracking: artifact, metrics, and parameter tracking
- Reproducible Experiment Runs
- Machine Learning Model Stores
- Model Registry
It is also available on cloud platforms such as Databricks in Azure or AWS, allowing data scientists and machine learning engineers to reproduce their work in the cloud and in Jupyter notebook.
It allows sending models to your deployment tools of choice. You can record runs, organize them into experiments, and log additional data using the MLflow tracking API and UI.
MLflow also allows you to access artifacts and models from experiment runs their UI on either your system or cloud provider.
So how does Comet compare?
Comet’s Advantages
Comet has several advantages over MLflow:
- Automatic Logging. Track and version Jupyter notebooks and machine learning Python notebooks, along with their outputs. Regardless of whether you submit your experiment, everything will be safely versioned and ready to be explored.
- Hardware Metrics. Comet automatically monitors your hardware metrics. You can monitor CPU, GPU, memory consumption live while you train your models. With MLflow, you need to wait until a run is completed. If you have existing MLflow runs, and use Comet with it, you’ll be able to see resource usages in real time.
- Easier Visualization. Visualizations are easily accessible and customizable within Comet via Panels. You can graph the changes easily using drag and drop
- Better Experiment Organization. You can see everything that was logged and can conveniently organize your experiments, filtering them by tag, parameter, etc.
- Online Storage. Comet allows you to save experiments by backing it up on Comet, allowing you to easily share experiments between team members. MLflow stores and tracks experiments locally, limiting user collaboration.
If you’re making the switch over to Comet and have MLflow experiments, you are able to take advantage of these features of Comet.
Setting Up
To get Comet to run with MLflow, you will need to install an additional extension to Comet: comet for mlflow.
!pip install comet-for-mlflow
A Comet API Key must be configured prior to the run to be able to log experiment data from MLflow into a live experiment. More on this can be found on the Comet documentation.
It is also useful to change the experiment workspace, since Comet will place all experiments in the default folder. To set the workspace simply change the workspace:
comet_ml.login(project_name="enhancing-ml-flow")
This will also allow you to check if you have your API key is valid or automatically set for the environment.
Comet will automatically run and save the following in MLflow:
- Metrics
- Hyperparameters
- Models
- Assets
- Source code
- Git repo and patch info
- System Metrics
- CPU and GPU usage
- Python packages
- Command-line arguments
- Standard output
- Installed OS packages
Comet for MLflow is designed to work with existing MLflow pipelines, with relatively few modifications. Your metrics, parameters, artifacts, and models will be logged and you will be able to use some of the features of Comet’s experiment tracking.
Running Comet with an MLflow Experiment

This experiment will be run from start to finish with the following Jupyter notebook using the UCI Wine dataset:
UCI Machine Learning Repository: Wine Quality Data Set
For clarity, we will be using snippets from that notebook to demonstrate how to enhance your existing MLflow experiments with Comet.
Please note:
Comet_ML library and experiment must be run before MLflow and sklearn. They cannot be run in the same cell if you are using Jupyter notebook.
Starting and Ending an MLflow with Comet Experiment
Running an MLflow experiment with Comet is different than a standard Comet experiment. In a normal Comet experiment, you would call the Experiment method first, then define the parameters. This is seen below:
experiment = Experiment(workspace="mattblasa",
project_name="comet_mlflow",
log_code = True)
However, in an experiment that uses existing MLflow coding, calling the Experiment() method would result in two different experiments being created. Instead, you can use your existing MLflow experiment to run Comet:
#Comet Experiment begins here
mlflow.start_run()
mlflow.set_experiment("mlflow_wine") #use this to set the run name.
'''
Your Code
'''
#Comet Experiment ends here
mlflow.end_run()
Comet will automatically run an existing MLflow experiment starting with the mlflow.start_run() method, and end with the mflow.end_run() method. All code in between the two will be logged.
Want to try Comet today? It’s free! Sign up for an individual or start-up account and see how Comet can help you make better models, faster.
Logging Graphs
You can also log your current graphs that are created in an MLflow run. Unlike a normal Comet run, you will not be able to log the figure directly to the run. You will need to do two steps:
- Save using Matplotlib’s savefig method. When Comet for MLflow runs this method, it will automatically log it to the image store.
- Log artifact. It’s a good practice to save the picture in both your local machine flow and in an online Comet experiment. To do this, use the mlflow.log_artifact with the saved figure from the previous step.
These will be saved in the graphics tab of a current experiment.
An example of this code is in the snippet below:
##create figure
plt.bar(data['quality'], data['fixed acidity'])
plt.xlabel('Quality')
plt.ylabel('Fixed Acidity')
plt.title('Quality')
plt.savefig("quality.png") #saves figure to comet image store
plt.show()
mlflow.log_artifact("quality.png") #saves figure to artifact store in comet
Logging Metrics and Parameters.
Comet will also log parameters used in hyperparameters, mlflow.log_param, and mlflow.log_metric. This will log into the hyperparamters and the model metrics to a Comet experiment run. These can be accessed from the metrics column in the experiment tab.
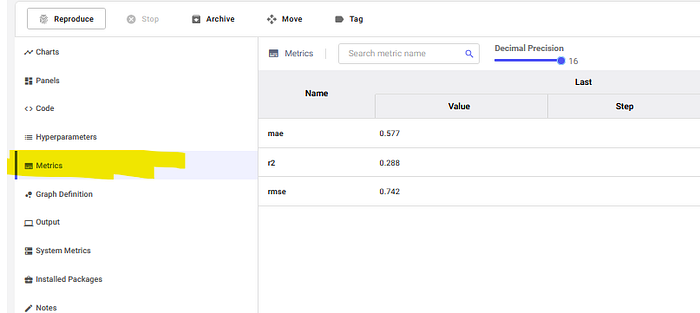
Example of MLflow metrics and parameters is below:
predicted_qualities = lr.predict(test_x)
(rmse, mae, r2) = eval_metrics(test_y, predicted_qualities)
print("Elasticnet model (alpha=%f, l1_ratio=%f):" % (alpha, l1_ratio))
print(" RMSE: %s" % rmse)
print(" MAE: %s" % mae)
print(" R2: %s" % r2)
#Log hyperparameters
mlflow.log_param("alpha", alpha)
mlflow.log_param("l1_ratio", l1_ratio)
#Log metrics
mlflow.log_metric("rmse", rmse)
mlflow.log_metric("r2", r2)
mlflow.log_metric("mae", mae)
Logging Model
To save your MLflow model it’s best to save it on your computer. Use the mlflow.sklearn.log_model method to save it to your local drive. This allows you to revert to an older previous model version if you need to.
#save model to artifact store in local drive
mlflow.sklearn.log_model(lr, "model")
#This will output the local folder name for your run meta data, artifacts, and data model
print("Model saved in run %s" % mlflow.active_run().info.run_uuid)
All models saved by this method are saved as a pickle file (Example: model.pkl) within the run name (the uuid). These will also be logged into the Assets and Artifact tabs in Comet.
If you want to upload the model created in MLflow to Comet, you will need to create a separate experiment, and upload it that way. Here is an example:
from comet_ml import Experiment
experiment = Experiment(workspace="mattblasa", project_name="comet_mlflow", log_code = True)
experiment.log_model("Test Model", "model.pkl")
experiment.add_tag('Register Model')
experiment.end()
Finding Your MLflow Experiment Artifacts
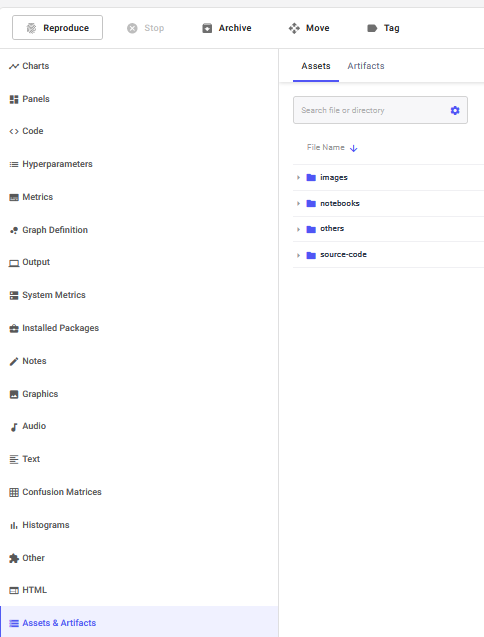
Once you have ran the experiment, go to the Assets and Artifacts tab in the dropdown menu. All images, machine learning models, csv, and any other Artifacts will be added to this tab. Please note that you cannot register a ML model directly to Comet’s model store nor to the the Comet’s Artifact store. These tasks will have to be done manually.
Limitations
Using Comet for MLflow runs has limitations that are not present in a normal Comet experiment run. Running an existing MLflow experiment can be inefficient since it limit using some of Comet’s best features.
Nested Flow Runs are Not Supported
Comet does not support MLflow nested runs. This means that you cannot use the with statement to run the MLflow code, it must be outside of the with statement. MLflow runs that are enhanced using Comet need to be de-nested.
A nested run example is below:
with mlflow.start_run():
'''
ML code Here
'''
# Model registry does not work with file store
if tracking_url_type_store != "file":
# Register the model
# There are other ways to use the Model Registry, which depends on the use case,
# please refer to the doc for more information:
# <https://mlflow.org/docs/latest/model-registry.html#api-workflow>
mlflow.sklearn.log_model(lr, "model", registered_model_name="ElasticnetWineModel")
else:
mlflow.sklearn.log_model(lr, "model")
A de-nested MLflow required to run Comet is below:
mlflow.start_run()
'''
ML code here
'''
# Model registry does not work with file store
if tracking_url_type_store != "file":
# Register the model
# There are other ways to use the Model Registry, which depends on the use case,
# please refer to the doc for more information:
# <https://mlflow.org/docs/latest/model-registry.html#api-workflow>
mlflow.sklearn.log_model(lr, "model", registered_model_name="ElasticnetWineModel")
else:
mlflow.sklearn.log_model(lr, "model")
mlflow.end_run()
This can make exception handling and resource management difficult, since the with statement usually encapsulates common preparation and cleanup tasks. It ensures that encapsulated tasks don’t block other processes if an exception is raised, but terminates properly.
This can make MLflow runs enhanced with Comet difficult to use. It may require significantly refactoring the code within a normal Comet experiment flow.
Manual Versioning of ML Models
Comet’s model registry allows you to log, register, version, and deploy machine learning models. This is very important for being able to reproduce and iterate on ML models. In a normal Comet run, models that are uploaded via the model logging method can be registered.
MLflow experiments enhanced with Comet cannot send machine learning models to this model registry. It will save it as a model in the local drive and will be saved as an Artifact on Comet. Since it is an Artifact, you will not be able to version it.
The only way to send a model created by MLflow is to create a second experiment using a normal Comet workflow to upload the model. This can slow down development and deployment time significantly but is a workaround.
Artifacts Cannot Be Pushed to the Artifact Store
Artifacts from MLflow experiment run with Comet cannot be saved to the Comet’s Artifact store. Comet’s Artifact store allows you to keep track of versioning of assets: ML model, a flat file, pictures, audio files, etc., allowing the users to use them or retrieve them at any stage of the ML pipeline. It provides a location online with the ability to version Artifacts used.
MLflow experiments enhanced with Comet are not included in this feature. While they are uploaded in the Artifacts and Assets area each time an experiment is run, they cannot be saved to the Artifact store.
Like the model registry store, the only way to send your Artifacts created in MLflow experiment is to create a second experiment using a normal Comet workflow and uploaded them individually.
Conclusion
MLflow is a great entry level tool for users getting into experiment tracking, but can be limiting for teams. Using Comet for MLflow is a great way to promote teams to work together to version, comment, and view performance of machine learning models. It’s also a great way to maintain existing MLflow experiments.
Comet for MLflow is useful for this transition from MLflow to Comet. However, it is not replacement for the full functionality of Comet, which includes a greater range of features.
I hope this article will give you the knowledge and motivation to use Comet for your existing MLflow experiments, and to migrate to Comet for your future experiments.
Feel free to play with and fork the source code of this article here:
Github Repo — Enhancing MLflow with Comet
If you enjoyed this article, you might also enjoy my other articles at Heartbeat:
Integrating Comet and Azure Databricks
Thank you for reading! Connect with me on LinkedIn for more on data science topics.
