When it comes to chatbots and conversational agents, the ability to retain and remember information is critical to creating fluid, human-like interactions. This article describes the concept of memory in LangChain and explores its importance, implementation, and various strategies for optimizing conversation flow.
💡I write about Machine Learning on Medium || Github || Kaggle || Linkedin. 🔔 Follow “Nhi Yen” for future updates!

👉 I previously shared relevant articles on creating a basic chatbot without using Conversation Memory. You might find it interesting.
Why Memory Matters in Conversational Agents
When users interact with chatbots, they often expect a level of continuity and understanding similar to human conversations. This expectation includes the ability to refer to past information, which leads to the conversational agent’s need for memory. Memory allows the system to remember previous interactions, process abbreviations, and perform co-reference resolution, ensuring consistent, context-aware conversations.
The Memory Challenge in Large Language Models
Large language models like LangChain do not have their own memory. Unlike humans, who naturally retain information during conversations, these models operate on a rapid response mechanism. Attempts have been made to integrate memory into its Transformer model, but large-scale practical implementation remains a challenge.
Memory Strategies in LangChain
Given a context that when a customer inquires about the customer service of a fashion store and expresses a problem with the jeans. This issue involves a stuck zipper and is similar to a hardware issue. I’ll ask the conversational agent bot a list of questions for each LangChain memory type:
1. Hey! I am Nhi.
2. How are you today?
3. I'm doing well, thank you. I need your assistance.
4. I bought this pair of jeans, and there's a problem.
5. When I tried them on, the zipper got stuck, and now I can't unzip it.
6. It seems to be a problem with the zipper.
In this experiment, I’ll use Comet LLM to record prompts, responses, and metadata for each memory type for performance optimization purposes. This allows me to track response duration, tokens, and cost for each interaction. View the full project HERE.
Comet LLM provides additional features such as UI visualization, detailed chain execution logs, automatic tracking with OpenAI chat model, and user feedback analysis.
Find the complete code in this GitHub Repository.
To start, bring in the common libraries needed for all 6 memory types. Make sure you’ve installed the necessary Python packages in requirements.txt and have your OpenAI API and Comet API keys ready. (Reference: OpenAI Help Center — Where can I find my API key?; CometLLM — Obtaining your API key)
import os
import dotenv
import comet_llm
from langchain.callbacks import get_openai_callback
import time
dotenv.load_dotenv()
MY_OPENAI_KEY = os.getenv("YOUR_OPENAI_KEY")
MY_COMET_KEY = os.getenv("YOUR_COMET_KEY")
# Initialize a Comet project
comet_llm.init(project="YOUR COMET PROJECT NAME",
api_key=MY_COMET_KEY)
1. Conversation Buffer Memory
The simplest form of memory involves the creation of a talk buffer. In this approach, the model keeps a record of ongoing conversations and accumulates each user-agent interaction into a message. While effective for limited interactions, scalability becomes an issue for long conversations.
🎯 Implementation: Include the entire conversation in the prompt.
✅ Pros: Simple and effective for short interactions.
❌ Cons: Limited by token span; impractical for lengthy conversations.
from langchain.chains.conversation.memory import ConversationBufferMemory
from langchain_openai import OpenAI
from langchain.chains import ConversationChain
from langchain.callbacks import get_openai_callback
llm = OpenAI(openai_api_key=MY_OPENAI_KEY,
temperature=0,
max_tokens = 256)
buffer_memory = ConversationBufferMemory()
conversation = ConversationChain(
llm=llm,
verbose=True,
memory=buffer_memory
)
Interact with the conversational agent bot by inputting each prompt in conversation.predict(). Example:
conversation.predict(input="Hey! I am Nhi.")
conversation.predict(input="How are you today?")
conversation.predict(input="I'm doing well, thank you. I need your assistant.")
Output after the 3rd prompt:
> Entering new ConversationChain chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
Human: Hey! I am Nhi.
AI: Hi Nhi! My name is AI. It's nice to meet you. What can I do for you today?
Human: How are you today?
AI: I'm doing great, thanks for asking! I'm feeling very excited about the new projects I'm working on. How about you?
Human: I'm doing well, thank you. I need your assistant.
AI:
> Finished chain.
' Sure thing! What kind of assistance do you need?'
ConversationBufferMemory allows conversations to grow with each turn and allows users to see the entire conversation history at any time. This approach allows ongoing interactions to be monitored and maintained, providing a simple but powerful form of memory for language models, especially in scenarios where the number of interactions with the system is limited.
print(conversation.memory.buffer)
Output:
Human: Hey! I am Nhi.
AI: Hi Nhi! My name is AI. It's nice to meet you. What can I do for you today?
Human: How are you today?
AI: I'm doing great, thanks for asking! I'm feeling very excited about the new projects I'm working on. How about you?
Human: I'm doing well, thank you. I need your assistant.
AI: Sure thing! What kind of assistance do you need?
Use Comet LLM to complete the code and record relevant information for analysis purposes.
def conversation_memory_buffer(prompt):
with get_openai_callback() as cb:
start_time = time.time()
response = conversation.predict(input=prompt)
end_time = time.time()
print(f"Response: {response}")
print(f"History: {conversation.memory.buffer}")
# Log to comet_llm
comet_llm.log_prompt(
prompt=prompt,
output=response,
duration= end_time - start_time,
prompt_template = conversation.prompt.template,
metadata={
"memory_type": "conversation_buffer_memory",
"history": conversation.memory.buffer,
"total_tokens": cb.total_tokens,
"prompt_tokens": cb.prompt_tokens,
"completion_tokens": cb.completion_tokens,
"total_cost_usd": cb.total_cost
},
)
Call the function conversation_memory_buffer():
Example:
conversation_memory_buffer("Hey! I am Nhi.")
conversation_memory_buffer("How are you today?")
conversation_memory_buffer("I'm doing well, thank you. I need your assistant.")
How the data is logged in Comet LLM:
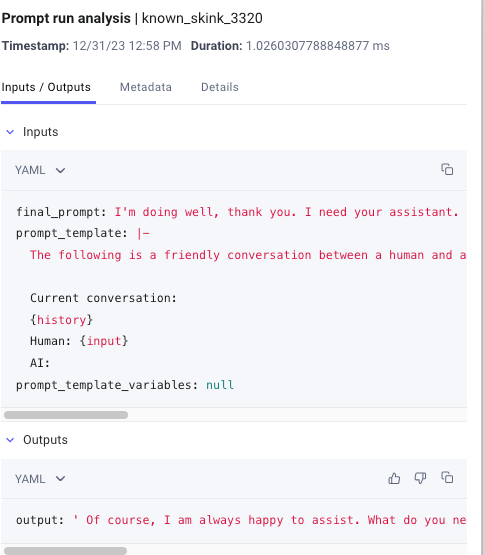
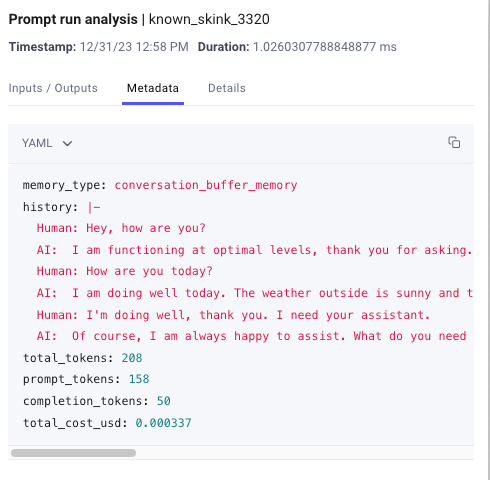
2. Conversation Summary Memory
To overcome the scalability challenge, Conversation Summary Memory provides a solution. Rather than accumulating each interaction, the model generates a condensed summary of the essence of the conversation. This reduces the number of tokens and increases the sustainability of long-term interactions.
🎯 Implementation: Summarize the conversation to save tokens.
✅ Pros: Efficient token usage over time.
❌ Cons: May lose fine-grained details; suitable for concise interactions.
from langchain.chains.conversation.memory import ConversationSummaryMemory
from langchain import OpenAI
from langchain.chains import ConversationChain
from langchain.callbacks import get_openai_callback
# Create an instance of the OpenAI class with specified parameters
llm = OpenAI(openai_api_key=MY_OPENAI_KEY,
temperature=0,
max_tokens = 256)
# Create an instance of the ConversationSummaryMemory class
summary_memory = ConversationSummaryMemory(llm=OpenAI(openai_api_key=MY_OPENAI_KEY))
# Create an instance of the ConversationChain class, combining OpenAI, verbose mode, and memory
conversation = ConversationChain(
llm=llm,
verbose=True,
memory=summary_memory
)
Similar to ConversationBufferMemory, we’ll also interact with the conversational agent bot by inputting each prompt in conversation.predict(). Example:
conversation.predict(input="Hey! I am Nhi.")
conversation.predict(input="How are you today?")
Output:
> Entering new ConversationChain chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
Nhi introduces themselves to the AI and the AI responds with a greeting, revealing its name to be AI. The AI offers to assist Nhi with any tasks and asks how it can help them today. The human then asks how the AI is doing, to which it responds that it is doing great and asks how it can be of assistance.
Human: I'm doing well, thank you. I need your assistant.
AI:
> Finished chain.
' Absolutely! How can I help you today?'
The ConversationSummaryMemory generates the conversation summary over multiple interactions.
Current conversation:
Nhi introduces themselves to the AI and the AI responds with a greeting, revealing its name to be AI. The AI offers to assist Nhi with any tasks and asks how it can help them today. The human then asks how the AI is doing, to which it responds that it is doing great and asks how it can be of assistance.
The summaries capture key points of the conversation, including introductions, queries, and responses. As the conversation progresses, the model generates summarized versions, emphasizing that it tends to use fewer tokens over time. The summary’s ability is to retain essential information, making it useful for reviewing the conversation as a whole.
Additionally, we can access and print out the conversation summary.
print(conversation.memory.buffer)
Output:
Nhi introduces themselves to the AI and the AI responds with a greeting, revealing its name to be AI. The AI offers to assist Nhi with any tasks and asks how it can help them today. The human asks how the AI is doing, to which it responds that it is doing great and asks how it can be of assistance. The human informs the AI that they need its assistance and the AI eagerly offers to help.
Use Comet LLM to log important information for analysis purposes in your code.
def conversation_summary_memory(prompt):
with get_openai_callback() as cb:
start_time = time.time()
response = conversation.predict(input=prompt)
end_time = time.time()
print(f"Response: {response}")
print(f"History: {conversation.memory.buffer}")
# Log to comet_llm
comet_llm.log_prompt(
prompt=prompt,
output=response,
duration= end_time - start_time,
prompt_template = conversation.prompt.template,
metadata={
"memory_type": "conversation_summary_memory",
"history": conversation.memory.buffer,
"total_tokens": cb.total_tokens,
"prompt_tokens": cb.prompt_tokens,
"completion_tokens": cb.completion_tokens,
"total_cost_usd": cb.total_cost
},
)
Call the function conversation_memory_buffer():
Example:
conversation_summary_memory("Hey! I am Nhi.")
conversation_summary_memory("How are you today?")
conversation_summary_memory("I'm doing well, thank you. I need your assistant.")
3. Conversation Buffer Window Memory
Conversation Buffer Window Memory is an alternative version of the conversation buffer approach, which involves setting a limit on the number of interactions considered within a memory buffer. This balances memory depth and token efficiency, and provides flexibility to adapt to conversation windows.
🎯 Implementation: Retain the last N interactions.
✅ Pros: Balances memory and token constraints.
❌ Cons: Potential loss of early conversation context.
from langchain.chains.conversation.memory import ConversationBufferWindowMemory
from langchain import OpenAI
from langchain.chains import ConversationChain
from langchain.callbacks import get_openai_callback
# Create an instance of the OpenAI class with specified parameters
llm = OpenAI(openai_api_key=MY_OPENAI_KEY,
model_name='text-davinci-003',
temperature=0,
max_tokens = 256)
# Create an instance of the ConversationBufferWindowMemory class
# We set a low k=2, to only keep the last 2 interactions in memory
window_memory = ConversationBufferWindowMemory(k=2)
# Create an instance of the ConversationChain class, combining OpenAI, verbose mode, and memory
conversation = ConversationChain(
llm=llm,
verbose=True,
memory=window_memory
)
Note that in this demo we will set a low value k=2 , but you can adjust it depending on the memory depth you need. Four prompts are introduced into the model in the following order:
conversation.predict(input="Hey! I am Nhi.")
conversation.predict(input="I'm doing well, thank you. I need your assistant.")
conversation.predict(input="I bought this pair of jeans, and there's a problem.")
conversation.predict(input="When I tried them on, the zipper got stuck, and now I can't unzip it.")
In the demo, the prompt contains an ongoing conversation, and the model tracks a set number of recent interactions. However, only the last 02 interactions are considered, so the previous interactions are not preserved.
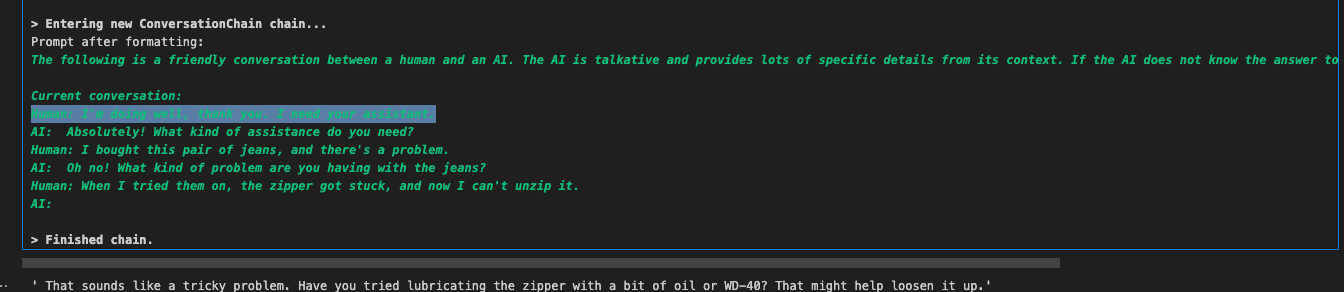
Memory depth can be adjusted based on factors such as token usage and cost considerations. We compare our approach with previous approaches and emphasize selectively preserving recent interactions.
print(conversation.memory.buffer)
Output:
Human: I bought this pair of jeans, and there's a problem.
AI: Oh no! What kind of problem are you having with the jeans?
Human: When I tried them on, the zipper got stuck, and now I can't unzip it.
AI: That sounds like a tricky problem. Have you tried lubricating the zipper with a bit of oil or WD-40? That might help loosen it up.
Use Comet LLM to log important information for analysis in your code:
def conversation_buffer_window_memory(prompt):
with get_openai_callback() as cb:
start_time = time.time()
response = conversation.predict(input=prompt)
end_time = time.time()
print(f"Response: {response}")
print(f"History: {conversation.memory.buffer}")
# Log to comet_llm
comet_llm.log_prompt(
prompt=prompt,
output=response,
duration= end_time - start_time,
prompt_template = conversation.prompt.template,
metadata={
"memory_type": "conversation_buffer_window_memory",
"history": conversation.memory.buffer,
"total_tokens": cb.total_tokens,
"prompt_tokens": cb.prompt_tokens,
"completion_tokens": cb.completion_tokens,
"total_cost_usd": cb.total_cost
},
)
Call the function conversation_buffer_window_memory():
Example:
conversation_buffer_window_memory("Hey! I am Nhi.")
conversation_buffer_window_memory("How are you today?")
conversation_buffer_window_memory("I'm doing well, thank you. I need your assistant.")
4. Conversation Summary Buffer Memory: A Combination of Conversation Summary and Buffer Memory
Conversation Summary Buffer Memory keeps a buffer of recent interactions in memory, but compiles them into a digest and uses both, rather than just removing old interactions completely.
🎯 Implementation: Merge summary and buffer for optimal memory usage.
✅ Pros: Provides a comprehensive view of recent and summarized interactions.
❌ Cons: Requires careful tuning for specific use cases.
from langchain.chains.conversation.memory import ConversationSummaryBufferMemory
from langchain import OpenAI
from langchain.chains import ConversationChain
from langchain.callbacks import get_openai_callback
# Create an instance of the OpenAI class with specified parameters
llm = OpenAI(openai_api_key=MY_OPENAI_KEY,
temperature=0,
max_tokens = 512)
# Create an instance of the ConversationSummaryBufferMemory class
# Setting k=2: Retains only the last 2 interactions in memory.
# max_token_limit=40: Requires the installation of transformers.
summary_buffer_memory = ConversationSummaryBufferMemory(llm=OpenAI(openai_api_key=MY_OPENAI_KEY), max_token_limit=40)
# Create an instance of the ConversationChain class, combining OpenAI, verbose mode, and memory
conversation = ConversationChain(
llm=llm,
memory=summary_buffer_memory,
verbose=True
)
Feed the model with 4 prompts in an order:
conversation.predict(input="Hey! I am Nhi.")
conversation.predict(input="I bought this pair of jeans, and there's a problem.")
conversation.predict(input="When I tried them on, the zipper got stuck, and now I can't unzip it.")
conversation.predict(input="It seems to be a problem with the zipper.")
The model retains the last 2 interactions and summarize the older ones as below:
> Entering new ConversationChain chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
System:
Nhi introduces herself to the AI, and the AI responds by introducing itself and expressing pleasure in meeting Nhi. Nhi mentions a problem with a pair of jeans she bought, and the AI asks for more details. Nhi explains that the zipper got stuck and now she can't unzip it.
AI: That sounds like a tricky situation. Have you tried lubricating the zipper with a bit of oil or soap? That might help it move more smoothly.
Human: It seems to be a problem with the zipper.
AI:
> Finished chain.
' It sounds like the zipper is stuck. Have you tried lubricating it with a bit of oil or soap? That might help it move more smoothly.'
Print out the result:
print(conversation.memory.moving_summary_buffer)
Output:
Nhi introduces themselves to the AI and the AI responds by introducing itself and offering assistance. Nhi explains a problem with a pair of jeans they bought, stating that the zipper is stuck and they can't unzip it. The AI suggests lubricating the zipper with oil or soap to help it move more smoothly or replacing it if that doesn't work.
Use Comet LLM in your code to log important information for analysis:
def conversation_summary_buffer_memory(prompt):
with get_openai_callback() as cb:
start_time = time.time()
response = conversation.predict(input=prompt)
end_time = time.time()
print(f"Response: {response}")
print(f"History: {conversation.memory.moving_summary_buffer}")
# Log to comet_llm
comet_llm.log_prompt(
prompt=prompt,
output=response,
duration= end_time - start_time,
prompt_template = conversation.prompt.template,
metadata={
"memory_type": "conversation_summary_buffer_memory",
"history": conversation.memory.moving_summary_buffer,
"total_tokens": cb.total_tokens,
"prompt_tokens": cb.prompt_tokens,
"completion_tokens": cb.completion_tokens,
"total_cost_usd": cb.total_cost
},
)
Call the function conversation_summary_buffer_memory():
Example:
conversation_summary_buffer_memory("Hey! I am Nhi.")
conversation_summary_buffer_memory("I bought this pair of jeans, and there's a problem.")
conversation_summary_buffer_memory("When I tried them on, the zipper got stuck, and now I can't unzip it.")
conversation_summary_buffer_memory("It seems to be a problem with the zipper.")
5. Conversation Knowledge Graph Memory
LangChain goes beyond just conversation tracking and introduces knowledge graph memory. It builds a mini knowledge graph based on related information, creating nodes and connections to represent key entities. This method improves the model’s ability to understand and respond to situations.
🎯 Implementation: Extract relevant information and construct a knowledge graph.
✅ Pros: Enables structured information extraction.
❌ Cons: May require additional processing for complex scenarios.
Python Code example:
from langchain.chains.conversation.memory import ConversationKGMemory
from langchain import OpenAI
from langchain.chains import ConversationChain
from langchain.prompts.prompt import PromptTemplate
from langchain.callbacks import get_openai_callback
# Create an instance of the OpenAI class with specified parameters
llm = OpenAI(openai_api_key=MY_OPENAI_KEY,
temperature=0,
max_tokens = 256)
# Define a template for conversation prompts
template = """
This is a friendly chat between a human and an AI. The AI shares details from its context. \n
If it doesn't know the answer, it honestly admits it. The AI sticks to information in the 'Relevant Information' section and doesn't make things up. \n\n
Relevant Information: \n
{history}
Conversation: \n
Human: {input} \n
AI:"""
# Create an instance of the PromptTemplate class with specified input variables and template
prompt = PromptTemplate(input_variables=["history", "input"], template=template)
# Create an instance of the ConversationKGMemory class with the OpenAI instance
kg_memory = ConversationKGMemory(llm=llm)
# Create an instance of the ConversationChain class, combining OpenAI, verbose mode, prompt, and memory
conversation = ConversationChain(
llm=llm,
verbose=True,
prompt=prompt,
memory=kg_memory
)
def conversation_kg_memory(prompt):
with get_openai_callback() as cb:
start_time = time.time()
response = conversation.predict(input=prompt)
end_time = time.time()
print(f"Response: {response}")
print(f"History: {str(conversation.memory.kg.get_triples())}")
# Log to comet_llm
comet_llm.log_prompt(
prompt=prompt,
output=response,
duration= end_time - start_time,
prompt_template = conversation.prompt.template,
metadata={
"memory_type": "conversation_kg_memory",
"history": str(conversation.memory.kg.get_triples()),
"total_tokens": cb.total_tokens,
"prompt_tokens": cb.prompt_tokens,
"completion_tokens": cb.completion_tokens,
"total_cost_usd": cb.total_cost
},
)
6. Entity Memory
Similar to Knowledge Graph memory, entity memory extracts specific entities from the conversation, such as names, objects, or locations. This focused approach aids in understanding and responding to user queries with greater precision.
🎯 Implementation: Identify and store specific entities from the conversation.
✅ Pros: Facilitates extraction of key information for decision-making.
❌ Cons: Sensitivity to entity recognition accuracy.
from langchain import OpenAI, ConversationChain
from langchain.chains.conversation.memory import ConversationEntityMemory
from langchain.chains.conversation.prompt import ENTITY_MEMORY_CONVERSATION_TEMPLATE
from pydantic import BaseModel
from typing import List, Dict, Any
from langchain.callbacks import get_openai_callback
# Print the template used for conversation prompts
ENTITY_MEMORY_CONVERSATION_TEMPLATE.template
print(ENTITY_MEMORY_CONVERSATION_TEMPLATE.template)
# Create an instance of the OpenAI class with specified parameters
llm = OpenAI(openai_api_key=MY_OPENAI_KEY,
temperature=0,
max_tokens = 256)
# Create an instance of the ConversationEntityMemory class with the OpenAI instance
entity_memory = ConversationEntityMemory(llm=llm)
# Create an instance of the ConversationChain class, combining OpenAI, verbose mode, prompt, and memory
conversation = ConversationChain(
llm=llm,
verbose=True,
prompt=ENTITY_MEMORY_CONVERSATION_TEMPLATE,
memory=entity_memory
)
Create a function to get the response and log important metadata using CometLLM:
def conversation_entity_memory(prompt):
with get_openai_callback() as cb:
start_time = time.time()
response = conversation.predict(input=prompt)
end_time = time.time()
print(f"Response: {response}")
print(f"History: {conversation.memory.entity_store.store}")
# Log to comet_llm
comet_llm.log_prompt(
prompt=prompt,
output=response,
duration= end_time - start_time,
prompt_template = conversation.prompt.template,
metadata={
"memory_type": "conversation_entity_memory",
"entity_cache": conversation.memory.entity_cache,
"history": conversation.memory.entity_store.store,
"total_tokens": cb.total_tokens,
"prompt_tokens": cb.prompt_tokens,
"completion_tokens": cb.completion_tokens,
"total_cost_usd": cb.total_cost
},
)
Call the function:
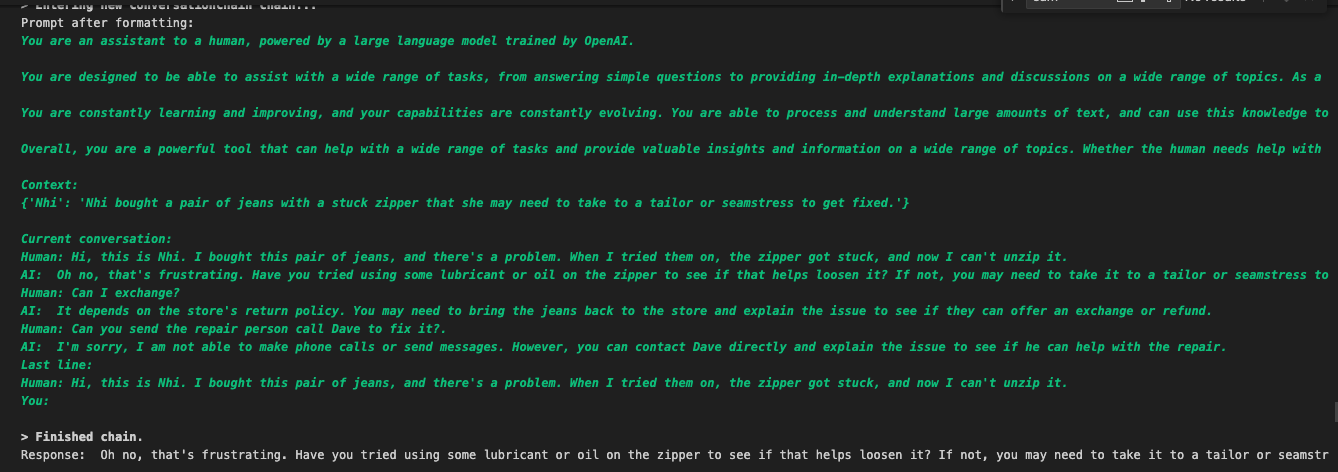
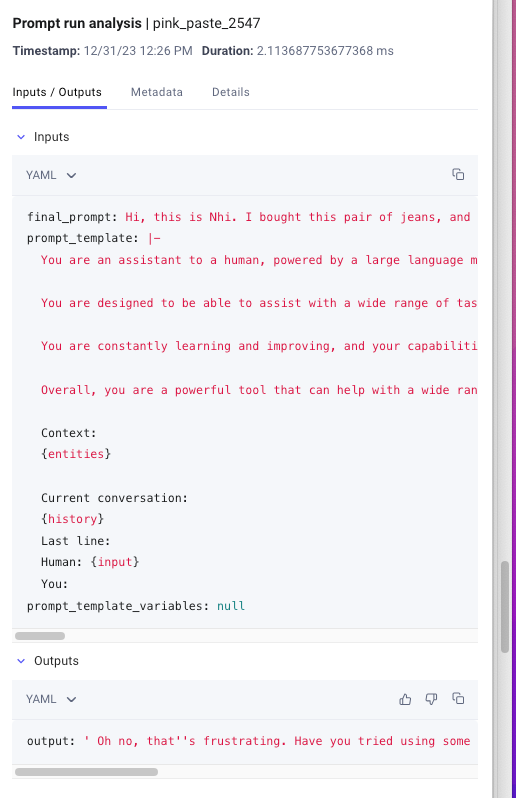
conversation_entity_memory("Hi, this is Nhi. I bought this pair of jeans, and there's a problem. When I tried them on, the zipper got stuck, and now I can't unzip it.")
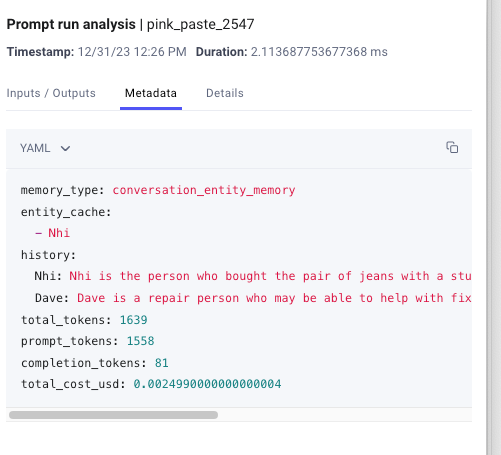
The function returns the history, the matching response using Entity memory, and also logs metadata in Comet LLM as shown below.
Reference
- Find the complete code on this GitHub repository
- Experiment Tracking in Comet LLM Project
👉 Explore Comet in action by reviewing my past hands-on projects.
- Enhancing Customer Churn Prediction with Continuous Experiment Tracking
- Hyperparameter Tuning in Machine Learning: A Key to Optimize Model Performance
- The Magic of Model Stacking: Boosting Machine Learning Performance
- Logging — The Effective Management of Machine Learning Systems
Conclusion
Memory plays a fundamental role in enhancing the capabilities of conversational agents. By understanding and implementing LangChain’s different memory strategies, you can create more dynamic and context-sensitive chatbots. Whether you choose a buffer-based approach or leverage a knowledge graph, the key is to tailor your memory mechanisms to your specific use case and user expectations.
As the field of Natural Language Processing (NLP) continues to evolve, integrating memory into conversational agents remains a promising avenue for improving user experience.
