Deep learning-based video summarization — A detailed exploration

With the immense growth of videos on the internet, it’s become really difficult to efficiently search amongst millions of them. When searching for an event query, users are often bewildered by the vast quantity of videos returned by search engines like Google. Exploring such results can be time-consuming and can also degrade the user experience. Hence, we’ll be discussing ways to automate this process with deep learning video summarization techniques.

The Definition of Video Summarization
“Video summarization is the process of distilling a raw video into a more compact form without losing much information.”
— Definition taken from the research paper “Video Summarization via Semantic Attended Networks” by Shanghai Jiao Tong University
Video summarization helps users to navigate through a large sequence of videos and retrieve ones that are most relevant to the query.
In a general video summarization system, image features of video frames are extracted, and then the most representative frames are selected through analyzing the visual variations among visual features.
This is done either by taking a holistic view of the entire video or by identifying the local differentiation among the adjacent frames. Most of those attempts rely on global features such as color, texture, motion information, etc. Clustering techniques are also used for summarization.
Video summarization can be categorized into two forms:
- Static video summarization (keyframing) and
- Dynamic video summarization (video skimming)
Static video summaries are composed of a set of keyframes extracted from the original video, while dynamic video summaries are composed of a set of shots and are produced taking into account the similarity or domain-specific relationships among all video shots.
One advantage of a video skim over a keyframe set is the ability to include audio and motion elements that potentially enhance both the expressiveness and the amount of information conveyed by the summary. In addition, it’s often more entertaining and interesting to watch a skim than a slide show of keyframes.
On the other hand, keyframe sets are not restricted by any timing or synchronization issues, and therefore, they offer much more flexibility in terms of organization for browsing and navigation purposes, in comparison to a strict sequential display of video skims.
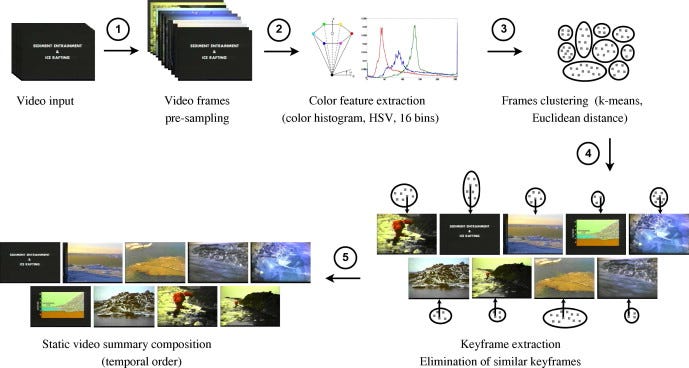
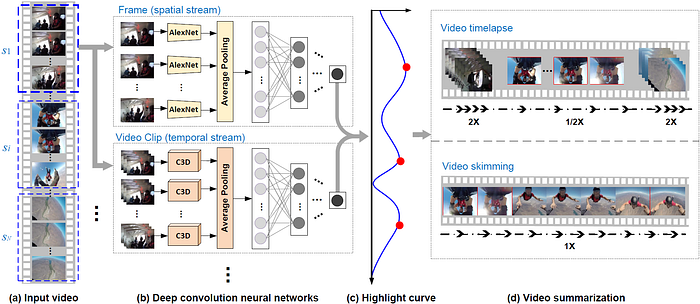
Video Summarization Techniques
Feature-Based Video Summarization
The digital video contains many features like color, motion, voice, etc. These techniques work well if a user wants to focus on the features of the video. For example, if a user wants to see color features, then it’s good to pick color-based video summarization techniques.
Feature-based video summarization techniques are classified on the basis of motion, color, dynamic contents, gesture, audio-visual, speech transcripts, objects, etc.
If you want to know more about this technique, click here.
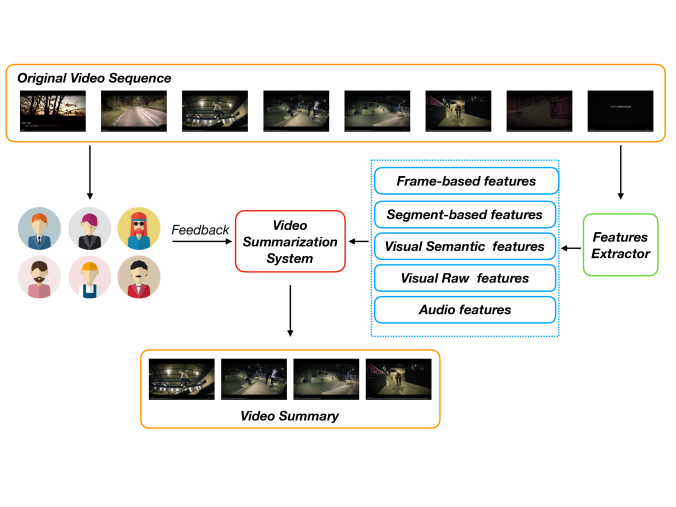
Video Summarization Using Clustering
Clustering is the most frequently used technique when we encounter similar characteristics or activities within a frame. It also helps to eliminate those frames that have irregular trends. Other methods for video summarization enable a more efficient way of browsing video but also create summaries that are either too long or confusing. Video summarization based on clustering is classified into similar activities, K-means, partitioned clustering, and spectral clustering.
If you want to know more about this technique, click here.

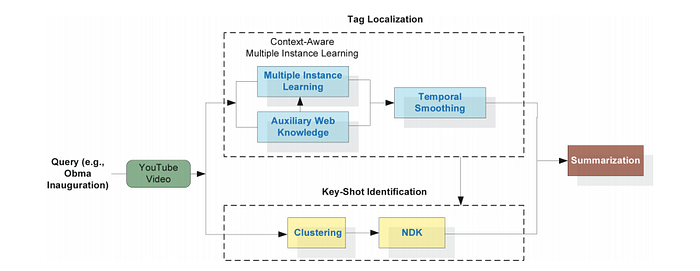
Tag Localization and Key-Shot Identification Approach
Millions of videos are available on the web with rich metadata, such as titles, comments, and tags. Therefore, recent efforts have been put into searching or exploring the tag information of web videos.
Specifically, there’s a scheme that enriches YouTube videos’ tag information by exploring their redundancy, such as overlapping or duplicated content. They build a graph for a set of videos, and the tags from redundant videos can be propagated to the target video through the graph structures.
A bag-of-instances model is used to perform tag localization (as a note, the mathematics behind it is beyond the scope of this article). Additionally, key-shot identification is performed based on an assumption that videos usually appear multiple times in search results.
Therefore, this kind of identification can be accomplished by near-duplicate detection, i.e. performing near-duplicate detection using the keyframe pairs extracted from different web videos. Since near-duplicate keyframes usually have a small difference, the clustering-based method can be used to speed up the key-shot identification process.
If you want to know more about this technique, click here.
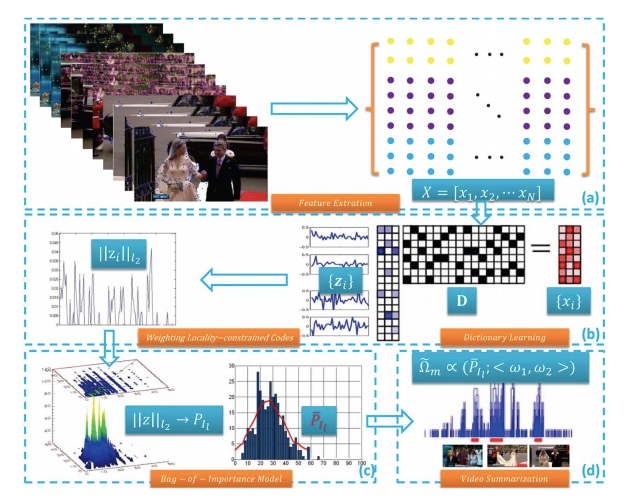
Bag-of-Importance Model
A video can be viewed as a collection of weighted features instead of equally-important ones. The BoI model provides a mechanism to exploit both inter-frame and intra-frame properties by quantifying the importance of the individual features representing the whole video.
The representative frames hence can be identified by aggregating the weighted features. It’s very reasonable to assume that a video sequence in its raw feature space is a dense manifold. In order to remove redundant visual features, a video sequence needs to be projected to a low-dimensional sparse space. The locality-constrained linear coding method provides such a mechanism, which can take advantage of the manifold geometric structure to learn a nonlinear function in a high dimensional space/manifold, and locally embed the points on the manifold in a lower-dimensional space, expressed as the coordinates with respect to a set of anchor points.
More about this topic is discussed in the given paper.
Conclusion
These techniques are just the start of a new era in deep learning technology when it comes to video summarization. Many advances will be made in the near future to create and optimize the best summaries based on the audience, delivery medium, and intent of summarization. Together, with efforts across the industry, we’ll make video summarization highly-scalable, reliable, and incredibly efficient.
Related Articles