
Lack of large-scale labeled datasets is a severely limiting factor in training Deep Learning algorithms for Computer Vision. With the performance of CV models depending largely on how representative of real world scenarios the data points are, insufficient and incomplete data are often one of the largest limitations in extending AI to new domains and new use-cases.
To a certain extent, data limitation issues can be addressed with the help of Data Augmentation, a process which entails the use of image processing-based algorithms to distort data within certain limits and increase the number of data points available. Augmentation is often necessary not only to increase the dataset size, but also to help the model generalize to images it has not seen before.
When it comes to implementation, the most popular augmentation methods are those that include simple transformations. These include methods like Rotations, Image Shifts, and Horizontal and Vertical flips. To discuss how these transformations affect the dataset quality and how the deep learning model responds to them, we first need to understand some properties of CNNs that make these transforms imperative — even when the data is ample in quantity.
Translational Equivariance and Translational Invariance
- Translational Equivariance:
A convolutional layer works by sliding an n x nkernel along the input image, from left to right and top to bottom, to form latent representations which are further processed using more convolutional blocks in deeper layers of the network. The sliding window operation allows the CNN to recognize spatial correlations and patterns and grants it an important property: translational equivariance. Translational equivariance says that when we shift the input by a corresponding amount, their latent space representations must shift accordingly. This is achieved through parameter sharing as the same kernel slides through the input image and the shift in the input is reflected in a corresponding shift in the latent space representation. While CNNs on one end are able to identify objects irrespective of their location, parameter sharing further enables them to identify multiple instances of an object in the same image as the same kernel is applied multiple times. A diagrammatic representation of translational equivariance is shown below:

2. Translational Invariance:
Translational invariance, though often confused with translational equivariance is a property that convolutional layers do not possess. Translational invariance implies that the output from the CNN remains the same irrespective of any translational shift that the input goes through. What this effectively means is that if the object in the input is placed in a different location than it was in the training data, the CNN should still be able to detect and locate the object flawlessly. To achieve translational invariance, CNNs make use of pooling layers alternating with convolutional blocks. Pooling layers like max-pooling and average pooling are able to identify locations where neurons spike and filter out those representations as necessary in the final output. CNNs equipped with a max-pooling layer can thus detect objects that have undergone significant translational shift, as the relative location of the object in the image doesn’t influence the corresponding output any more.
The discussion of these CNN properties make it clear that a CNN can learn representations irrespective of their position in the image. Although CNNs are translation invariant and equivariant, they do not possess rotational or scale invariance. This means that if a network is presented with an image of an object that has been rotated or scaled in a manner it has not seen before, it may not be able to properly identify the object. Similar issues arise when the image undergoes color tone transformations. This has some serious consequences for the robustness of the CNN, and can make it inapplicable to real life scenarios in which color transformations and rotations are abundant.
Want to see the evolution of AI-generated art projects? Visit our public project to see time-lapses, experiment evolutions, and more!
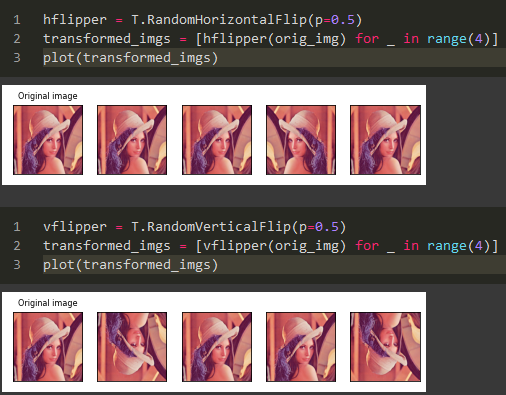
Random Horizontal Flip / Random Vertical Flip: Random flip, as the name implies, flips the image randomly based on a certain probability (default probability is 0.5).
Color Jitter: Color jitter randomly alters the brightness and saturation of an image.

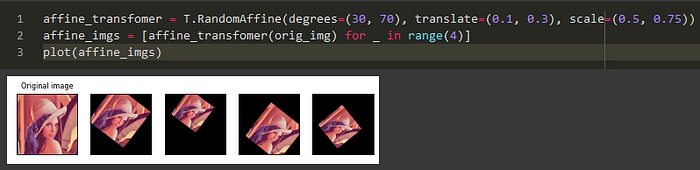
Random Affine Transform: Random affine transform performs random transformations that preserve the lines and parallelism of the image. Affine transforms include translation and scale.
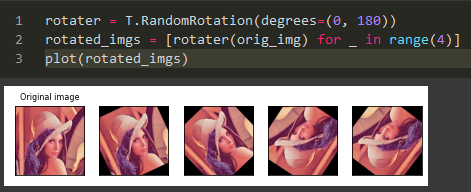
Random Rotation: Random Rotation rotates the image with the upper and lower limit for rotation (which are defined with parameters).
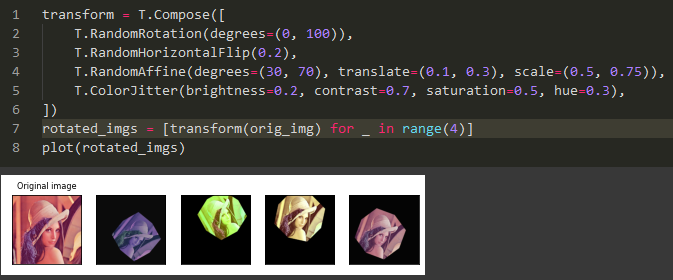
All of these methods can be combined and implemented with the Composemodule of torchvision. The entire transform block can be written as:
The code from this section is available as a Colab notebook here. Feel free to tinker with it to get a better idea of the different transform modules and their use. For more information, visit https://pytorch.org/vision/stable/auto_examples/plot_transforms.html from where most of the code is taken.
