I decided to write a series of blogs on current topics: the elements of data governance that I have been thinking about, reading, and following for a while. Even though the titles are new, the ideas are not really new. They are formed by taking advantage of different sciences and mainly consist of new usage patterns focused on strengthening agility and scalability.

What is the Data Fabric?
Data Fabric is an approach to working with data in globally consistent ways.
Let’s try to understand the main reason behind the saying “fabric” with the help of an analogy. Let’s keep in mind that the fabric of the universe in physics is essentially and globally consistent. Now let’s continue…
According to the data fabric approach;
- Data: It should be treated as an asset developed, tested, and made available to users or other teams within the organization, just like software products. I will define this later as the “Data Product.”
- Data should have an independent team responsible for its creation, delivery, and sustainability. This team should consist of experts who know the business domain where the data comes from and should be something other than general-purpose Information and Communication Technologies (ICT) teams.
- Data should be designed to be easily accessed, discovered, and consumed by other teams or users without requiring significant support or intervention from the team that created it.
- Data should be created using standardized data models, definitions, and quality requirements. It must be rigorously tested to ensure quality, reliability, and interoperability.
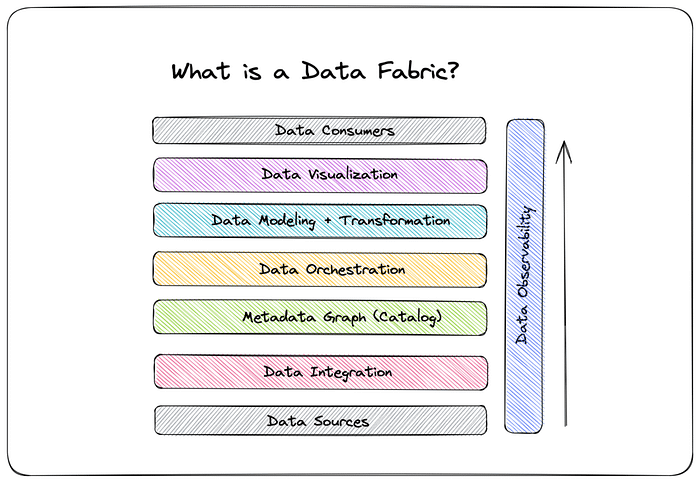
Data fabric initially needs data sources like any other known data management architecture. This data source may be related to the sales sector, the manufacturing industry, finance, health, and R&D… Briefly, I am talking about a field-specific data source. The domain of the data.
Regardless, the data fabric must be consistent for all its components. A consistent data source, consistent integration, consistent metadata/catalog, consistent orchestration… This is the essence of the data fabric. Just as we call the “factory of the universe,” the smallest consistent unit. This smallest unit is an atom for some and a smaller one for others. Data fabric for us: The smallest unit of globally consistent data management in itself is its essence.
This global consistency must be ensured for each data source separately. This is where the novelty of this approach comes from.
Data fabric is a self-consistent approach in which the organization follows a central data management strategy that covers all sub-data sources and can benefit from tools and methods determined according to the needs of the data source. Data fabric needs metadata management maturity.
With its data fabric approach, Jaguar Land Rover has made the interconnected view of supply and demand data efficient in solving critical business challenges.
Advantages:
- Consistency ensures trust in data governance.
- It facilitates and encourages data reuse.
- Thanks to this simplified approach, it reduces complexity, and fewer tools are needed.
Disadvantages:
- Lack of agility: It can challenge some teams where all team members have to adopt the whole process in the same way to ensure consistency.
- Weak innovation: With a small number of tools specified, it may give different success for the entire data fabric, making it challenging to innovate.
Treating data fabric as centralized data management across an organization may not be beneficial. So, let’s examine what a new concept, data mesh, is.
Data mesh allows us to continue to benefit from advantages such as consistency while solving the disadvantages of the data fabric.
What is Data Mesh?
Data Mesh is a new data set that enables units or cross-functional teams to decentralize and manage their data domains while collaborating to maintain data quality and consistency across the organization — architecture and governance approach.
We can call fabric texture or actual fabric. So think about your clothes!

Yes, you are still reading an article about data governance. Are your clothes all made of the same fabric? No, they each have different fabrics, weaves, and textures. Even an outfit can have more than one fabric and weave. The harmony of textures and colors achieves its good looks, and as a whole, if you like it, invest in it and wear it. Depending on the season, different fabrics are better for you. We need one fabric for financial data, another for logistics data, a different fabric for automotive manufacturing data, and a different fabric for health data. We cannot spend an entire year in an outfit made of one type of fabric. It is from this approach that data mesh is born. If you connect your data fabric, which you developed with the tools you have separately planned for this sectoral data, with a network, you will make a patchwork of a piece of fabric. Sewing between fabrics, a mesh!
Data mesh changes the scope of the data fabric. It continues to provide consistency for each sectoral data fabric and says that if each patchwork fabric is consistent within itself, it will be harmonious and consistent in all our sewing.
The math says it, too. In other words, we eliminate data fabric’s agility and innovation deficiency with data mesh while going from local to proper global consistency. This approach is very similar to the microservice architecture in software. On the other hand, it is becoming the most effective way to ensure interoperability. In this case, the formation of data silos is prevented, and we provide the most efficient and fast use of decentralized, federated, and simultaneous interoperability with data mesh. How does it? Let’s continue by understanding the four basic principles.
Data mesh as a concept was first introduced by Zhamak Dehghani in 2019 and is shaped by four fundamental principles.
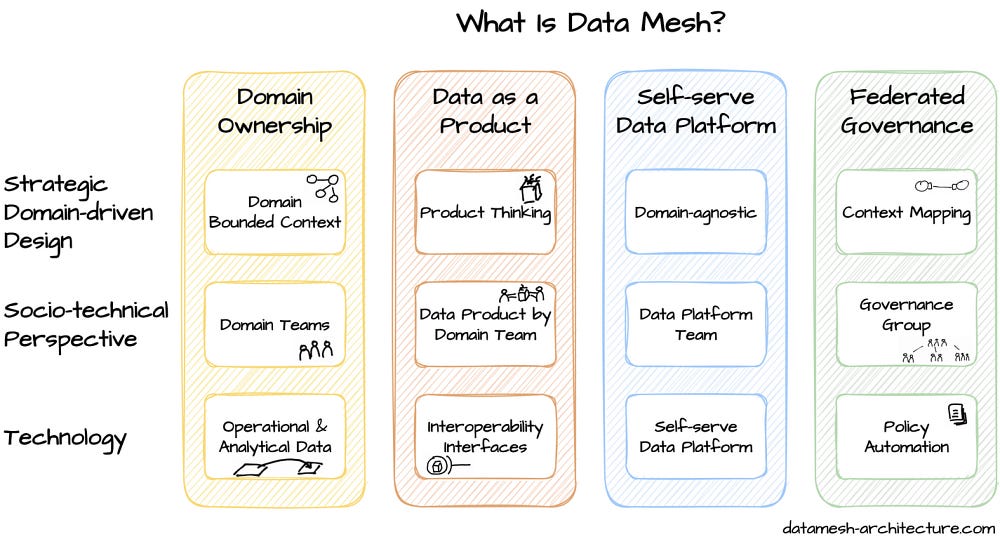
🔘 Domain Ownership
- Autonomy: Each domain has sovereignty over its data, and the domain can make decisions about how the data is collected, stored, processed, and shared. These decisions should, of course, comply with the organization’s general data mesh policies and guidelines.
- Accountability: Domain owners are responsible and accountable for the quality, security, and consistency of their data products.
- Scalability: It should allow teams to quickly adapt to changing business needs.
- Integration: Domain owners need to work together to ensure that their data products integrate well with each other and meet the overall organizational strategy and needs.
🔘 Data as a Product
- Value: Like software products, data is treated as a valuable asset developed, tested, and made available to users (other teams within the organization).
- Ownership and Responsibility: Every data product has a dedicated team responsible for creating, maintaining, and making it available to its users.
- Self-Service: Data products should be designed to be easily discovered and consumed by users without needing significant support or intervention from the team that created them.
- Quality and Consistency: Data products must be built using standardized data models, definitions, and requirements and rigorously tested to ensure quality, reliability, and interoperability.
🔘 Self-Service Data Platform
- Data Product Catalogue: The self-service data platform should typically include a data product catalog listing all available data products produced by different teams in the organization.
- Data Access and Governance: Self-service data platforms must provide a way for teams to access and consume data products without needing a central data office.
- Collaboration: Self-service data platforms should facilitate collaboration and knowledge sharing across different teams and domains.
- Data Product Lifecycle Management: A self-service data platform should provide tools and processes to manage the lifecycle of data products, including versioning, deployment, and retirement.
🔘 Distributed / Federated Governance
- Federated Governance: Federated Computational Governance should ensure that each team has the autonomy to make decisions about data within its domain while adhering to overall corporate governance policies.
- Distributed Trust: Data mesh should leverage distributed trust to ensure the integrity and accuracy of data.
- Collaborative Decision-Making: Decision-making in the data mesh environment should be collaborative and consensus-based.
- Continuous Improvement: Federated Computational Governance should support continuous improvement by providing a feedback loop for teams to learn from each other and adapt governance policies and procedures over time.
When we place the four basic principles and the elements of these principles into the data mesh architecture, we obtain a mechanism as follows. Data mesh needs governance maturity rather than metadata maturity. I plan to cover each component of the data mesh mechanism one by one in another article.
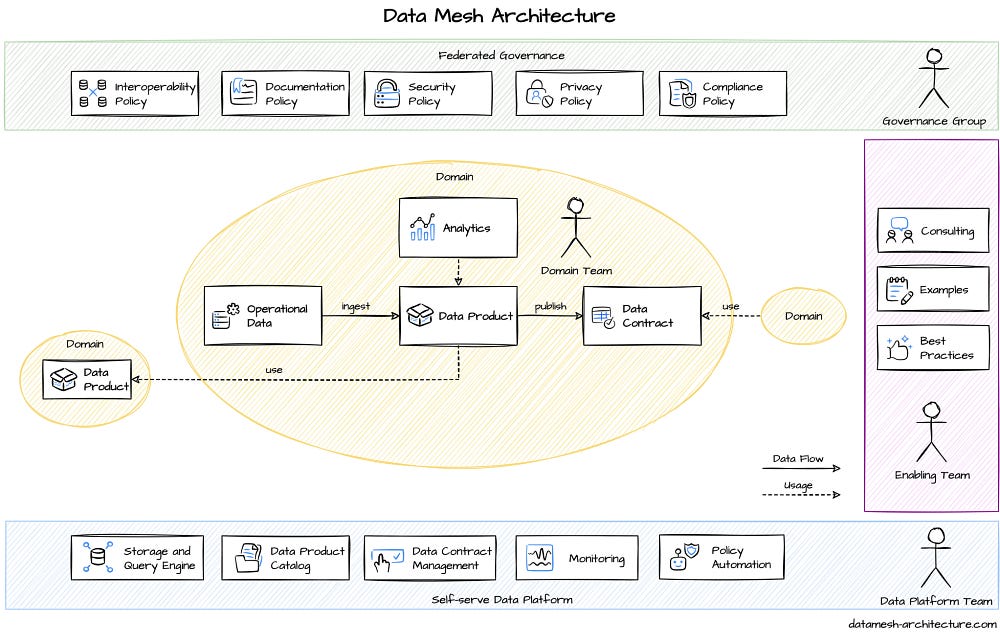
What Challenges Does Data Mesh Solve and How?

Limits of Data Mesh
- Complexity: Data Mesh adds complexity to the data infrastructure if the desired organization needs to be more significant. It can be beneficial if it is a large organization where different data types and domains are managed.
Netflix, Dominos, Ducati, and J.P. Morgan can be examined as an example of organizations that implement data mesh.
- Tools: Data Mesh encourages data sharing and collaboration between teams. Teams can use their own data systems but must adopt the mindset of sharing information, for example, using APIs.
- Governance: It presents a challenge as each domain team is responsible for the quality and consistency of their data.
- Cultural Change: For a successful data mesh implementation, teams must make a significant cultural shift in how data is owned and shared.
- Capability: Data Mesh creates the need for technical expertise in all organizational domains, which increases the demand for competent personnel.
I had the chance to attend the “Data and Analytics Summit” organized by Gartner on May 22–24, 2023. One hundred twenty (120) sessions were held at this event, run only by Gartner experts.
This summit consisted of conferences, workshops, roundtable events, ask-an-expert sessions, one-on-one meetings, bake-off meetings, and fair sections in general. I had the opportunity to follow all sessions related to Data Fabric and Data Mesh in a hectic schedule. Here, I am sharing some information I have gained on the subject. Let’s start with Gartner’s famous HypeCycle. Data mesh is just beginning to become hype, and data fabric is a little closer to the plateau. The required maturity for both has been cut to 5–10 years.
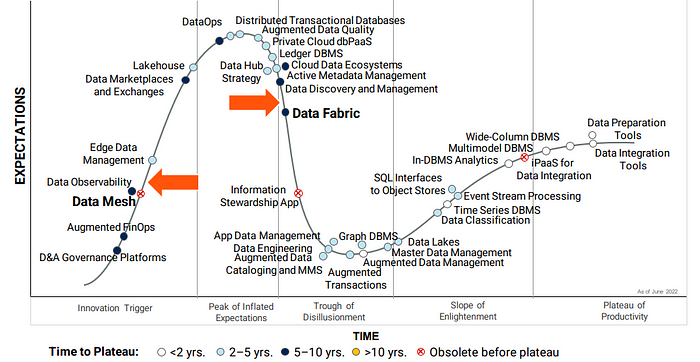
Which Data Management Architecture Should You Choose?
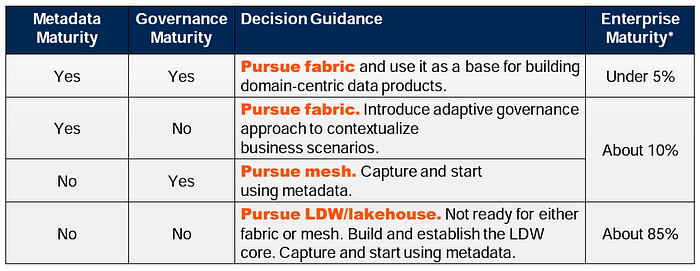
On the other hand, Gartner experts present a weighting matrix based on their research on which approach you should choose for your organization. If you are hearing these concepts for the first time, you do not need to be afraid; as you can see, the rate of organizations that can implement this is relatively low. The Enterprise Maturity indicator is based on more than 1,400 Gartner customer interactions in 2022. Your organization’s preparation level: Upgrading in the context of metadata and governance maturity will make a significant contribution.
Conclusion
In conclusion, data mesh and data fabric offer different advantages and disadvantages, and choosing the right approach for your organization depends on several factors, such as organizational structure and culture, technical maturity, and data governance and security requirements.
While the data mesh approach emphasizes decentralized data ownership and management, data fabric advocates a centralized data platform to ensure data quality, consistency, and security.
It may be advisable to conduct pilot projects to assess suitability to select the best approach.
Ultimately, the best approach will align with your organization’s goals, resources, and strategic direction and provide users with relevant data and insights to make data-driven decisions. In addition, it should give flexibility to use advanced analytical and artificial intelligence approaches.
So, with what tools can we apply these governance approaches? Keep following my future content.
Feel free to follow me on GitHub and Twitter accounts for more content!
Check out some other blog posts:
