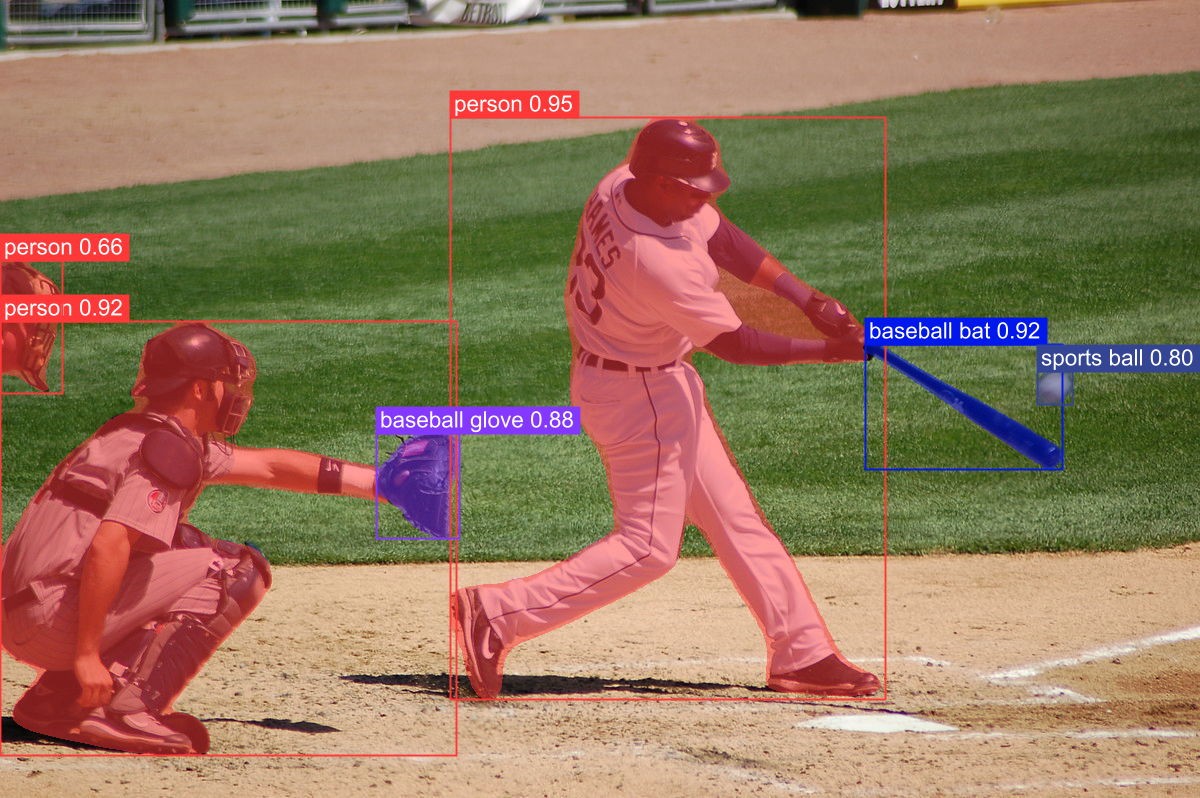
Object detection example asset from the YOLOv8 open-source computer vision library
Leveraging machine learning for computer vision use cases has revolutionized a myriad of industries by enabling machines to interpret and respond to visual data. From enhancing medical diagnostics with precise imaging techniques to powering autonomous vehicles with real-time object detection and navigation, the applications of computer vision models are vast and diverse.
Building state-of-the-art CV models for your specific use case can be daunting task. Luckily, the open source community has been creating a plethora of developer-friendly libraries that make it very easy to start training a model on your custom dataset. Here’s a list of 5 open-source computer vision repositories to familiarize yourself with!
Anomalib
Anomaly detection has an inherent data imbalance problem: the number of anomamalus data points are generally outweighed by the normal data points. This makes it incredibly easy to train a biased model that outputs “no anomaly” and is deemed right 98% of the time. Anomalib takes this data imbalance into account and offers 8+ models/algorithims for users to benchmark on any given dataset. Anomalib can be used for simple classification use cases or to train models that segment where in the image the anomalies occur.
Ultralytics
Object detection is the most popular use case for vision-based machine learning models. The Ultralytics repo implements the powerful YOLOv8 model for object detection but also extends its capabilities to object tracking, instance segmentation, image classification, and pose estimation tasks. This library also makes it really easy to fine-tune YOLOv8 for any use case on your custom data.
Pythae
Autoencoders take high-dimensional inputs, like an image, and learn how to encode it to a much smaller latent space. These powerful models are used for many different applications: image denoising, image inpainting, super-resolution, and feature extraction. Pythae implements over 15 different autoencoders for users to train on their own data.
Albumentations
Augmenting your image data with transformations helps improve the generalizability of computer vision models. Albumentations implements more than 70 image transformations including blurring, cropping, and modifying brightness. Users have the ability specify the frequency they want a specific image transformation to occur when they are defining their image augmentation pipeline.
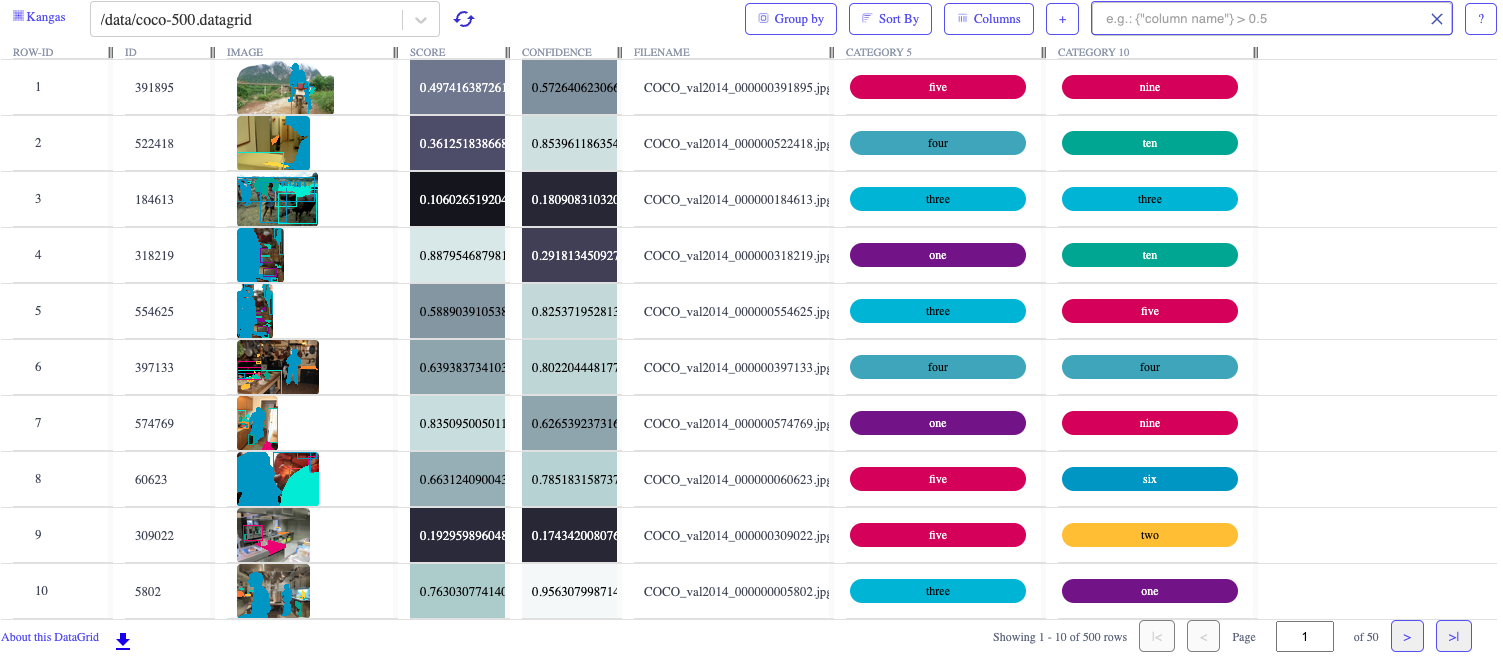
Kangas
Pandas is a great tool for performing exploratory data analysis (EDA) on tabular datasets. Kangas extends Pandas capabilities to multimedia datasets. Use Kangas to create DataGrids (akin to Pandas Dataframes) that log your datasets and use it to debug your model’s predictions at the sample level.
Track, Compare, & Visualize Your CV Model Training Runs for Free
These five open-source computer vision libraries provide powerful foundation to start training CV models for your specific use case. But when it comes to actively training and iterating on a model, sharing results with your team, and achieving production-ready reproducibility, there’s more work to be done from a machine learning operations standpoint.
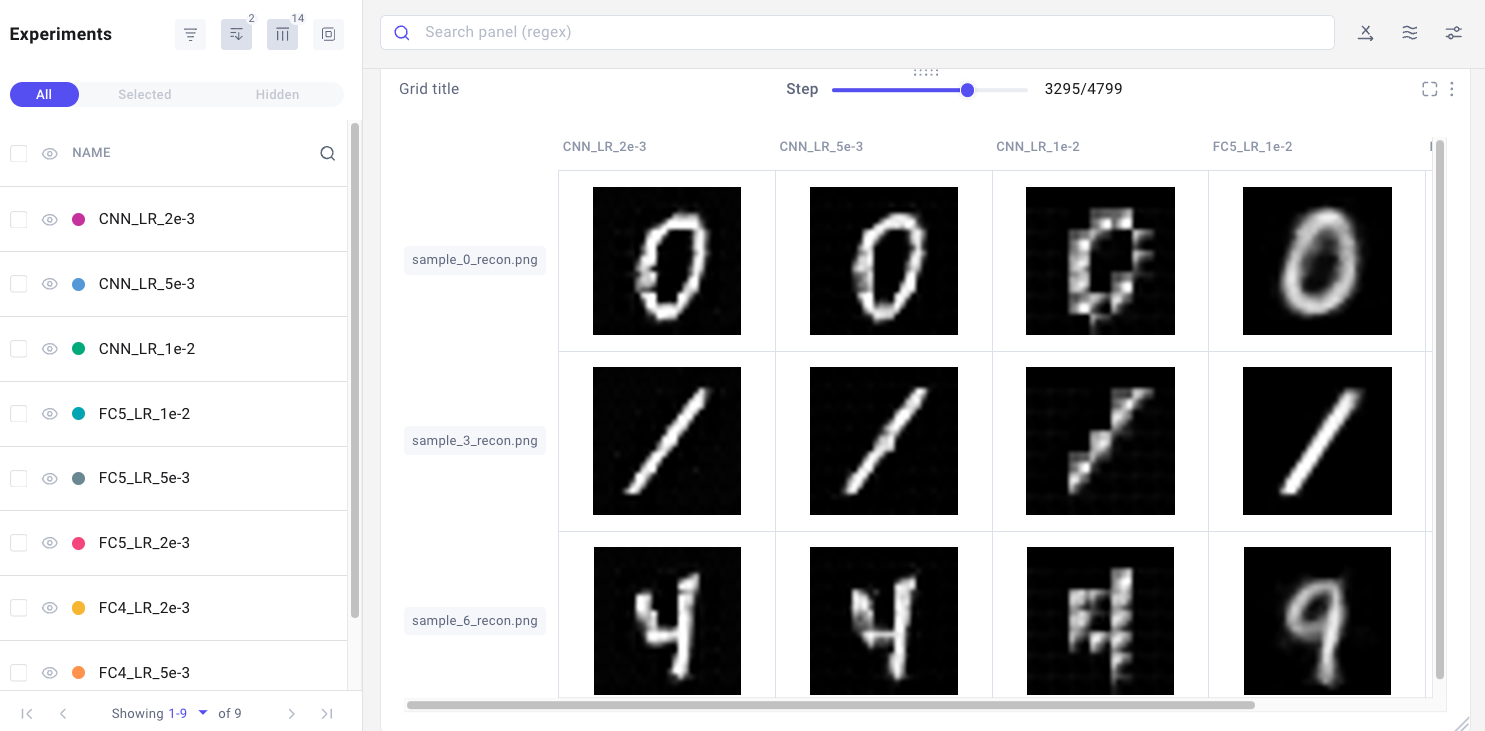
Comet’s MLOps platform allows you to track, debug, compare, visualize, and reproduce your model training runs. Comet is free to try, and free forever for individuals and academics, making it a perfect pairing for the open source CV libraries above. Check out the example below of how a CV Project might be tracked in Comet, and try Comet for free today.
Example of computer vision experiment tracking with Comet
ML Growth Engineer @ Comet. Interested in Computer Vision, Robotics, and Reinforcement Learning
We use cookies to collect statistical usage information about our website and its visitors and ensure we give you the best experience on our website. Please refer to our Privacy Policy to learn more.




{kind=link}