LLM Evaluation Complexities for Non-Latin Languages
Large language models (LLMs) have revolutionized natural language processing, yet most development and evaluation efforts have historically centered around Latin-script languages. When these models are extended to non-Latin alphabets, especially Chinese, Japanese, and Korean (CJK), challenges emerge that span linguistic structure, cultural context, and technical implementation.
This article offers a deep dive into these challenges and the innovations that have led to the non-English language comprehension in models like Cohere’s Aya and Deepseek’s R1.
We will explore:
- Character-Level Challenges: Tokenization without spaces, word compounding complexities, character decomposition.
- Language-Level Challenges: Masking strategies, pre-training tweaks, and architectural adaptations in CJK-optimized models.
- Cultural-Level Challenges: Limitations of traditional metrics, plus the emergence of new benchmarks and evaluation frameworks tailored to CJK.
When we examine models and approaches across these three lenses, we can see why “lifting and shifting” English-trained models or evaluation pipelines does not yield the same success in CJK languages.
I. Character-Level Challenges
Language Model Challenges in CJK (Character-Level Focus)
Evaluating language models with non-Latin-based languages is harder than it looks. CJK languages differ drastically from English in both writing systems and linguistic structures, complicating how we train and assess models. Below are a few of the key character-level hurdles:
- Lack of Clear Word Boundaries
In Chinese and Japanese, written text lacks the spaces that clearly separate words in English. This means a model or tokenizer can’t rely on white spaces alone. Korean does have spaces, but each “word” can have many parts due to its agglutinative nature and mixed scripts. - Vast Character Sets
Chinese has thousands of unique characters (Hanzi). Japanese mixes three scripts (Kanji, Hiragana, Katakana). Korean uses Hangul blocks. A language model must handle a very large and often unseen vocabulary. This leads to potential out-of-vocabulary issues and raises concerns about encoding efficiency. - Word Compounding Complexity
CJK languages regularly form new words by compounding existing ones, creating meanings that individual parts may not predict on their own. For instance, Chinese 父母 (parents, made of “father + mother”) or Japanese place names like 北海道 can be split into multiple characters whose individual meanings differ significantly. Traditional tokenization might lose these word-level contexts. - English-Centric Metrics
Many current evaluation benchmarks and metrics (perplexity, BLEU, etc.) were originally developed for English or other Latin-script languages. For CJK, differences in tokenization can distort results, making direct comparisons or perplexity measurements misleading. - Lack of Historical Benchmarks
As new benchmarks are emerging, we can compare models more effectively. But historically, there’s been no consistent way to measure progress for CJK languages. This gap makes it hard to say whether newer models truly improve over older ones on CJK text.
Collectively, these complexities mean you can’t just take an English-trained model or pipeline and apply it to Chinese, Japanese, or Korean expecting on-par performance. Below, we dive deeper into how to tokenize these languages; an essential task complicated by the unique structure of each script.
How to Tokenize Without Spaces
For language models, text must be broken down into smaller parts or discrete units called “tokens.” In English, tokenization often means splitting text by whitespace and punctuation to get words or subwords. But in Chinese and Japanese, there are no spaces between words. Meanwhile, Korean’s spacing doesn’t necessarily denote all linguistic boundaries.
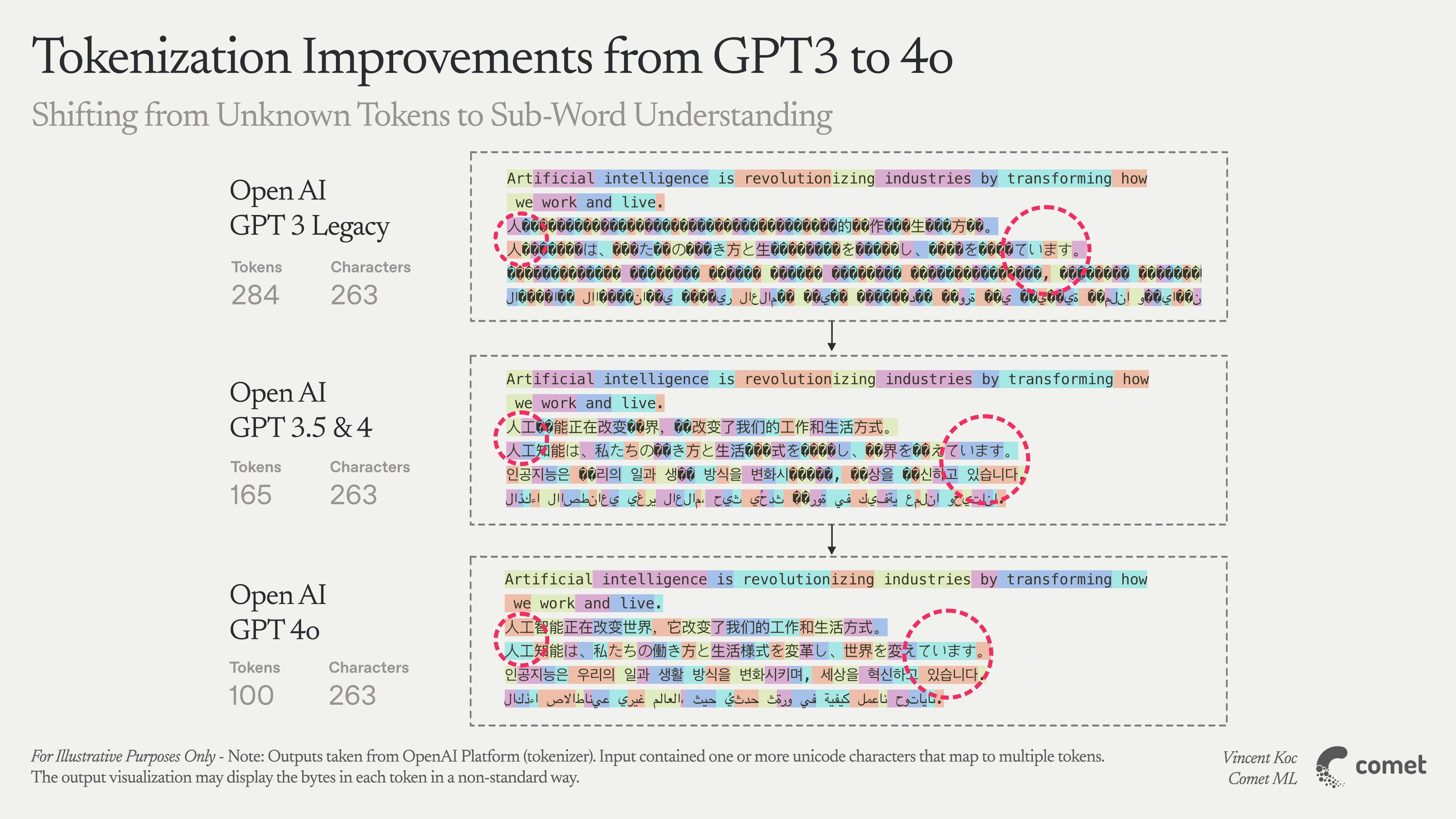
Tokenizing Chinese
A simplified approach is to treat each character as its own token. The original BERT model did this for Chinese, avoiding ambiguous word boundaries. Since each Hanzi is a lowest-level unit, the out-of-vocabulary issue is sidestepped because every character already exists in the vocab.
Yet this can break meaningful multi-character words. For example, the two-character word “手机” (“shouji” meaning cellphone) is split into “手” (hand) and “机” (machine). While this avoids unknown tokens, it loses the combined meaning of “cellphone.” Hence, researchers have explored machine-learning-based or dictionary-based segmentation, or hybrid approaches. No single method is universally agreed upon; ongoing research examines which method or combination yields the best downstream results.
Tokenizing Japanese
Japanese text mixes Kanji (Chinese-origin characters) and Kana (syllabic scripts: Hiragana, Katakana). Kanji characters often carry meaning, while Kana might serve grammatical roles or transliterations of foreign words, all concatenated without spaces.
Algorithmic tools like MeCab or Juman++ analyze the text to segment words before tokenization. Consider “北海道” (Hokkaido). If you split it naively:
- 北 (Hoku/Kita): “north”
- 海 (Kai/Umi): “sea/ocean”
- 道 (Dō/Michi): “road/way”
This breaks the unified meaning of Hokkaido as a place name. Therefore, many advanced Japanese BERT models use these morphological analyzers to keep compound words intact, followed by subword tokenization.
Tokenizing Korean
Hangul is written in syllable blocks (e.g., 한 is ㅎ + ㅏ + ㄴ). Although spaces separate words in modern Korean, each word can contain additional grammatical particles or agglutinative suffixes.
To handle this, Korean models often first separate morphemes (root words vs. endings) before subword tokenization. For instance, “학교에” (“to school”) might be split into “학교” (school) + “에” (to). KoNLPy provides analyzers like Mecab-ko (inspired by MeCab for Japanese) to automate these steps. This two-level approach preserves intended meanings and avoids confusion.
Because each language’s tokenization approach can differ widely, it also affects evaluation. A model that splits text differently from another might show different perplexity or BLEU scores, even on the same data. Thus, beyond re-tooling tokenization for CJK languages, researchers are also exploring further techniques like character decomposition to capture the internal structure of each written character.
Role of Character Decomposition
One unique aspect of CJK languages (relative to English) is that individual characters themselves can carry internal structure and meaning. Chinese or Japanese characters (Kanji) may be composed of smaller radicals that hint at meaning or pronunciation, while Korean syllables are composed of letters indicating sounds. Teaching an LLM about these sub-character structures can significantly aid performance.
Why decompose characters?
By breaking characters into radicals or strokes, a model can learn relationships between characters. For instance, a radical like “氵” often indicates something related to water. So if a model sees “氵” in characters like 河 (river), 海 (sea), or 湖 (lake), it can generalize even if it hasn’t seen that exact character before. Similarly, for Korean, decomposing syllables into jamo letters (ㅎ,ㅏ,ㄴ) can help with rare syllable blocks.
- Chinese Example: 明 (“bright”) can be split into 日 (sun) + 月 (moon). 林 (“forest”) is literally two trees (木) side by side.
- Japanese Example: 休 (“rest”) is 亻 (person radical) next to 木 (tree), conveying the idea of “a person leaning against a tree to rest.”
- Korean Example: 한 (han) is composed of ㅎ(h) + ㅏ(a) + ㄴ(n). Some models treat each letter as a token, which can increase sequence lengths but offers better coverage for OOV syllables.
Researchers incorporate these decomposition signals into models by adding radical embeddings, stroke information, or sub-character tokens. Methods like GlyphBERT show that fusing radical or stroke details into a model’s embedding layer can significantly boost Chinese NLP performance. The biggest gain is in handling out-of-vocabulary characters: a naive model might simply mark an unseen character as “[UNK],” whereas a decomposition-aware model can glean partial meaning from sub-components.
II. Language-Level Challenges
Masking Strategies and Pre-Training
Modern language models like BERT rely heavily on masked language modeling, where tokens in a sentence are masked out for the model to predict. For CJK languages, how these tokens are masked is crucial.
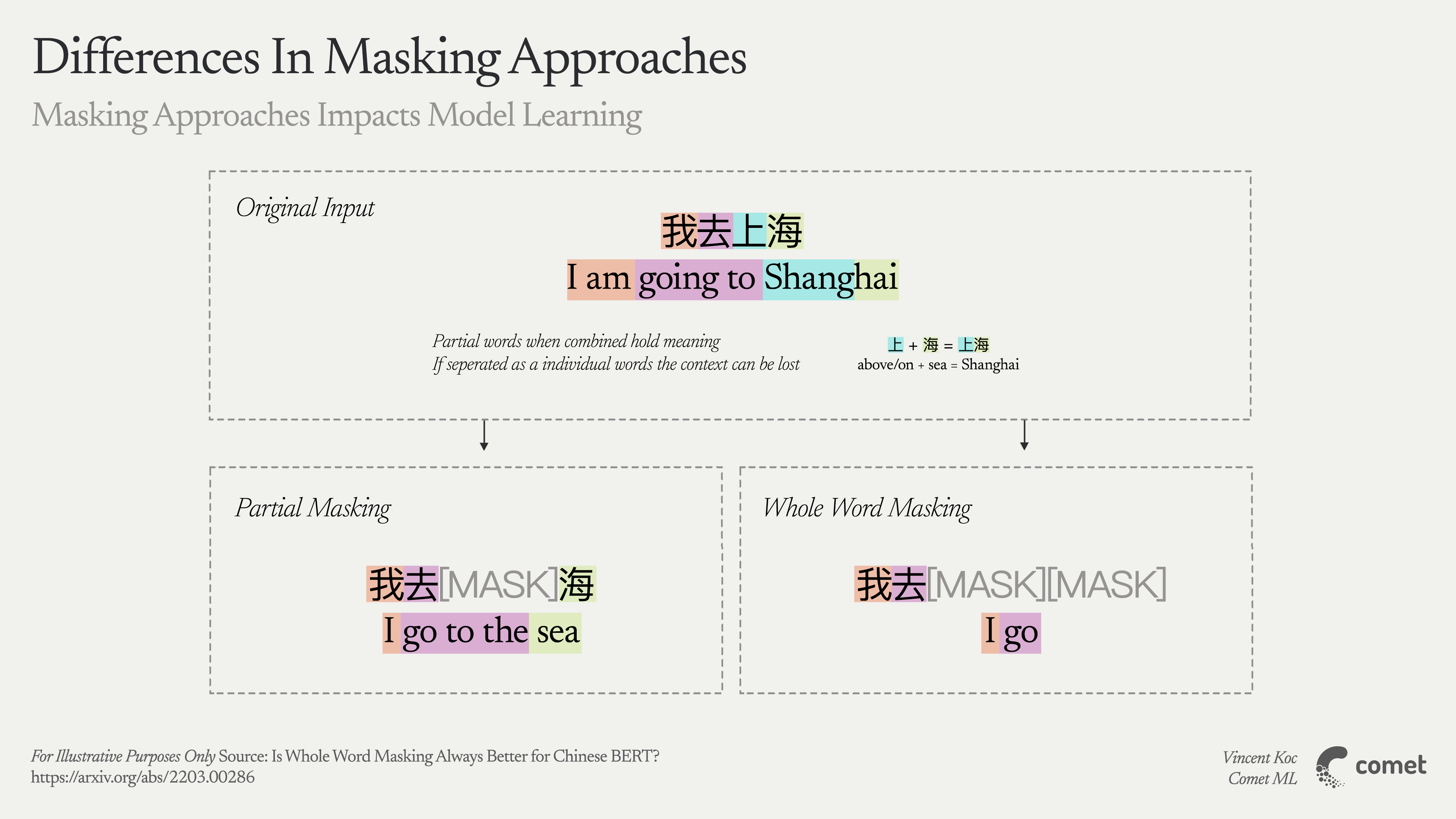
- Random Character Masking: If each Chinese character is a token, standard BERT might randomly mask a single character in a multi-character word. This can make it too easy for the model to guess based on partial context (e.g., in “美国,” if only “美” is masked, “国” still suggests a country).
- Whole Word Masking (WWM): Mask the entire word at once. For Chinese, that often means running a segmentation step first, then ensuring if “美国” is chosen for masking, both characters (“美” and “国”) are masked together. This yields better performance on word-level tasks like NER or machine reading comprehension.
- Phrase & Entity Masking: ERNIE (from Baidu) extended masking to entire phrases or named entities, pushing the model to learn higher-level semantics.
- Masked Segment Prediction: Lattice-BERT (discussed in next section) used a lattice structure to mask words at both character and word-level spans.
- Cross-Script Masking (Hypothetical): In Japanese, one could mask the Kanji but leave Kana context, or vice versa, to force the model to link meaning to pronunciation. This idea highlights the creative ways to encourage script-bridging, though it’s not yet standard. A similar approach can be seen with the approach in programming languages for code based models.
The key insight is that masking can’t just be a copy-paste from English. Whole word masking, phrase masking, and other refinements ensure a model captures deeper semantics rather than memorizing partial clues.
Tuning the Model Architecture
While the fundamental Transformer architecture in BERT/GPT is language-agnostic, small architectural tweaks can help with CJK’s unique structure. Beyond simply training separate monolingual models, researchers have devised methods to handle multiple levels of granularity in parallel.
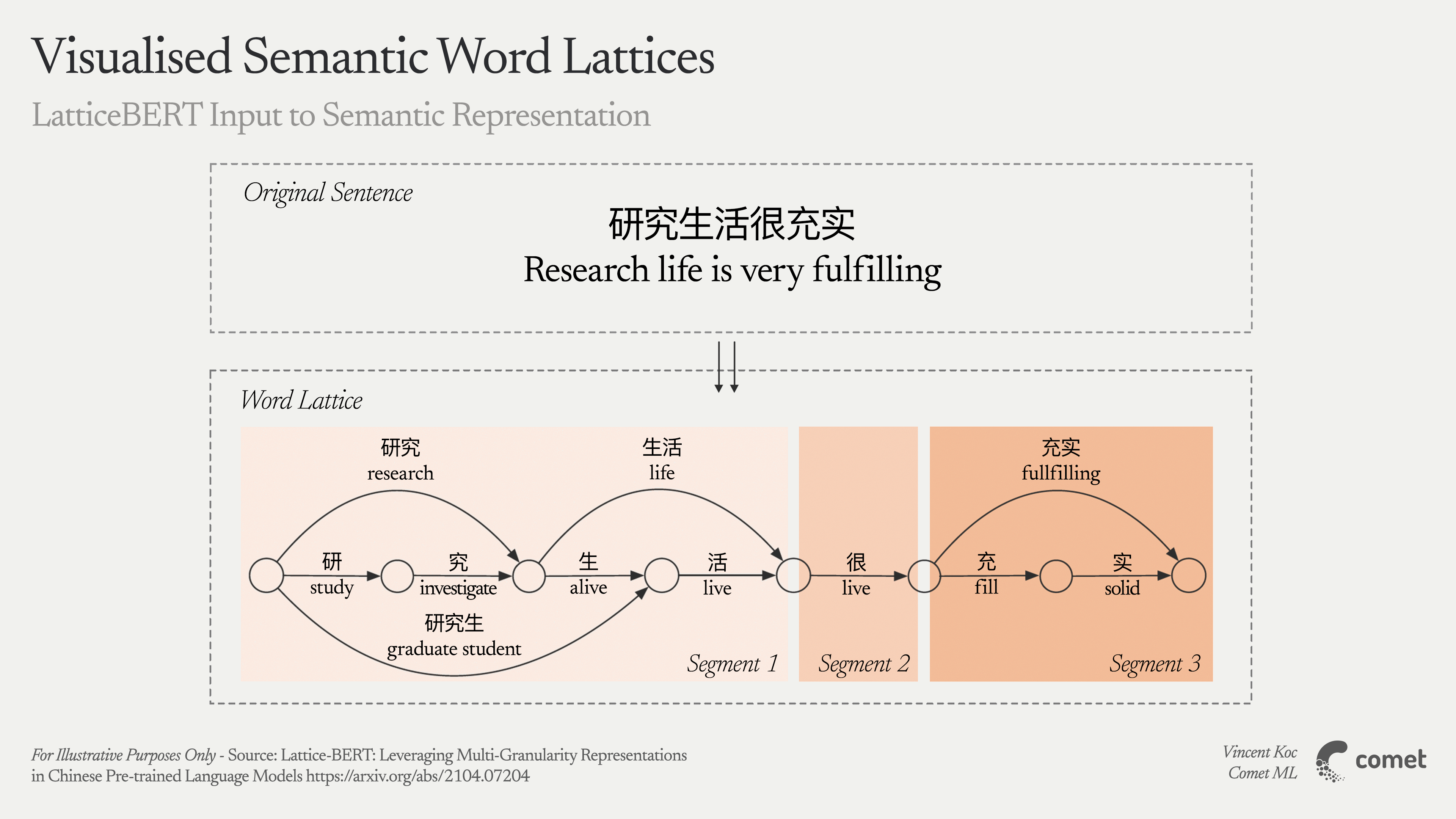
- Lattice-BERT
Instead of feeding a linear sequence of tokens, Lattice-BERT constructs a lattice structure: characters form the backbone while multi-character words are added as extra nodes spanning those characters. Its self-attention mechanism is modified to attend not only sequentially (character to next character) but also along entire word spans. This approach achieved state-of-the-art results on the Chinese CLUE benchmark. - Similar Ideas for Korean or Japanese
In principle, one could design a version that also incorporates morphological segments or subwords for Hangul (Korean) or a mix of Kanji-Kana tokens (Japanese), letting the model see multiple layers of textual granularity.
Such specialized architectures often yield major gains in understanding the unique attributes of CJK languages, illustrating how “standard” Transformers can be adapted for deeper insights.
III. Cultural-Level Challenges
Limitations of Traditional Evaluation Metrics
Applying existing NLP metrics from English to Chinese, Japanese, or Korean can mislead or fail to capture important linguistic nuances:
- Word Overlap-Based Metrics
For translation or summarization, BLEU and ROUGE rely on overlapping words/n-grams. In CJK, a “word” may not be clearly defined by spacing. Two valid translations could tokenize a sentence differently, leading to artificially low BLEU. Some researchers use chrF (character n-gram F-score) to circumvent tokenization issues, though it’s still imperfect. - Perplexity
Widely used for language model evaluation, perplexity depends on the tokenization scheme. A character-based Chinese model vs. a subword-based English model can have drastically different token counts, making cross-language perplexity comparisons meaningless. Even for two Chinese models, one with whole-word tokens and another with single-character tokens, perplexity might not correlate to real performance differences. - Human Evaluation Challenges
For tasks like translation or summarization, human evaluation is the gold standard. However, CJK languages can be tricky: different evaluators may segment the text differently. If they’re not equally fluent in the source language, judgments can vary more than in English. Setting consistent guidelines is more complex.
Because of these drawbacks, research communities have pushed for new (or adapted) metrics and frameworks to handle CJK languages better.
New Benchmarks and Evaluation Frameworks
The distinct challenges in CJK have led to new or adapted benchmarks that reflect real usage and linguistic patterns:
- Chinese: CLUE (Chinese Language Understanding Evaluation)
Like English GLUE, CLUE includes multiple tasks (sentiment, spam detection, machine reading comprehension, natural language inference, etc.). One unique addition is a test for idioms, reflecting the importance of multi-character “words” with figurative meanings. CLUE is a standard for Chinese model assessment, but others like C-SimpleQA and C-Eval are also emerging. - Japanese: JGLUE (Japanese General Language Understanding Evaluation)
Announced around 2022, JGLUE parallels the same spirit as CLUE/GLUE: a suite of text classification, natural language inference, QA, and more—sourced from native Japanese text (not translations). This ensures phenomena unique to Japanese (e.g., honorifics, script switching) are properly tested. Some additional frameworks like JHumanEval and llm-jp-eval have also been introduced. - Korean: KLUE (Korean Language Understanding Evaluation)
Includes 8 tasks such as topic classification, semantic textual similarity, named entity recognition (NER), and dialogue state tracking—reflecting Korean’s agglutinative nature. KLUE-BERT and KLUE-RoBERTa are baseline models trained with morphological pre-segmentation plus subword tokenization. These new tasks reveal how a fine-grained approach leads to better performance in real Korean usage.
Because of these benchmark efforts, progress in CJK NLP is more quantifiable. However, challenges remain, like how to evaluate models on classical Chinese, dialect translation, or advanced tasks beyond standard classification.
Conclusion
Evaluating non-English, and especially CJK languages comes with broad challenges that extend from the character level up through language-level modeling decisions and ultimately to cultural-level benchmarks and metrics. From how we tokenize (character-by-character, word-segmentation, or radical decomposition), to how we mask and train (whole word masking, phrase masking, or specialized architectures like Lattice-BERT), every step needs to be adapted for CJK’s structural and cultural nuances.
Key Takeaways:
- Traditional Metrics Struggle
CJK languages break many assumptions of English-centric pipelines, creating pitfalls in metrics like BLEU, ROUGE, or perplexity. - Semantic-Based Evaluation
Approaches such as BERTScore or embedding-based comparisons go beyond word overlap, providing more robust assessments for complex scripts. - Cross-Lingual Benchmarks
These reveal weaknesses in multilingual models, but also highlight a model’s ability to handle deeply different writing systems. - Detailed Error Analysis
Segmentation mistakes or politeness-level inconsistencies can be more visible in CJK; advanced error analyses help pinpoint these issues. - Human Evaluation & Structured Guidelines
Crucial for ensuring quality, but also more complicated to standardize for CJK’s unique features. - Challenge Tasks
Idiom comprehension and dialect translation push models to handle out-of-vocabulary scenarios, context bridging, and real-world complexities. - Language-Specific Benchmarks
CLUE, JGLUE, KLUE, etc., ensure that these challenges are captured, but they are still evolving.
As evaluation methodologies advance, these specialized benchmarks and strategies help measure progress more effectively. It’s clear that the future lies in linguistically informed, tailored evaluation methods that capture the full depth and nuance of CJK languages.
Further Reading
Here are various resources that were used for background context and will help those looking to dig deeper into these topics:
General Language Theory & Linguistics
Tokenization & Subword Methods
Language-Specific NLP & LLMs
- ChineseBERT: Pretraining with Glyph & Pinyin arXiv:2105.09680
- Revisiting Pre-trained Models for Chinese NLP arXiv:2004.05986
- GlyphBERT & Sub-character Approaches GitHub: HITsz-TMG/GlyphBERT
- Chinese-BERT Whole Word Masking GitHub: ymcui/Chinese-BERT-wwm
- Compound Words in Chinese – The role and formation of Chinese-derived compounds
- Evaluation on ChatGPT for Chinese Language MIT Press / DINT Journal
- KoNLPy (Korean NLP Toolkit) https://konlpy.org/en/latest
- Detecting Bias in Large Language Models: Fine-tuned KcBERT arXiv:2403.10774
- A Morphological Analyzer for Japanese Nouns, Verbs and Adjectives arXiv:1410.0291
Architecture-Specific Research
- A Lattice-based Transformer Architecture (MDPI)
- Lattice-BERT arXiv:2104.07204
Multilingual & Benchmarking
- Pangea: Cross-lingual NLP Resource https://neulab.github.io/Pangea/
- ALM-Bench https://github.com/mbzuai-oryx/ALM-Bench
- Cohere Blog: Fair & Comprehensive Multilingual Benchmarking
- C-Eval: A Multi-Level Multi-Discipline Chinese Evaluation Suite for Foundation Models arXiv:2305.08322
- BLEnD: A Benchmark for LLMs on Everyday Knowledge in Diverse Cultures and Languages arXiv:2406.09948v1
- Global MMLU: Understanding and Addressing Cultural and Linguistic Biases in Multilingual Evaluation arXiv:2412.03304
Related Articles